深度剖析:针对深度学习的GPU共享

当前机器学习训练中,使用GPU提供算力已经非常普遍,对于GPU-based AI system的研究也如火如荼。在这些研究中,以提高资源利用率为主要目标的GPU共享(GPU sharing)是当下研究的热点之一。
本篇文章希望能提供一个对GPU共享工作的分享,希望能和相关领域的研究者们共同讨论。
GPU共享,是指在同一张GPU卡上同时运行多个任务。优势在于:
(1)集群中可以运行更多任务,减少抢占。
(2)资源利用率(GPU/显存/e.t.c.)提高;GPU共享后,总利用率接近运行任务利用率之和,减少了资源浪费。
(3)可以增强公平性,因为多个任务可以同时开始享受资源;也可以单独保证某一个任务的QoS。
(4)减少任务排队时间。
(5)总任务结束时间下降;假设两个任务结束时间分别是x,y,通过GPU共享,两个任务全部结束的时间小于x+y。
想要实现GPU共享,需要完成的主要工作有:(1)资源隔离,是指共享组件有能力限制任务占据算力(线程/SM)及显存的比例,更进一步地,可以限制总线带宽。(2)并行模式,主要指时间片模式和MPS模式。
资源隔离
资源隔离是指共享组件有能力限制任务占据算力/显存的比例。限制的方法就是劫持调用。图一是在Nvidia GPU上,机器学习自上而下的视图。由于Cuda和Driver不开源,因此资源隔离层一般处在用户态。
在内核态做隔离的困难较大,但也有一些工作。顺带一提,Intel的Driver是开源的,在driver层的共享和热迁移方面有一些上海交大和Intel合作的工作。

来自腾讯的Gaia(ISPA’18)[1]共享层在Cuda driver API之上,它通过劫持对Cuda driver API的调用来做到资源隔离。劫持的调用如图二所示。
具体实现方式也较为直接,在调用相应API时检查:
(1)对于显存,一旦该任务申请显存后占用的显存大小大于config中的设置,就报错。(2)对于计算资源,存在硬隔离和软隔离两种方式,共同点是当任务使用的GPU SM利用率超出资源上限,则暂缓下发API调用。
不同点是如果有资源空闲,软隔离允许任务超过设置,动态计算资源上限。而硬隔离则不允许超出设置量。该项目代码开源在[2]。
实测即使只跑一个任务也会有较大JCT影响,可能是因为对资源的限制及守护程序的资源占用问题。KubeShare(HPDC ’20)[3]的在资源隔离方面也是类似的方案。
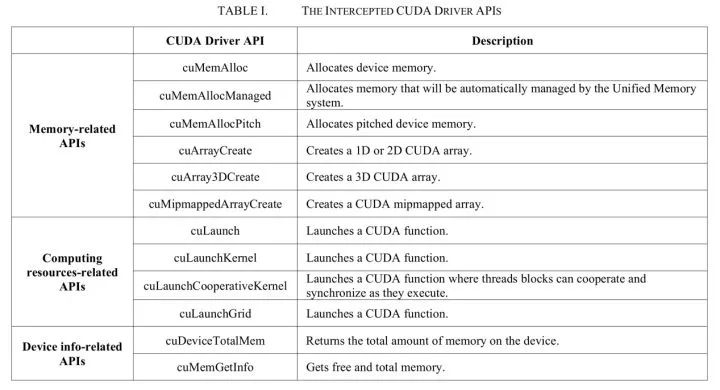 图二/ Gaia限制的CUDA driver API
图二/ Gaia限制的CUDA driver API发了44篇论文(截止2020年3月)的rCuda[4]和Gaia有相似之处,他们都是在Cuda driver API之上,通过劫持调用来做资源隔离。
