从概念到实践,迁移学习是机器学习发展的下一重要阶段
迁移学习的研究来源于一个观测:人类可以将以前学到的知识应用于解决新的问题,从而提高解决问题的效率或取得更好的效果。因此迁移学习被赋予这样一个任务:从以前的任务当中去学习知识(knowledge)或经验,并应用于新的任务当中。换句话说,迁移学习的目的是从一个或多个源任务(source tasks)中抽取知识、经验,然后应用于一个有相关性的目标领域(target domain)中去。
当前,在人工智能落地各垂直领域的过程中,迁移学习被认为将会发挥较大作用。前百度首席科学家、斯坦福教授吴恩达在去年12月的NIPS会议中讲到:
未来,真正的人工智能会落在 unsupervised learning(无监督学习)和 reinforcement
learning(强化学习)上,但很明显,目前这两个领域的水平与有监督的深度学习还无法相比,而迁移学习正是一切还没成熟前的一个折中处理方法。事实上,迁移学习会是继监督学习之后,机器学习在产业界取得成功的下一个关键驱动力。
竹间智能在探索AI行业解决方案的过程中,使用迁移学习方法,已经让机器能够通过“学习”去学习。尤其当用户现有的数据量较小时,在竹间训练过的模型基础上做迁移学习可以很大程度上提高模型的性能,达到更好的机器学习效果。
此次,竹间智能 自然语言与深度学习小组,将从单任务与多任务学习谈起,来深入解析迁移学习并分析目前的迁移学习方法,同时对迁移学习的发展前景做一些分析。希望对大家了解迁移学习及其在人工智能领域中的作用有所帮助。
从单任务学习与多任务学习说起
多任务学习相对于单任务学习来说,在机器学习研究中已经是一个热门的课题。一般来讲,多任务学习在我们的日常生活中随处可见。例如如果一个人知道如何骑自行车,那么他会很容易地学习骑摩托车,因为骑自行车和摩托车之间在平衡感的知识学习中是相似的。再者,如果一个人知道如何 play basketball,那么玩 netball 对他来讲也不是很大的问题,因为两项运动的规则几乎是一样的。所以多任务学习是一个 brain-like functionality—可以在具有相关性的活动和任务之间探索相似性的学习模型。
事实上,多任务学习在许多领域都已经得到了实际的应用,实现了较好的落地,如医疗辅助决策,模式识别(人脸识别,语音识别等),以及金融预测等。由于多任务学习在多个学习任务之间具有知识共享的能力,所以相对于单任务学习来讲,其体现了意义非凡的优势。
