对话明略科技:一个设计完善的机器学习平台是什么样子?
近年来,机器学习技术的发展归因于我们有极其庞大的数据用来训练算法。当企业需要落地大规模机器学习时,往往会面临很多难题,如何解决这些问题?如何系统了解大规模机器学习落地的技巧?其适用场景是什么?InfoQ 希望通过该选题解决这些问题,并推动企业在大规模机器学习方面的实践。本文,InfoQ 有幸采访到明略科技机器学习平台负责人刘喆,听他分享自己的经验和见解。
机器学习平台和 AI 中台该如何理解?
最近两年,由于中台概念的崛起,AI 中台成为了很多企业的热门选择。人工智能,按照智能化程度可分为 5 级:第一级是识别能力,通过泛在多维感知,将高质量的数据连接起来;第二级是理解能力,基于可积累的行业符号体系的智能抽取技术,构建千亿知识网络的知识图谱数据库;第三级是分析能力,通过知识图谱、暴力挖掘对知识进行多维度分析推理,打造决策模型;第四级是决策能力,建立明确的行动计划,指导行动,实现智能决策;第五级是创新能力,也就是智能的终极本质。
从识别感知到理解分析,再到决策行动、循环反馈,形成 AI 闭环。相应地,需要建设感知应用基础设施,数据中台、AI 中台、业务中台,行动系统,才能实现 AI 闭环的落地,其中数据中台、AI 中台、业务中台是核心,承担 AI 大脑的角色。
在企业的早期发展过程中,为了更好的通过人工智能为其他业务赋能,内部已经存在机器学习平台这样的角色,这种平台能力与中台能力有哪些区别呢?如何理解机器学习平台与 AI 中台的概念呢?采访中,刘喆表示,机器学习平台是服务于机器学习的全生命周期,可用于众多场景,也可被其他中台集成和调用。相对的,AI 中台主要服务于具体的业务,连接机器学习平台、业务平台以及数据中台,三方组合才能成为一个完整的支撑体系。
简单来讲,中台的本质是以业务为主,连接为副。从时间上来讲,应该是先有平台,后有中台,因为机器学习平台只是其中一个部分,还需要业务平台和数据平台接入才可以。
无论是否构建 AI 中台,机器学习平台都是必须的一环。随着企业内部业务的逐渐发展,产生的数据量越来越大,机器学习平台承担的负载越来越重,逐渐达到大规模的级别。在这个阶段,刘喆表示会出现一些特征:一是数据分散,同样的问题以前只需要找一个人就可以得到答案,如今可能需要跨多个部门进行沟通;二是拿到数据的周期变长。举例来说,以前查询网站的年访问量可能只需要敲一句 SQL,现在要拿到一个准确数值,可能要通过很多路径和方法才可以,整个周期明显变长;三是新功能上线周期变长,以前只需要几天就可以搞定的需求,如今可能需要以月或者季度为单位。出现上述特征就说明企业需要通过大规模机器学习平台来解决问题。
从技术角度来说,大规模机器学习平台的技术基础也已经逐渐成熟,比如硬件的算力比之前更加强悍,尤其近几年在 GPU、FPGA、谷歌 TPU 等高级硬件出现之后,算力提高到了一个以前想都不敢想的程度。此外,与大数据计算相关的框架也越来越多,比如曾经的 Hadoop、Spark 到如今的 Tensorflow 等,这些奠定了大规模机器学习平台的技术基础。
那么,当这一切准备就绪,企业到底如何搭建一个设计相对完善的机器学习平台呢?
一个设计完善的机器学习平台是什么样子?
