影响人工智能发展的五大要素
相信大家都听说过2016年李世石和AlphaGo的人机大战,但还有多少人关注了去年12月李世石退役前和韩国围棋AI“韩豆”的人机大战?经历了2017、2018高歌猛进的两年后,相比2018年,2019年中国人工智能企业融资金额下降幅度高达34%,融资数量下降幅度高达40%。去年绝大部分的人工智能公司都不好过,头部企业在上市途中遇阻,小公司生存艰难,裁员消息络绎不绝。
为什么?因为以深度学习为代表的人工智能并没有人们想象得那么全能,在发展过程中人工智能遇到了难以突破的瓶颈,局限人工智能的发展我认为有五个因素:算法、数据、算力、伦理/法律和商业化。
算力
永无止境的算力需求
2012年,谷歌的科学家们将16000个CPU联接起来,建造了一个超大规模的深度学习神经网络—“谷歌大脑”。在研究人员没有给此机器灌输任何关于猫的形态信息的前提下,“谷歌大脑”通过1000多万个YouTube视频缩略图中随机抽取的20000张图片,自己构建了一个模糊的猫的概念。

2016年3月,谷歌的AlphaGo战胜了韩国棋手李世石时,人们慨叹人工智能的强大。但大家可能不知道,2015年10月的分散式运算版本AlphaGo使用了1202块CPU以及176块GPU。

相比云计算和大数据等应用,人工智能对计算力的需求几乎永无止境。根据OpenAI在2018年的分析,近年来人工智能训练任务所需求的算力每 3.43 个月就会翻倍,这一数字大大超越了芯片产业长期存在的摩尔定律(每18个月芯片的性能翻一倍)。也就是说,从2012年到2020年,人们对于算力的需求增长了2^28倍,远远超过了芯片摩尔定律增长的2^5倍(2^23=8388608)。