多任务学习是学习两个或多个任务,一个在另一个之后或者在同一时间,而知识在任务中被迁移去提高学习效率。根据多任务学习的定义 [5] “in machine learning, when more than one task learning are required, the relatedness between tasks are often modelled to facilitate task learning with the prior knowledge retained in other correlated tasks learning. This type of sequential or parallel tasks learning with transfer learning between tasks is called multi-task learning”. It is also described as correlated multi-task learning in the literature (e.g., [1, 2, 3] and [4]). Rich Caruana [2] 阐述 “multi-task learning is a model to inductive transfer using prior information from primary tasks as inductive bias to improve performance of related secondary tasks”. 图 1 展示了一个相关的多任务学习概要。
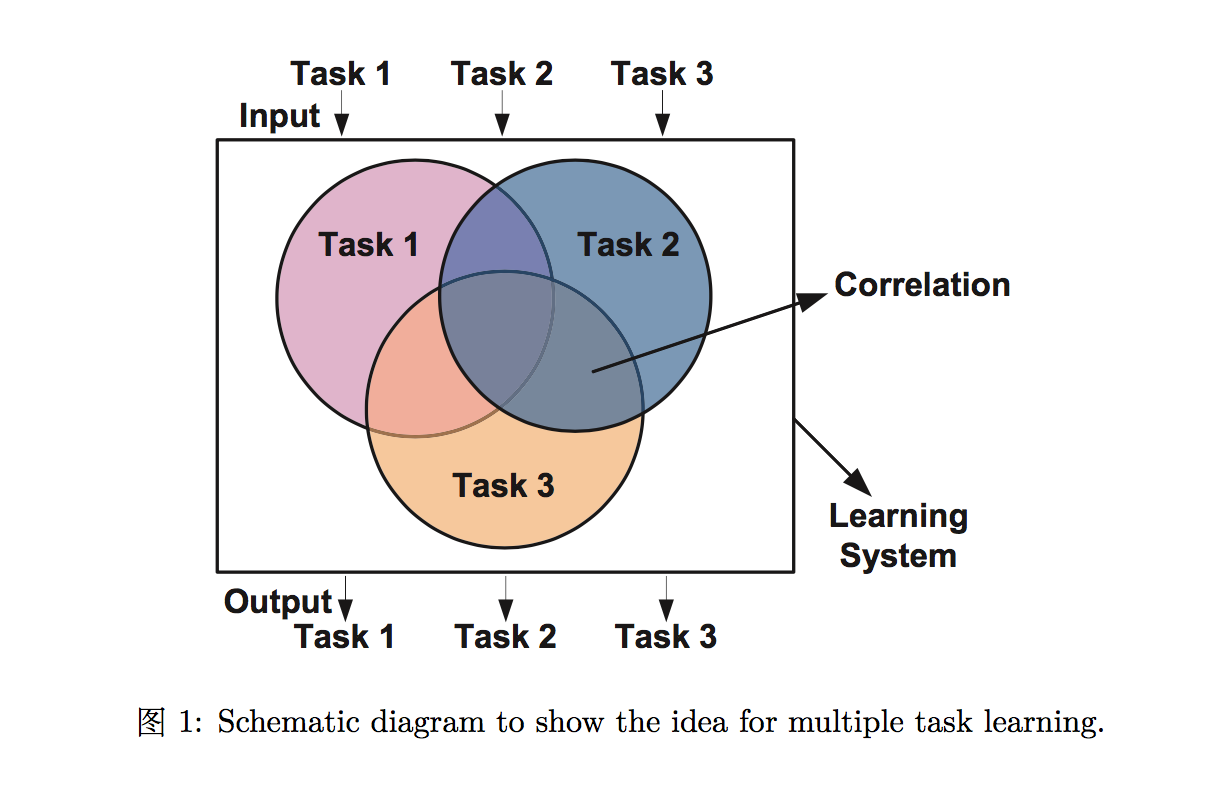
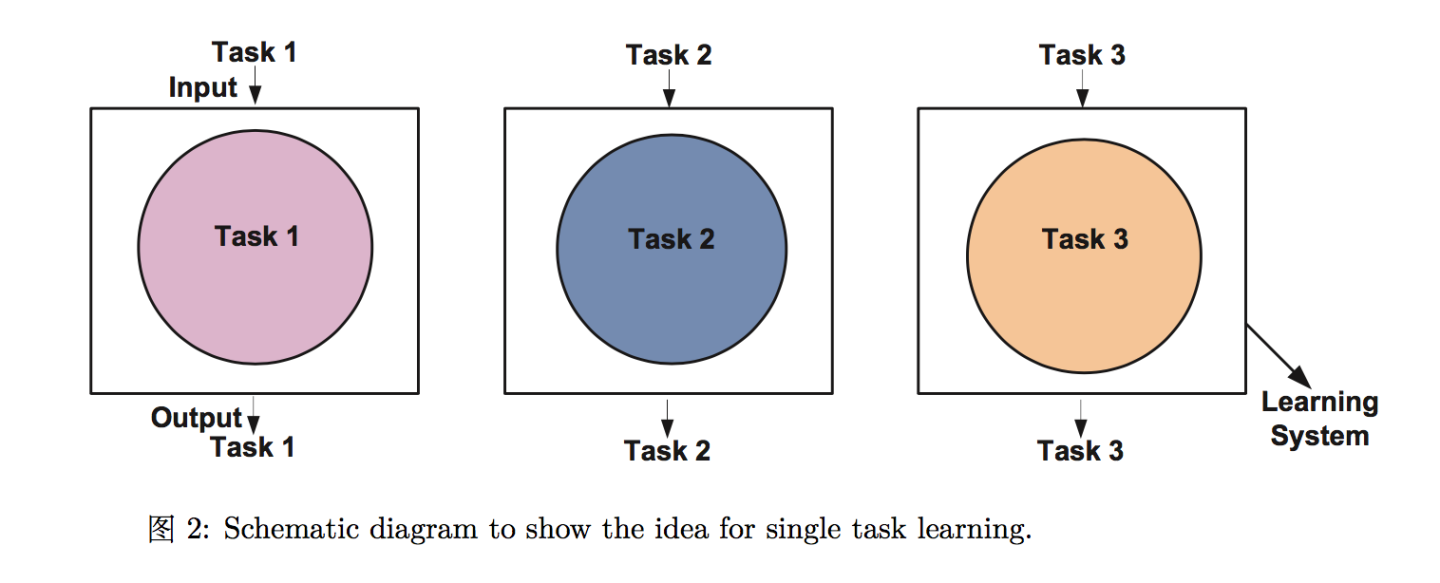
单任务学习是指建立学习一个任务的模型。图2展示了多个独立任务学习的概念。在一个单任务学习中,一个大问题通常被分割成许多小问题被单独和分开学习。学习系统很容易把从一个任务学来的知识在开始学习另一个的时候就弃掉了,而不是将相关的知识保留给其它任务去学习。这类模型忽略了可以在多个任务中相互分享的潜在的使用信息。