不同的是,rCuda除了资源隔离,最主要的目标是支持池化。池化简单来讲就是使用远程访问的形式使用GPU资源,任务使用本机的CPU和另一台机器的GPU,两者通过网络进行通信。也是因为这个原因,共享模块需要将CPU和GPU的调用分开。
然而正常情况下混合编译的程序会插入一些没有开源的Cuda API,因此需要使用作者提供的cuda,分别编译程序的CPU和GPU部分。
图三显示了rCuda的架构。如果使用该产品,用户需要重新编译,对用户有一定的影响。该项目代码不开源。
另外vCUDA(TC ’12)[5]和qCUDA(CloudCom ’19)[18]也采用了和rCuda相似的技术。
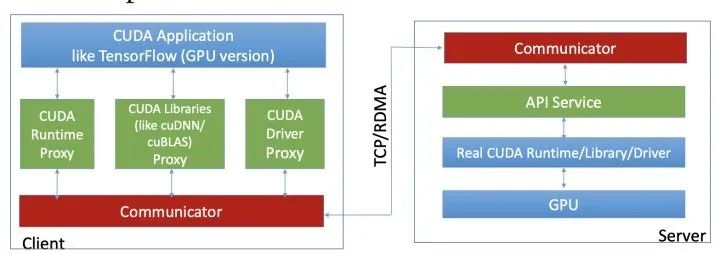 图三/rCuda架构
图三/rCuda架构GPUShare(IPDPSW’ 16)[6]也是劫持的方式,但不同的是,它采用预测执行时间的方式来实现计算资源的公平性。
作者认为比切换周期还小的短kernel不会影响公平使用,因此只限制了较大的kernel。
来自阿里的cGPU[7],其共享模块在Nvidia driver层之上,也就是内核态。由于是在公有云使用,相对于用户态的共享会更加安全。
它也是通过劫持对driver的调用完成资源隔离的,通过设置任务占用时间片长度来分配任务占用算力,但不清楚使用何种方式精准地控制上下文切换的时间。
值得一提的是,由于Nvidia driver是不开源的,因此需要一些逆向工程才可以获得driver的相关method的name和ioctl参数的结构。
该方案在使用上对用户可以做到无感知,当然JCT是有影响的。代码没有开源,也没有论文。图四是cGPU的架构图。
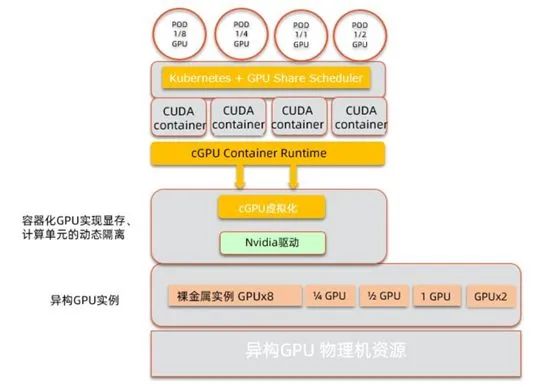 图四/cgpu架构图
图四/cgpu架构图来自Nvidia的vGPU[8]其共享模块在Nvidia driver里面。vGPU通过vfio-mdev提供了一个隔离性非常高的的硬件环境,主要面向的是虚拟机产品,无法动态调整资源比例。
来自Nvidia的产品当然没有开源。图五是vGPU的架构图。
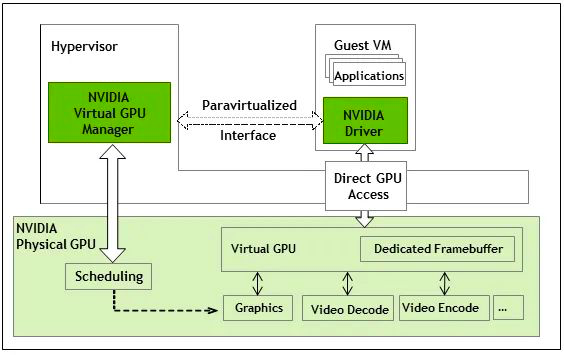
图五/vGPU架构图
Fractional GPU(RTAS’ 19)[9]是一篇基于MPS的资源隔离方案。其共享模块在Nvidia driver里面。该方案的隔离非常硬,核心就是绑定。
在计算隔离方面,它通过给任务绑定一定比例的可使用SM,就可以天然地实现计算隔离。MPS的计算隔离是通过限制任务的thread数,相较于Fractional GPU会限制地更加不准确。