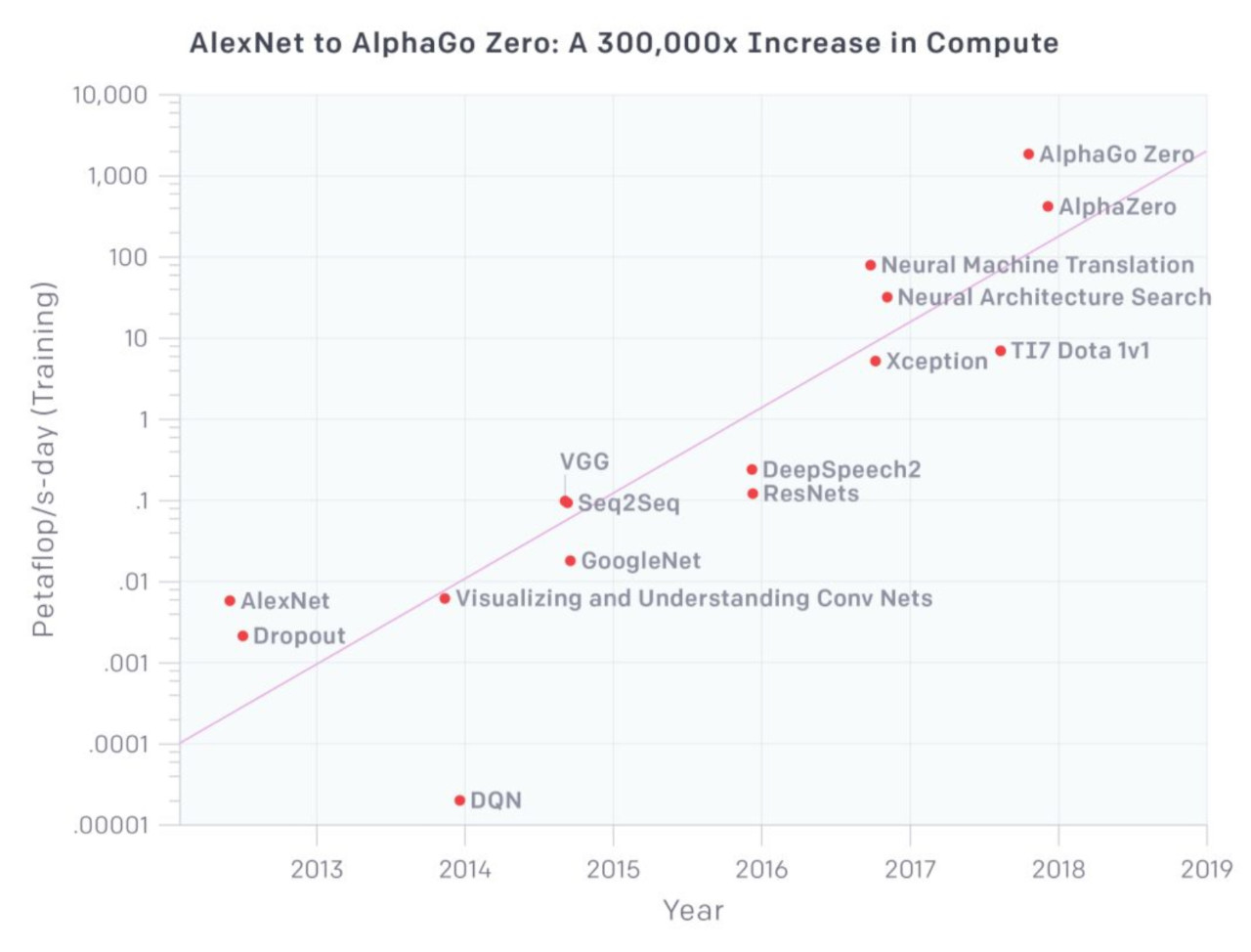
“冯·诺伊曼瓶颈”
冯·诺伊曼架构的存储和计算分离,已经不适合数据驱动的人工智能应用需求。什么是冯·诺伊曼架构?
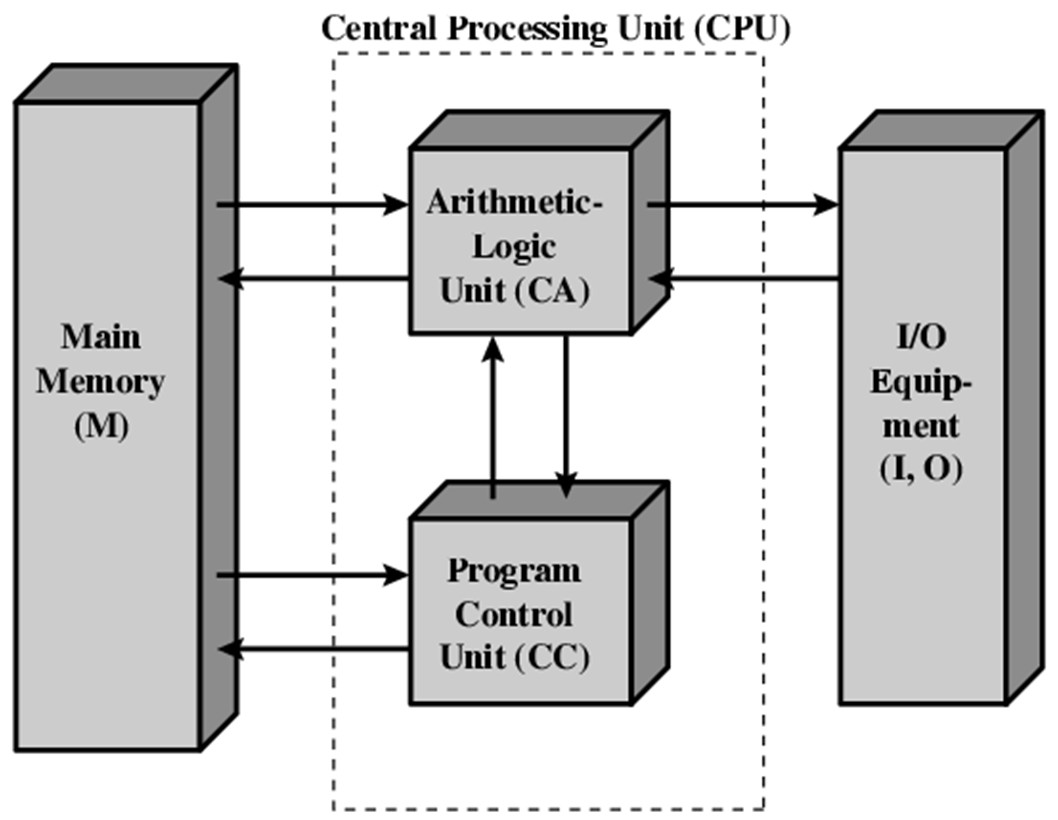
如上图,在冯·诺伊曼架构中存储单元和计算单元是分隔开的,当计算机运算时,需要将数据从存储单元读取到计算单元,运算后会把结果写回存储单元。在大数据驱动的人工智能时代,AI运算中数据搬运更加频繁,需要存储和处理的数据量远远大于之前常见的应用。当运算能力达到一定程度,由于访问存储单元的速度无法跟上计算单元消耗数据的速度,再加上计算单元无法得到充分利用,即形成所谓的“冯·诺伊曼瓶颈”。
如果要解决当前算力远不满足人工智能对计算力的需求,将数据存储单元和计算单元融合为一体有可能突破AI算力的瓶颈。类似于脑神经结构的计算存储一体化可以显著减少数据搬运,极大提高计算并行度和能效。但是目前新型的计算架构并没有成熟。
算法
难以突破的准确率
现在很多算法都难以突破瓶颈,举个例子,语音识别准确率。据我们所知,我们的语音识别准确率在2015年已经达到97%,那几时可以达到99.9%?这是一个好问题。我们看一下这两组数据,第一组数据是85%到90%,它的失误率降低1/3,我们可以认为这是渐进式变化,渐进式变化意味着找对方法,进一步增长是很有可能实现的,例如语音和图像识别的准确率在12-16年都在以2-3倍的速度增长。第二组数据是98%到99.9%,大家别以为前面的5% 比后面的1.9%困难,其实后者失误率降低到从前的1/20,这20倍的增长并不是渐进式变化。