相对于单任务学习而言,多任务学习并不是简单的将多个单独的任务绑在一起。根据上面的定义,它在 2 个方面区别于单任务学习。一是学习任务是不相同的,例如人物身份确认和佩戴眼镜识别。人物身份确认是通过脸部图片分类辨认人物的身份。佩戴眼镜识别是辨识一张脸上是否佩戴眼镜。很显然,这两个任务不适合被合并和作为一个单任务问题。二是任务彼此之间是相关的。Baxter [15] 基于多任务共享一个通用假设类的方法已经证明了多任务学习的优点。换句话说,学习多于一个任务的先决条件是基于任务的相关性。
什么是迁移学习?迁移学习与多任务学习的关系
依据 Ozawa et al. (2009) 给出的定义,“If multiple tasks are related to one another, then the learning of a particular task among them can be speeded up if knowledge is transferred from another related task that has already been learned, such transfer of knowledge in-between two correlated tasks is called knowledge transfer”, and is also known as transfer learning [17] in the literature.
Baxter (2000) 已经展示了知识迁移的主要效率:当有几个相关的任务去学习的时候,知识迁移可以同时促进任务的学习过程。
值得注意的是多任务学习的定义也涉及了任务间的 transfer learning,但这已经是一个 “black box” 的过程,可以参考 [3, 25]。由于迁移学习的开发是基于一个特定的学习算法,我们是无法看到在多任务中“什么知识”被迁移和分享的。另一方面,单任务学习根本不允许在任务中进行迁移。
目前的迁移学习方法及其限制
多任务学习方法大部分来自于传统的机器学习算法,例如 kNN, SVM, MLP 等。Sebastian Thrun (1996) 提出了一个基于 kNN 的迁移学习方法去执行多任务。Evgeniou et al. (2004) 发表了基于 SVMs 的多任务学习机制。 Ando et al. (2005) 提供了一个使用贝叶斯模型的多任务学习方法。Ozawa et al. (2009) 给出了一个多任务模式识别模型是基于人工神经网络的。