在显存隔离方面,作者深入地研究Nvidia GPU内存架构(包括一些逆向工程)图六是Fractional GPU通过逆向得到的Nvidia GPU GTX 970的存储体系架构。
通过页面着色(Page Coloring)来完成显存隔离。页面着色的思想也是将特定的物理页分配给GPU SM分区,以限制分区间互相抢占的问题。
该隔离方案整体上来说有一定损耗,而且只能使用规定好的资源比例,不能够灵活地检测和使用全部空闲资源。另外使用该方案需要修改用户代码。代码开源在[10]。
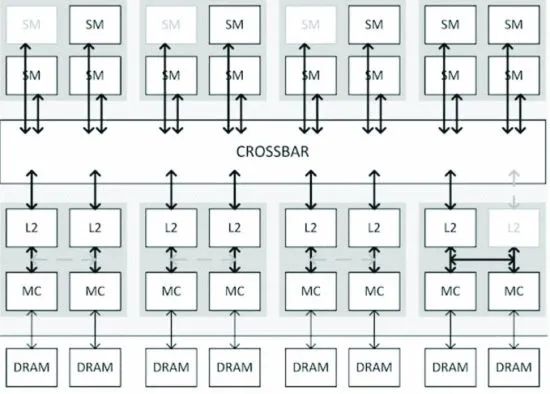 图六/Fractional GPU通过逆向得到的Nvidia GPU GTX 970的存储体系架构
图六/Fractional GPU通过逆向得到的Nvidia GPU GTX 970的存储体系架构Mig( MULTI-INSTANCE GPU)[21]是今年A100机器支持的资源隔离方案,Nvidia在最底层硬件上对资源进行了隔离,可以完全地做到计算/通信/配置/错误的隔离。
它将SM和显存均匀地分给GPU instance,最多支持将SM分7份(一份14个),显存分8份(1份5GB)。顺带一提A100有SM108个,剩下的10个将无法用上。它可选的配置也是有限制的,如图七所示。
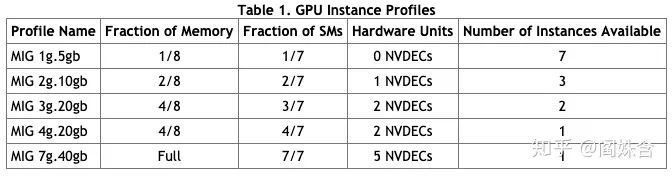
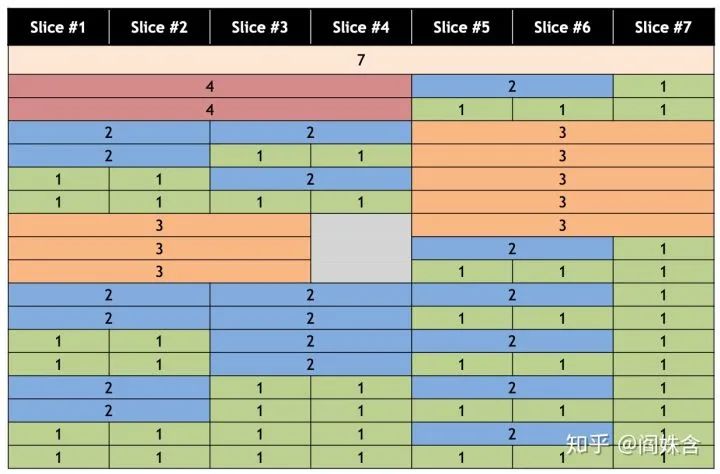 图七/Mig GPU Instance配置
图七/Mig GPU Instance配置并行模式
并行模式指任务是以何种方式在同一个GPU上运行的。目前有两种方式:
(1)分时复用。指划分时间片,让不同的任务占据一个独立的时间片,需要进行上下文切换。在这种模式下,任务实际上是并发的,而不是并行的,因为同一时间只有一个任务在跑。
(2)合并共享。指将多个任务合并成一个上下文,因此可以同时跑多个任务,是真正意义上的并行。在生产环境中,更多使用分时复用的方式。
分时复用
分时复用的模式大家都较为熟悉,CPU程序的时间片共享已经非常常见和易用,但在GPU领域还有一些工作要做。
如果在Nvidia GPU上直接启动两个任务,使用的就是时间片共享的方式。
但该模式存在多任务干扰问题:即使两个机器学习任务的GPU利用率和显存利用率之和远小于1,单个任务的JCT也会高出很多。究其原因,是因为计算碰撞,通信碰撞,以及GPU的上下文切换较慢。
计算碰撞很好理解,如果切换给另一个任务的时候,本任务正好在做CPU计算/IO/通信,而需要GPU计算时,时间片就切回给本任务,那么就不会有JCT的影响。但两个任务往往同时需要使用GPU资源。