当算法难以突破瓶颈,这时候预测的结果就会不准。大家要记住一点,上面的准确率是实验室环境下测量的,在真实环境下,实际准确率可能连60%都达不到,能不能产品化或者如何产品化就会成为问题。
深度学习即将遭遇瓶颈
2019年,超过1.3万名人工智能领域的专家齐聚温哥华,参加世界领先的人工智能学术会议NeurIPS。在会上有不少专家对深度学习的局限性表示了担忧,认为这项技术的发展即将遭遇瓶颈。谷歌顶级研究员Blaise Agueray Arcas认为深度学习技术迅速消除了人工智能领域长期存在的一些挑战,但这不意味着它能解决所有问题。被誉为“深度学习之父”的三位学者之一的Yoshua Bengio也提出了自己的见解:“我们的算法和模型非常狭隘,它们学习一项任务需要比人类多得多的样本,但即便如此它们还是会犯非常愚蠢的错误。”
Facebook的人工智能总监Jerome Pesenti也表达了对深度学习和算力达到瓶颈的担忧:“当你扩展深度学习时,它往往表现得更好,能够以更好的方式解决更广泛的任务。但显然,这种进步速度是不可持续的。如果你看看最前沿的科学实验,它们每年的成本都会增加数10倍。现在,一个实验的花销可能是7位数,但不会达到9位数或10位数,不可能,没人能负担得起。这意味着在某个时候,在很多我们目前已经涉及的领域,我们会撞到墙。”
数据
AI很难理解非结构化数据
计算机数据被称为信息时代的石油,计算机数据分为两种—结构化数据和非结构化数据。结构化数据是指具有预定义的数据模型的数据,它的本质是将所有数据标签化、结构化,后续只要确定标签,数据就能读取出来,例如数组、表格、网页等等,这种方式容易被计算机理解。