还有一些方法是最近非常火的 deep learning 方法[18],以上这些方法中,所有的任务都是被一个特定的 learner 学习。另一方面,Gao et al. [19] 开发了一个组合框架,把多个不同的分类器通过协作和调整的方式合并在一起。这个框架是基于权重的分配去整合不同学习算法的优点。可是,这个方法的限制是组合框架依旧使用通过固定的几个 learners 去达到迁移知识的目的的,和现有的多任务学习方法一样,唯一的不同在于它整合了多种分类器而不是仅仅使用某一个分类器。
多任务学习的核心是知识迁移的建模,一个理想的基于知识迁移的人工智能系统应该实现类脑功能。这个知识迁移背后的想法就是事实 – 人脑从之前的活动探索知识并作用于新的相关的活动上,例如上面提到 basketball and netball, and bicycle and motorcycle riding 的例子。对于之前已知的多任务学习,任务关联评估和迁移学习是通过建立一个特定 learner 进行的。这种迁移学习的过程是不透明的,因为迁移学习方法是特别针对一个固定种类的 learner,并且迁移的知识或特征对于另一种 learner 来讲,是不可利用的(即无法使用的)。
迁移学习的发展前景
在知识迁移领域,一个值得我们探究的方向就是迁移知识基于两个任务之间的相关,并有能力和任何一种 learner 一起使用。图 3 展示一个知识迁移在不拘泥于某一种 learner 的前提下,如何来应对多任务学习中两个相关的任务。给出输入数据 Task 1, 这个任务可以被建模成一个知识单元集。对于 Task 2 学习, 仅仅把 Task 1 中相关的知识单元集变成新知识喂给 Task 2。用这样的方式,系统解决 Task 1 的知识迁移给 Task 2。但没有任何 learner 种类的限制。
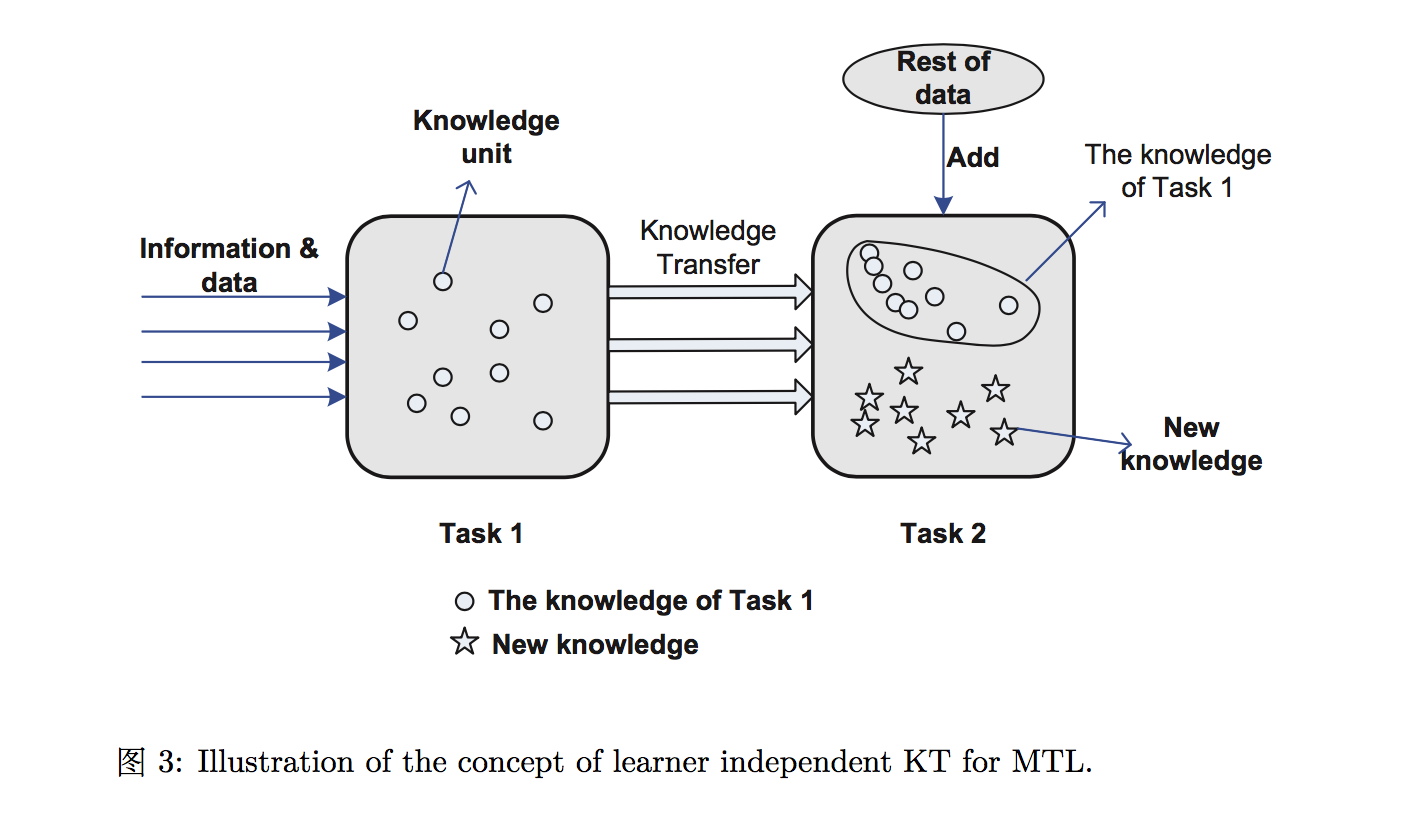
总结
对于多任务模式识别,多任务学习的成功取决于迁移学习(transfer learning)的效率。现有的迁移学习方法大多基于固有的 learner/classifier,无法将从迁移学习中获得的知识分享给其它 learners,这也局限了迁移学习领域主要的发展瓶颈。关于迁移学习的前景发展,其实是一种 independent learner 的知识共享方式,最大限度的发挥各 learner 之间的优势,接触 black box 的瓶颈。希望能有更多学者和研发工程师提出更多 novelty 的想法,每个人进步一小步,所有人累加在一起就会让这个领域前进一大步。