通信碰撞,是指任务同时需要使用显存带宽,在主机内存和设备显存之间传输数据。GPU上下文切换慢,是相对CPU而言的。
CPU上下文切换的速度是微秒级别,而GPU的切换在毫秒级别。在此处也会有一定的损耗。图八是分时复用模式的常见架构。
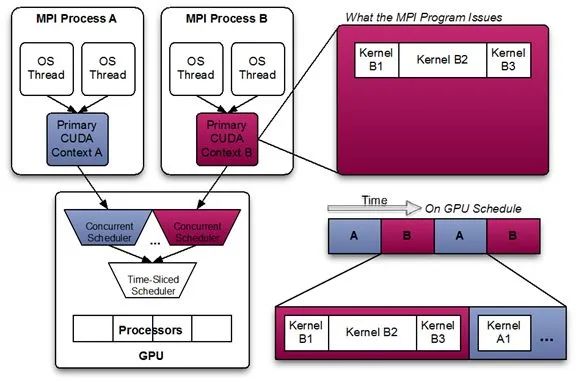 图八/分时复用架构图
图八/分时复用架构图上文提到的Gaia,KubeShare,rCuda,vCuda,qCuda,cGPU,vGPU均为分时复用的模式。
由于上文所述的问题,他们的单个任务完成时间(JCT)都会受到较大的影响。V100测试环境下,两个任务同时运行,其JCT是单个任务运行时的1.4倍以上。
因此在生产环境下,我们需要考虑如何减少任务之间互相影响的问题。上述方案都没有考虑机器学习的特性,只要共享层接收到kernel下发,检查没有超过设置上限,就会继续向下传递。
另外也限制任务显存的使用不能超过设置上限,不具备弹性。因此针对特定的生产场景,有一些工作结合机器学习任务的特性,进行了资源的限制及优化。
服务质量(QoS)保障
在生产环境的GPU集群中常会有两类任务,代称为高优先级任务和低优先级任务。高优任务是时间敏感的,在它需要资源时需要立刻提供给它。
而低优任务是时间不敏感的,当集群有资源没被使用时,就可以安排它填充资源缝隙以提高集群利用率。因此共享模块需要优先保障高优先级任务的JCT不受影响,以限制低优任务资源占用的方式。
Baymax(ASPLOS ’16)[11]通过任务重排序保障了高优任务的QoS。Baymax作者认为多任务之间的性能干扰通常是由排队延迟和PCI-e带宽争用引起的。
也就是说,当高优任务需要计算或IO通信时,如果有低优的任务排在它前面,高优任务就需要等待,因此QoS无法保障。针对这两点Baymax分别做了一些限制:
(1)在排队延迟方面,Baymax利用KNN/LR模型来预测持续时间。然后Baymax对发给GPU的请求进行重新排序。
简单来说,就是共享模块预测了每个请求的执行时间,当它认为发下去的请求GPU还没执行完时,新下发的请求就先进入队列里。
同时将位于队列中的任务重排序,当需要下发请求时,先下发队列中的高优任务请求。
(2)在PCI-e带宽争用方面,Baymax限制了并发数据传输任务的数量。Baymax作者在第二年发表了Prophet(ASPLOS ’17)[12],用于预测多任务共置时QoS的影响程度。
在论文最后提到的实验中,表示如果预测到多个任务不会影响QoS,就将其共置,但此处共置使用的是MPS,也就是没有使用分时复用的模式了。
在该研究中,预测是核心。预测准确性是否能适应复杂的生产环境,预测的机器负载是否较大,还暂不清楚。