而非结构化数据是指数据结构不规则或者不完整,没有预定义的数据模型的数据。非结构化数据格式多样化,包括了图片、音频、视频、文本、网页等,它比结构化数据更难标准化和理解。
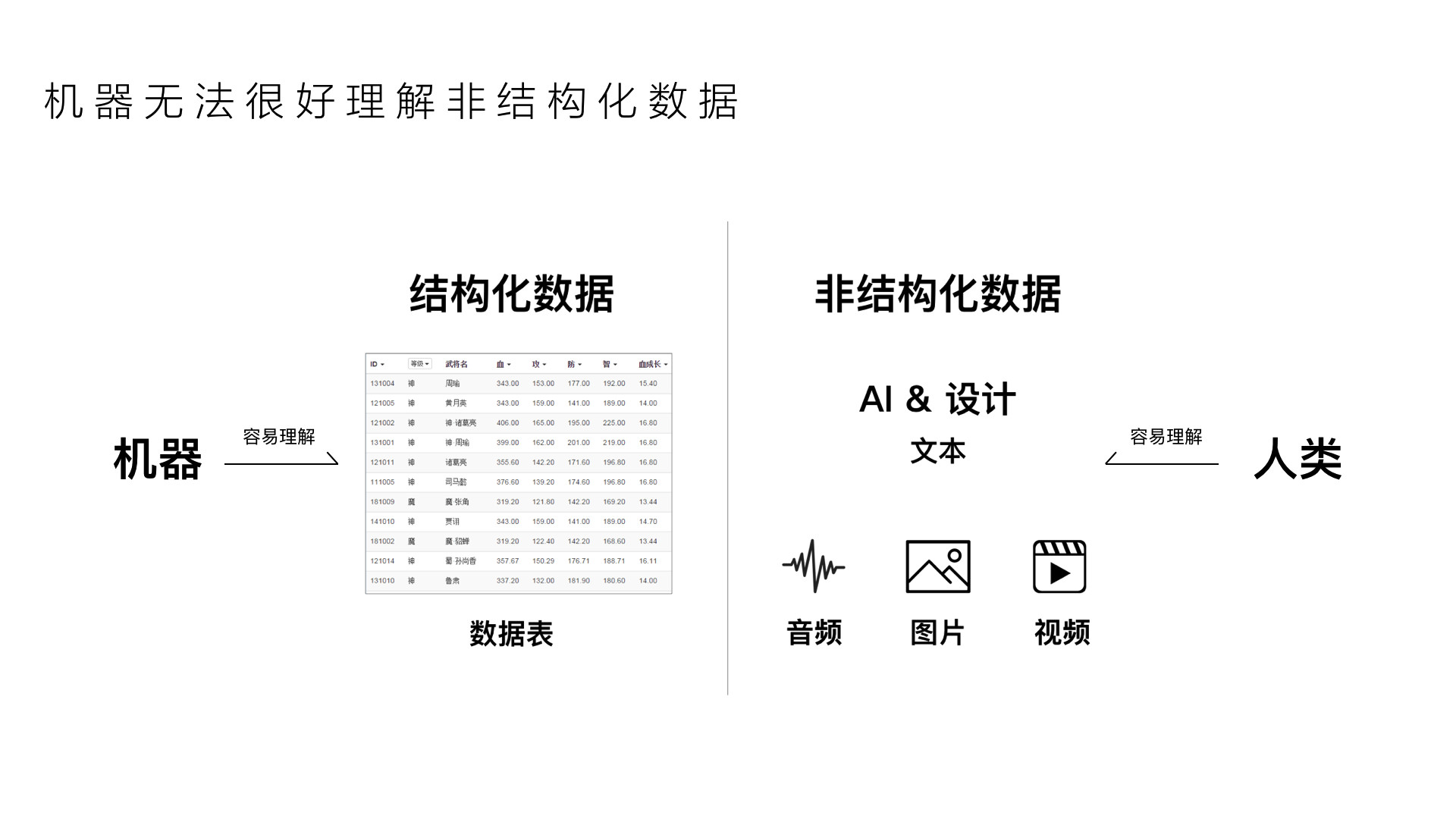
音频、图片、文本、视频这四种载体可以承载着来自世界万物的信息,人类在理解这些内容时毫不费劲;对于只懂结构化数据的计算机来说,理解这些非结构化内容比登天还难,这也就是为什么人与计算机交流时非常费劲。全世界有80%的数据都是非结构化数据,人工智能想要从“看清”“听清”达到“看懂”“听懂”的状态,必须要把非结构化数据这块硬骨头啃下来。
为了更好地说明理解数据成为人工智能发展的重要瓶颈,我以人类最容易理解的语言语句为例。语言语句是结构化和非结构化的结合,每一种语言都有固定的语法结构,这是数据结构化的体现;但语言内的每一个词语都不是预定义的,所以我们可以理解词语是非结构化的。
每一个词语都是单独个体,它们有自己的意思,但有趣的是,这个词语可能会有多个意思;两个词语结合可以产生短语,这个短语有它独特的意思;再加上不同的语句在不同场景下可能有其他含义,所以非结构化数据会使机器很难理解每个词语组成后的句子是什么意思。
数据质量和标准化引起AI算法偏见
我们都知道深度学习使用的训练样本越多,模型精确度就越高,但是依然存在着AI算法偏见这事情,导致AI算法偏见的主要原因有两个:
1.导致产生算法偏见的数据来自哪里?
2.如何衡量数据的标准?