一个设计完善的机器学习平台可以在 AI 应用全生命周期的开发和管理过程起到作用。具体而言,设计完善的机器学习平台具备六大能力:一是统一的存储空间,支持多数据源导入。二是 Pipeline 可视化工作流管理与执行,支持数据科学家从数据建模阶段开始的可视化管理,节省成本,快速体现数据科学家的价值;三是基于容器的计算资源分配和软件库安装,支持 TensorFlow、PyTorch 等各种框架;四是支持 GPU、TPU、CPU 框架和异构计算硬件和框架;五是模型管理,支持新手快速上手,无需通过自己实现原始算法,只需要理解算法原理就可以通过调参实现;六是 AI Serving,模型一键封装为 API,一键部署。
在刘喆看来,相对重要的部分是数据接入、开发环境、分布式训练以及模型管理,其他环节都可以慢慢加进来,但这四个是基础组件。
- 数据接入,数据是一切得以实现的前提。最简单的方式是通过上传来解决。企业内部往往会基于大数据平台,通过数据导入等方式接入。或者通过数据映射的方式,数据不需要导入,直接就可以通过外部访问;
- 开发环境,数据科学家基本对此达成了共识,都会选择类似 Jupyter 这样的工具;
- 分布式训练,类似 Tensorflow、PyTorch 等都提供一些方法可以做分布式训练;
- 模型管理,这是现在比较个性化的模块,不同的公司会有不同的实现。明略科技的模型管理是涵盖模型生成、模型部署以及更新迭代的全流程实现。
除了环节和流程上面的完善,一个设计良好的机器学习平台可以降低数据科学家和工程师之间的交流成本。在这样一个机器学习平台中,大部分工作都可以通过自动化的方式完成,比如数据接入、模型上线等环节,数据科学家则只需要专注算法和模型本身,其他的工作全部通过自动化的方式实现,几乎不需要工程师协助。
至于算法的上线效果如何评估,这与业务指标强绑定。在企业内部,算法模型上线之前,指标就已经确定好了。比如,要求判断客户性别,且准确率在 70% 以上,评估的关键在于如何快速让模型数据回流。在明略科技的设计里面是通过统一的调度方式,将新生数据回流到机器学习平台,可以做到实时评估。
明略科技的机器学习平台探索
在明略科技,由于数据科学家的队伍越来越庞大,内部对开发环境、计算资源、评估上线等基本功能的需求越来越清晰,每个人都找到一些开源项目试用,最后发现或多或少都存在一些问题,无法完美满足需求,这就有了机器学习平台的诞生诉求。
在早期的探索过程中,刘喆表示,业内并没有成型的一整套工具,大部分平台都是通过拼凑的方式来实现,这种方式带来的问题很多,比如数据可能通过人工方式导入,只能在 Jupyter 里写代码,模型上线之后的效果好不好需要逐条日志分析等等。在这个阶段,明略科技也在不停试错,通过小版本不断迭代的方式逐渐使整个平台搭建完善,整个过程用时不到一年,可以分为如下三个主要阶段:
第一阶段,开发单机版本,主要目的是先跑起来。主要问题就是兼容或者说习惯,因为数据科学家已经有了一些自己的习惯,对各个环节都有自己的理解,当时最大的痛点就是写出来的模型不能直接给业务端用,需要模型工程化,单机版本主要是解决这个问题;
第二阶段,集中解决训练开发的问题。这时候已经进入分布式训练的阶段,明略科技内部有大量计算资源,但是每个人都用单机版就不太好,所以这时候对接了集团的计算资源,然后大规模的计算资源共享,主要是接入了公司的私有云服务。
第三阶段,进行多场景适用,除了解决常用数据的训练问题,还需要接入一些场景,比如语音、图像、文本甚至图数据库,这些场景中间的核心部分是一样的,但是在数据接入、数据标注等各个阶段又不太一样,所以需要通过外围组件进行对接,做二次开发,这就需要对原来的一些组件进行重构,因为原来可能不是这样设计的。
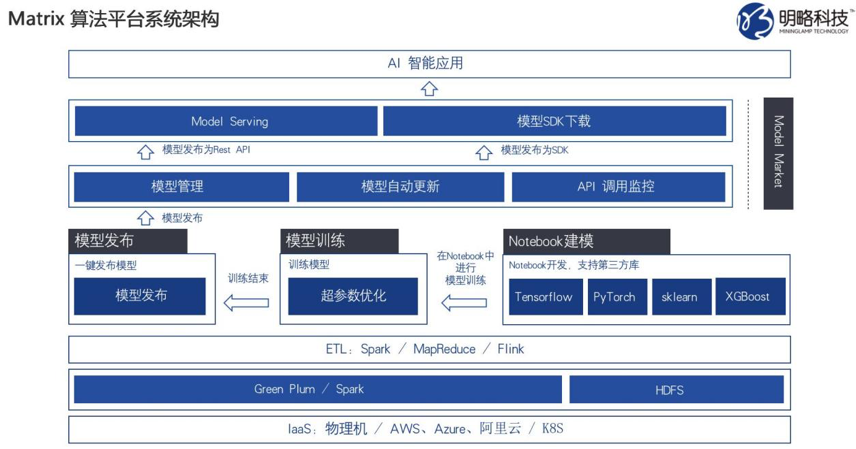
如上图,明略科技的机器学习平台具备如下特点:
第一,数据存储和计算任务分离,计算任务通过内部高速网络读写数据,避免数据再次“搬运”。
第二,ETL 集成,拖拽式任务设计,支持定时任务和事件触发,内建 Mysql、HDFS、Kafka 等多种数据源,Spark、Flink 等计算引擎。把已有的 MySQL、Kafka 与系统完美融合,以可视化方式看到各种统计。