来自阿里的AntMan(OSDI ’20)[13]也认为排队延迟和带宽争用是干扰的原因,不同的是,它从DL模型的特点切入,来区分切换的时机。
在算力限制方面,AntMan通过限制低优任务的kernel launch保证了高优任务的QoS。图九是AntMan算力共享机制的对比。
AntMan算力调度最小单元,在论文中描述似乎有些模糊,应该是Op(Operator),AntMan“会持续分析GPU运算符的执行时间“,并在空隙时插入另一个任务的Op。
但如何持续分析,论文中并没有详细描述。在显存隔离方面,AntMan没有限制显存的大小,而是尽力让两个任务都能运行在机器上。但两个或多个任务的显存申请量可能会造成显存溢出,因此AntMan做了很多显存方面的工作。
首先需要了解任务在显存中保存的内容:首先是模型,该数据是大小稳定的,当它在显存中时,iteration才可以开始计算。
论文中表示90%的任务模型使用500mb以内的显存。其次是iteration开始时申请的临时显存,这部分显存理论上来说,在iteration结束后就会释放。
但使用的机器学习框架有缓存机制,申请的显存不会退回,该特性保障了速度,但牺牲了共享的可能性。
因此AntMan做了一些显存方面最核心的机制是,当显存放不下时,就转到内存上。在此处论文还做了很多工作,不再尽述。
论文描述称AntMan可以规避总线带宽争用问题,但似乎从机制上来说无法避免。
除此之外,按照Op为粒度进行算力隔离是否会需要大量调度负载也是一个疑问,另外Op执行时间的差异性较大,尤其是开启XLA之后,这也可能带来一些不确定性。该方案需要修改机器学习框架(Tensorflow和Pytorch),对用户有一定的影响。
代码开源在[20],目前还是WIP项目(截止2020/11/18),核心部分(local-coordinator)还没能开源。
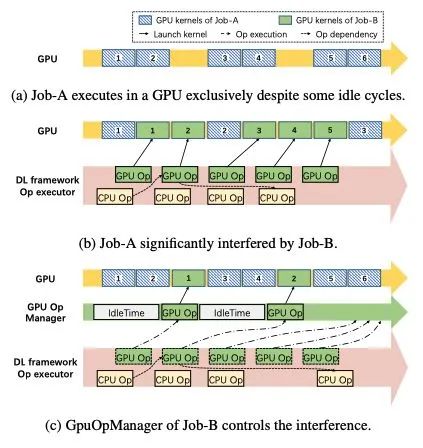 图九/AntMan算力共享机制的对比
图九/AntMan算力共享机制的对比如果最小调度单元是iteration,则会更加简单。首先需要了解一下DL训练的特征:训练时的最小迭代是一个iteration,分为四个过程:
IO,进行数据读取存储以及一些临时变量的申请等;前向,在此过程中会有密集的GPU kernel。NLP任务在此处也会有CPU负载。后向,计算梯度更新,需要下发GPU kernel;更新,如果非一机一卡的任务,会有通信的过程。之后更新合并后的梯度,需要一小段GPU时间。
可以看出前向后向和通信之后的更新过程,是需要使用GPU的,通信和IO不需要。
因此可以在此处插入一些来自其他任务的kernel,同时还可以保证被插入任务的QoS。更简单的方式是,通过在iteration前后插入另一个任务的iteration来完成共享。