以人脸识别为例子。人脸识别系统需要在非常庞大的数据集上进行训练,为了达到最佳的训练效果,研究人员需要获取同一个人的多张相片。最大的人脸数据集拥有67万人员信息和5百万张照片,而这些都来自美国的相册网络—Flickr,那么使用Flickr的都是哪一些人?更多是美国用户。以美国人的照片作为基础来训练人脸识别模型可能会导致它在识别其他地区的人民群众时产生算法偏见,因为全球的互联网访问量并非均匀分布的,5百万的照片不能代表地球70亿人。当人脸识别系统模型没“见过”一些“独特”的脸部特征时,有可能会把他们误认为不是人类。
相信大家也听说过谷歌的人脸识别把一名黑人识别为大猩猩,这就是因为数据偏差导致的,而当时谷歌公司的整改方法是把识别类别中的”大猩猩“去掉了,这件事成为当时的热议话题。


尽管过了几年人脸识别技术有较大的提升,但相较于白人,亚裔和非裔的人脸识别错误率要高10到100倍。2017年MIT实验室的一项研究也得出了类似的结果,凡遇到肤色较暗的人种以及女性,识别的错误率就增加。
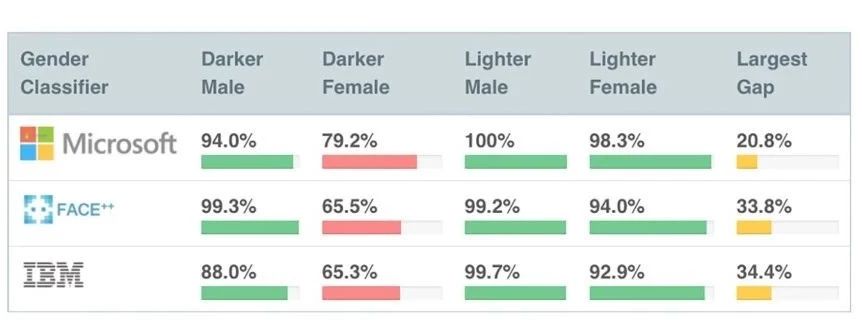
同理,研究人员也会导致数据产生偏差。世界最大的图形数据集—ImageNet至少有10万个标签是存在问题的,但大部分研究人员都没有发现这个问题。为什么会产生这种情况?因为很多数据集都需要人来手动进行注释,而研究人员一般不会花自己的时间去标注海量的数据,而是通过众包的形式把这些海量数据标注化。但是众包这种方式会存在着很多来自人类的干扰因素,包括背景、文化、认知水平甚至是情绪、性格等主观因素。举些例子,标注人员分得清楚秋田犬和柴犬的差别吗?标注人员如何看待色情和性感的区别?