最后,对于迁移学习领域的一些高阶问题,在此我们也做了一些探讨,希望对专业领域的朋友有更进一步的帮助。
下面我们深入讨论多任务学习中的任务相关性(Task Relatedness)。如果想打破拘泥于某一种 learner 的 transfer learning,那么需要有一个 task relatedness measurement 并且抽取相关 feature 给其它任务。在多任务学习中,多个任务之间具有 correlation, 相关度越高,transfer 的效果应该越好,这里需要对 task relatedness 做一个 measurement。这一类的 transfer 和 extract 是在数据的 physical layer 进行,而并非在一个 functional layer,所以它不需要嵌入到一个特定 learner 去实现多任务学习。
1. Measure Task Relatedness
这里主要介绍一下评估任务相关度的思路 – 在基于特征的高维空间中,多个相关的任务共享一些相同的输入数据,这些输入数据依赖于多任务之间的 overlapping regions 的特征空间。主要的想法是找出相关知识或特征 – 多任务的相交空间 – 并迁移相关的数据而无视 learner 的使用。下面 measure task relatedness, 这里使用数学方式进行表达:


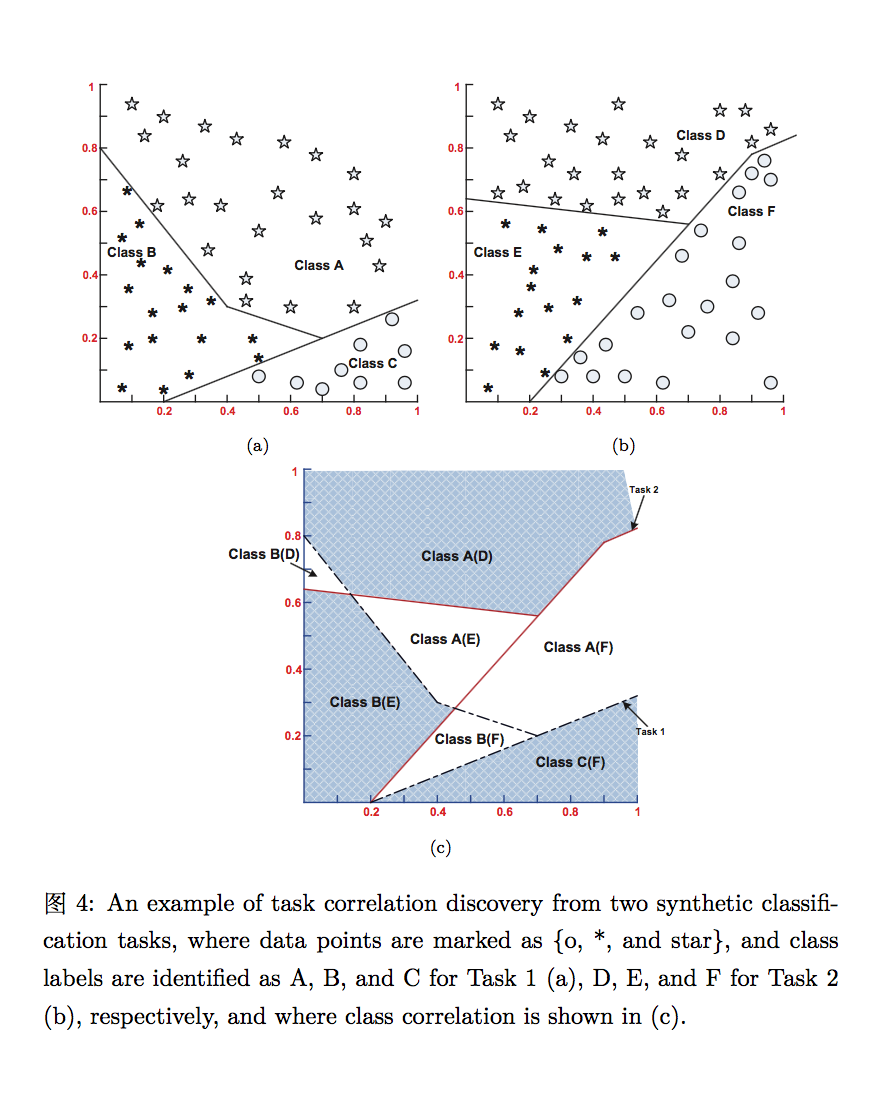
2. Relatedness Interpretation for MTL
根据上面定义的多个任务中,physical layer overlapping 在一起的数据从一个学习任务 extract 出来并插入至另一个学习任务,彼此间可以 mutually learn/use 相互的知识和特征,以达到 independent 知识迁移的多任务学习。这里对多任务学习中的相关度插入法(relatedness interpretation)进行建模:


参考文献
[1] Y. S. Abu-Mostafa, “Learning from hints in neural networks,” J. Complexity, vol. 6, no. 2, pp. 192–198, 1989.