当然这样就无法考虑通信的空隙,可以被理解是一种tradeoff。另外也因为iteration是最小调度单元,避免了计算资源和显存带宽争用问题。
另外,如果不考虑高优任务,实现一个退化版本,贪心地放置iteration而不加以限制。可以更简单地提高集群利用率,也可以让任务的JCT/排队时间减小。
针对推理的上下文切换
在上文中描述了分时复用的三个问题,其中上下文切换是一个耗时点。
来自字节跳动的PipeSwitch(OSDI ’20)[14]针对推理场景的上下文切换进行了优化。具体生产场景是这样的:训练推理任务共享一张卡,大多数时候训练使用资源。当推理请求下发,上下文需要立刻切换到推理任务。
如果模型数据已经在显存中,切换会很快,但生产环境中模型一般较大,训练和推理的模型不能同时加载到显存中,当切换到推理时,需要先传输整个模型,因此速度较慢。
在该场景下,GPU上下文切换的开销有:
(1)任务清理,指释放显存。(2)任务初始化,指启动进程,初始化Cuda context等。(3)Malloc。(4)模型传输,从内存传到显存。
在模型传输方面,PipeSwitch作者观察到,和训练不同的是推理只有前向过程,因此只需要知道上一层的输出及本层的参数就可以开始计算本层。
目前的加载方式是,将模型数据全部加载到显存后,才会开始进行计算,但实际上如果对IO和计算做pipeline,只加载一层就开始计算该层,就会加快整体速度。当然直接使用层为最小粒度可能会带来较大开销,因此进行了grouping合并操作。
图十显示了pipeline的对比。在任务清理和初始化方面,设置了一些常驻进程来避免开销。最后在Malloc方面也使用了统一的内存管理来降低开销。
可以说做的非常全面。由于需要获知层级结构,因此需要对Pytorch框架进行修改,对用户有一定影响。代码开源在[19].
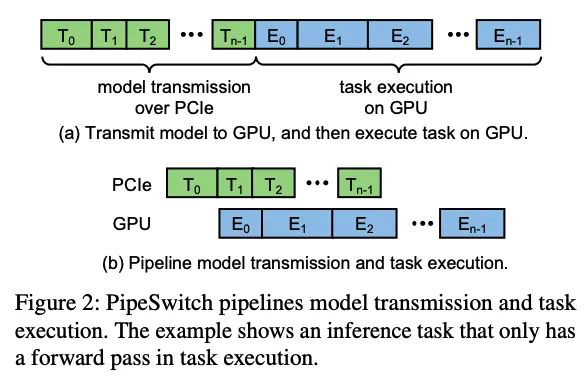
图十/PipeSwitch pipeline的对比
合并共享
合并共享是指,多个任务合并成一个上下文,因此可以共享GPU资源,同时发送kernel到GPU上,也共同使用显存。最具有代表性的是Nvidia的MPS[15]。
该模式的好处是显而易见的,当任务使用的资源可以同时被满足时,其JCT就基本没有影响,性能可以说是最好的。可以充分利用GPU资源。
但坏处也是致命的:错误会互相影响,如果一个任务错误退出(包括被kill),如果该任务正在执行kernel,那么和该任务共同share IPC和UVM的任务也会一同出错退出。
目前还没有工作能够解决这一问题,Nvidia官方也推荐使用MPS的任务需要能够接受错误影响,比如MPI程序。