有些数据标注是不能采用众包方式来解决的,例如医疗数据。医疗数据需要大量训练有素的专家手动给出“标准答案”,才能提高人工智能的准确性,这是一个十分消耗资源的过程。但是需要注意的是,我国缺乏规范化标准化的临床术语语义体系,不同医生使用的医学术语不同,不同医院对于图像的质量要求也不尽相同,这会导致医疗数据质量参差不齐,也给人工智能训练带来偏差。
正是因为数据来源和数据标注这两个问题导致现在的人工智能是有问题的,而研究人员还没有找到更好的办法去解决这两个问题。
伦理/法律
上述的算力、算法、数据是人工智能的基础,也是人工智能发展的瓶颈。当人工智能从实验室进入社会后,伦理和法律问题将成为人工智能新的天花板。
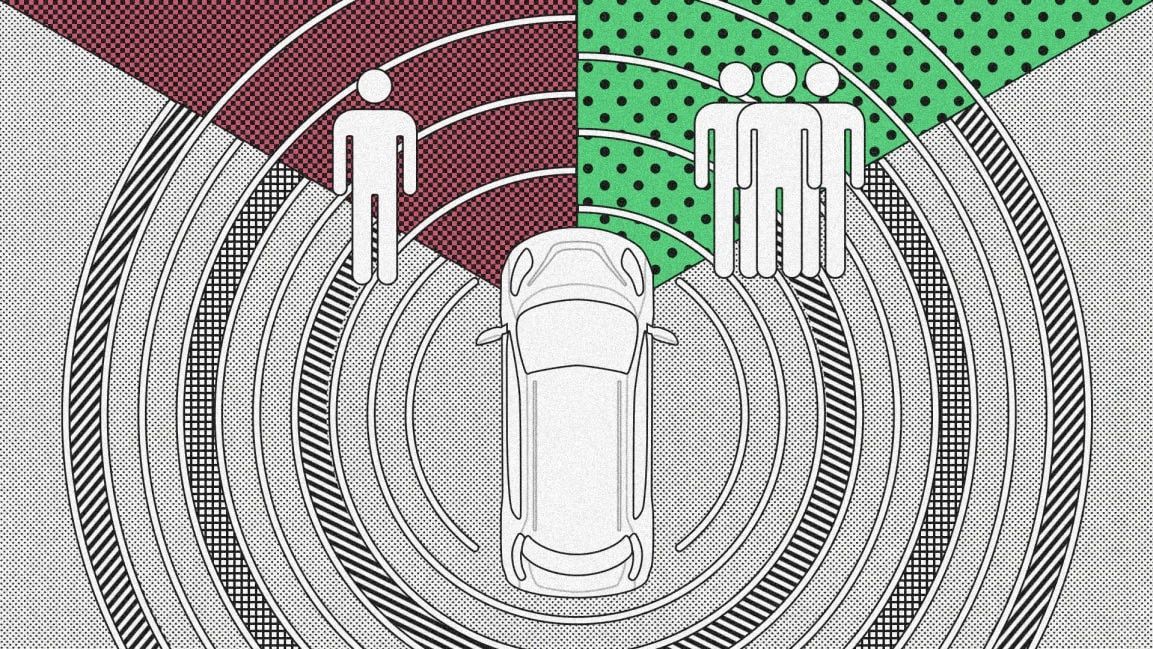
相信这个问题大家不陌生,当一辆车发生事故时,司机该撞向人多的地方还是人少的地方?这个问题是没有正确答案的,因为撞哪都有伦理问题。既然人都无法解决的伦理问题,那么机器怎么解决呢?如果这是一辆自动驾驶汽车,那么该汽车发生事故谁来负责?是司机?是汽车厂商?还是设计这个自动驾驶技术的研究人员?现在没有相关的法律来定义这类意外事故的责任方是谁。
人工智能技术能让一部分人陷入“莫须有”的名誉危机里。Deepfake,也就是“AI换脸”,从国外的恶搞特朗普、盖尔加朵,到国内的ZAO App的昙花一现,对社会和民众带来很大影响。曾经有一项研究表明,目前网上有14678个DeepFake视频,其中96%是色情视频,大部分都是著名女演员的脸被转移到色情明星的身体上。对于普通人或知名度较低的女性而言,deepfake技术让造假色情视频变得十分容易,基于报复或其他目的的色情视频,可能让女性面临更高的名誉风险而难以自辩。


有人认为算法是种族主义者,因为它是人类的产物。在美国一起贷款驳回案件中,银行被告上了法庭,申请人是一名黑人,他宣称银行的贷款评估算法严重歧视了黑人,有明显的种族歧视问题。尽管银行最后赢得胜诉,但是他们看回之前的贷款记录,确实黑人的申请通过率远低于白人。