第三,支持 Notebook 交互式开发,符合数据科学家习惯,促进业务价值。可实现 Python based 交互式场景,支持 TensorFlow Pytorch 等多使流行框架,CPU、GPU 资源控制,单机集群计算资源。这是基于原生态的 Jupyter notebook 实现,做了一些功能增强,数据科学家可以指定单机还是集成方式,快速解决实际问题,通过交互式数据开发环境,选择不同 Kernel 可连接到不同计算资源。
第四,Pipeline 的实现,Docker based 可复用,运行状态可视化,比如,A 数据科学家用的是 Tensorflow,B 数据科学家用的是 Spark,保证兼容,每次运行结果存档,生成 DAG 图,快速看到逻辑和节点问题。
第五,弹性扩展的 Model Serving,基于 k8s 和微服务技术,自主实现的服务内核,每个模型都部署一个微服务,同时支持 RESTFul 和 gRPC 协议访问,自动解决了负载均衡和 FailedOver 的问题,可自动按负载动态扩缩容 AutoScale,滚动升级和 ABtest 等多版本对比环境,支持 Java、Pyhton、C++ 等多语言部署,灵活性高。
第六,语言和框架,支持 TensorFlow、PyTorch、Spark、MPI、MXNet 等框架,Python、R、Java 等语言。
第七,提供图像识别、推荐系统、NLP 三大类别的内置模型分析。
第八,可全面监控集群多项基础指标以及各运行任务粒度资源使用情况,内置集成报警功能,可实现数据实时可视化。
在开源和开放层面,对内,明略科技邀请了集团内部相关人员,包括数据科学家、大数据平台研发人员、运维人员不同角色的人员一起参与到平台建设,有些甚至可以通过 PR 的方式直接提供代码,统一管理产品的发展规划;对外,明略科技后续会计划陆续将内部的成熟模型开放出来,让广大合作伙伴和开发者可以直接加载并使用。
部署建议
对于同样希望建设机器学习平台的企业,刘喆表示,建立机器学习平台的直接目的是提高经济效益或者提高运转效率。但要想达到这两个目的,数据、算力、算法、平台缺一不可。工欲善其事,必先利其器,而平台就是这个“器”。以做菜来举例,数据是食材,平台是锅碗瓢勺等工具,算力是火,算法就是菜谱。要做一碗好菜,食材要好,锅碗瓢勺相对次要,然后火候要好,算力要够强大,再加上一个好的菜谱,也就是算法要好。
从技术选型上来说,刘喆建议企业可以先试用开源工具,毕竟成本低,有可能可以解决大部分问题。当开源工具无法满足需求时,企业可以根据自己的开发能力来进行开发,最重要的是需要计算投入产出比。举例来说,如果是一次性或者短期项目,可能采买是便宜的。如果需要长期使用,自建可能是比较划算的。如果硬要一个做快消品的企业自研一整套的机器学习平台,也是不切实际的,首先可能人才没有到位,其次是企业的发展方向不在技术,花大量成本研发这个没有太大必要,采买就比较合适。
对于历史包袱较重的企业,可以先试验一些通用模型,没准可以解决 30% 的问题,然后再结合一些业务属性整体开发。总体来说就是一开始不需要花费大量力气在这件事情上,最好可以先试用,有效果的话再大量投入。
至于新项目的上线周期,刘喆表示这要看是否需要做新的模型,依据明略科技的部署经验,现有模型上线只需要两周时间,主要是处理各模块之间的对接,如果新做一个模型就要看模型的复杂度,以明略科技现在的经验,大概两到三周就可以完成新模型的上线。
云是必须的吗?
近几年,云几乎成为了构建基础设施的必选项,企业内部的众多平台架构在云平台之上,享受着云计算带来的种种便利。对于机器学习的建设而言,云同样是可行的,但并不是必需品。在刘喆看来,云对资源管理的力度会更精细和精确,不用太关心跨过边界的问题,劣势是架了一层云之后,性能会有一定损失。相对的,原生架构的方式可以将性能用到极致,缺点就是在资源控制层面,需要人工手动做一些管理工作。
至于这种性能损失,以存储为例,利用 K8s 和在硬盘上运行相比,性能损失大概占 33% 左右。如果是一个 100M 的模型,输入大概 150 个特征左右,在云上的响应时间大概是 15 毫秒以内,而纯粹从物理机上运行的时间在 13 毫秒。如果对性能的要求没有那么高,可以选择基于云平台搭建。
既然来了,说些什么?