因此无法在生产场景上大规模使用。另外,有报告称其不能支持所有DL框架的所有版本。
在资源隔离方面,MPS没有显存隔离,可以通过限制同时下发的thread数粗略地限制计算资源。它位于Nvidia Driver之上。图十一是MPS的架构图。
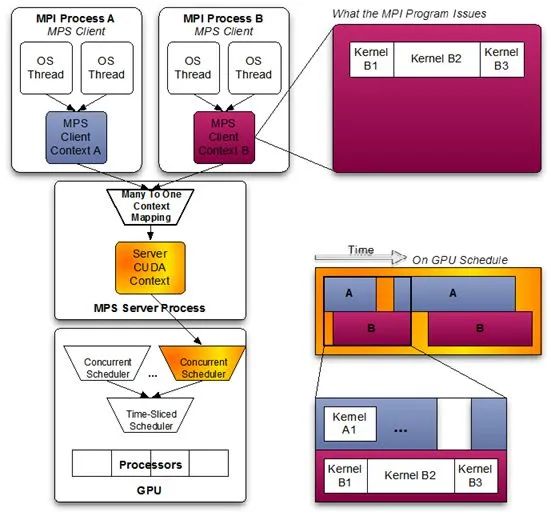 图十一/MPS架构图
图十一/MPS架构图Salus(MLSys ’20)[16]也采取了合并共享的方式,作者通过Adaptor将GPU请求合并到同一个context下,去掉了上下文切换。
当然,和MPS一样会发生错误传播,论文中也没有要解决这一问题,因此无法在生产环境中使用。
但笔者认为这篇论文中更大的价值在显存和调度方面,它的很多见解在AntMan和PipeSwitch中也有体现。调度方面,以iteration为最小粒度,并且诠释了原因:使用kernel为粒度,可以进一步利用资源,但会增加调度服务的开销。
因此折中选择了iteration,可以实现性能最大化。显存方面,一些观察和AntMan是一致的:显存变化具有周期性;永久性显存(模型)较小,只要模型在显存中就可以开始计算;临时性显存在iteration结束后就应该释放。
也描述了机器学习框架缓存机制的死锁问题。不过Salus实现上需要两个任务所需的显存都放到GPU显存里,没有置换的操作。
论文中也提到了推理场景下的切换问题:切换后理论上模型传输时间比推理延迟本身长几倍。
除此之外论文中也有一些其他的观察点,值得一看。图十二展示了Salus架构。该项目代码开源在[17]。Salus也需要修改DL框架。作者也开源了修改后的tensorflow代码。
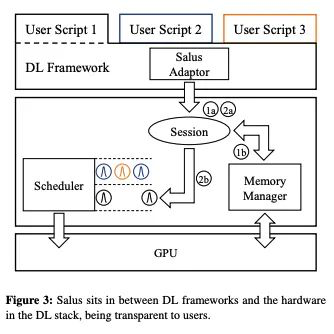
图十二/Salus架构图
如果在合并共享模块之上做分时复用,应可以绕过硬件的限制,精准地控制时间片和切换的时机,也可以去除上下文切换的开销。但在这种情况下是否还会有错误影响,还需要进一步验证。
场景展望
目前GPU共享已经逐渐开始进入工业落地的阶段了,若需要更好地满足用户对使用场景的期待,除了更高的性能,笔者认为以下几点也需要注意。
1、能够提供稳定的服务,运维便捷。比如MPS的错误影响是不能被接受的,另外对于带有预测的实现,也需要更高的稳定性。共享工作负载尽量降低。
2、更低的JCT时延,最好具有保障部分任务QoS的能力。对于一个已有的GPU集群进行改造时,需要尽量减少对已有的用户和任务的影响。
3、不打扰用户,尽量不对用户的代码和框架等做修改,另外也需要考虑框架和其他库的更新问题。
原文:https://mp.weixin.qq.com/s/o-pfieZ_j1Gr_Igrsqud0w
既然来了,说些什么?