Northpointe公司开发的犯罪风险评估算法COMPAS是目前在美国各地使用的几种风险评估算法之一,它会对犯罪人的再犯风险进行评估,并给出一个再犯风险分数,法官可以据此决定犯罪人所应遭受的刑罚。非营利组织ProPublica研究发现,这一算法系统性地歧视了黑人,白人更多被错误地评估为低犯罪风险,而黑人被错误地评估为高犯罪风险的概率是白人的两倍。
通过跟踪调查7000多名犯罪人,ProPublica发现,COMPAS给出的再犯风险分数在预测未来犯罪方面非常不可靠,在被预测为未来会犯暴力犯罪的犯罪人中,仅有20%的犯罪人后来确实再次实施暴力犯罪。所以,我们很难保证基于大数据的人工智能是否会带来社会不公平和歧视。
商业化
商业化是一个综合因素。目前绝大部分的人工智能技术都只是停留在实验室试验阶段,在实验室环境下它们的模型准确率有可能很高,但进入到真实环境下准确率可能会瞬间暴跌。运算模型是整个商业产品和工程系统最核心的一部分,如果深度学习模型的准确率导致项目无法商业化落地,首先企业无法进行自身造血;其次研究人员无法在自己建立的模型上获取更多真实数据,这会导致人工智能模型的准确率无法提高。如此一来,整个项目就会进入一个死循环。如果政府或者法律的介入导致人工智能项目的商业化受阻,这会对企业造成毁灭性的打击。因此,如何将人工智能技术商业化落地成为研究人员、企业家以及政府人员烦恼的事情。
基于以上五点,人工智能所面临的挑战依然很大,研究人员也开始将视线从深度学习向其他技术领域转移。最近的明显趋势是由最常见的监督学习向半监督、自监督甚至无监督机器学习转向,如何用尽量少的有标训练数据让机器自主学会更多的知识;除此之外,如何建立AI模型的性能指标、如何向人类解释AI输出的结果,以及如何通过AI更好地反映人们想要建立的社会,这些是人工智能的最新发展方向。
原文:https://mp.weixin.qq.com/s/YGEgIifO32N__LBSmmPorg
既然来了,说些什么?