[2] R. Caruana, “Multitask learning,” Machine Learning, vol. 28, pp. 41– 75, 1997.
[3] S. Thrun, “Is learning the n-th thing any easier than learning the first?” in Advances in Neural Information Processing Systems. The MIT Press, 1996, pp. 640–646.
[4] S. Thrun and L. Pratt, Learning to Learn. Norwell, MA: Kluwer Academic Publishers, 1998.
[5] O. Seiichi and R. Dmitri, “A multitask learning model for online pattern recognition,” IEEE Transaction on neural networks, vol. 20, no. 3, pp. 430 – 445, 2009.
[6] L. Y. Pratt, “Artificial neural networks for speech and vision.” Chap- man and Hall, 1993, pp. 143–169.
[7] K. Yu, A. Schwaighofer, V. Tresp, W.-Y. Ma, and H. Zhang, “Collaborative ensemble learning: Combining collaborative and content-based information filtering via hierarchical bayes,” in Proceedings of the 19th Conference on Uncertainty in Artificial Intelligence, 2003.
[8] J. Ghosn and Y. Bengio, “Bias learning, knowledge sharing,” IEEE Trans. Neural Netw., vol. 14, no. 4, pp. 748–765, 2003.
[9] S. Thrun and J. O’Sullivan, “Discovering structure in multiple learning tasks: The tc algorithm,” 1996.
[10] Eaton, E and desJardins, M., “Knowledge Transfer with a Multiresolution Ensemble of Classifiers,” in ICML-06 Workshop on Structural Knowledge Transfer for Machine Learning, June 29, Pittsburgh, PA., 2006.
[11] Eaton, Eric, “Multi-Resolution Learning for Knowledge Transfer,” in AAAI, 2006.
[12] Eaton, Eric and desJardins, Marie and Stevenson, John, “Using multiresolution learning for transfer in image classification,” in AAAI, 2007.
[13] M. Badoiu, “Optimal core sets for balls,” in In DIMACS Workshop on Computational Geometry, 2002.
[14] P. Kumar, J. S. B. Mitchell, and E. A. Yildirim, “Approximate minimum enclosing balls in high dimensions using core-sets,” Journal of Experimental Algorithmics (JEA), vol. 8, p. 11, 2003.
[15] Jonathan Baxter, “A Model of Inductive Bias Learning,” Journal of Artificial Intelligence Research, vol. 12, p. 149–198, 2000.
[16] Daniel, L S and Robert, E M, “Selective Functional Transfer: Inductive Bias from Related Tasks,” 2002.
[17] Pan, Sinno Jialin and Yang, Qiang, “A Survey on Transfer Learning,” Knowledge and Data Engineering, IEEE Transactions, vol. PP, p. 1–1, 2009.
[18] Ruben Glatt and Anna Helena Reali Cost, “Improving Deep Reinforcement Learning with Knowledge Transfer,” Proceedings of the Thirty- First AAAI Conference on Artificial Intelligence (AAAI’2017), p. 5036- 5037, 2017.
[19] Jing Gao and Wei Fan and Jing Jiang and Jiawei Han, “Knowledge Transfer via Multiple Model Local Structure Mappingg,” Proceeding of the 14th ACM SIGKDD international conference on Knowledge discovery and data mining, p. 283-291, 2008.
[20] Y. Chen, S. Pang, and K. Nikola, “Hierarchy minimum enclosing balls for multi-label classification with reference to intrusion detection,” 2009.
[21] B. Jonathan, “Learning internal representations,” in Proceedings of the Eighth International Conference on Computational Learning Theory, 1995.
[22] N. Intrator and S. Edelman, Making a low-dimensional representation suitable for diverse tasks. Norwell, MA, USA: Kluwer Academic Publishers, 1998.
[23] X. Ya, L. Xuejun, and C. Lawrence, “Multi-task learning for classification with dirichlet process priors,” The Journal of Machine Learning Research, vol. 8, pp. 35 – 63, 2007.
[24] R. K. Ando and T. Zhang, “A framework for learning predictive structures from multiple tasks and unlabeled data,” The Journal of Machine Learning Research, vol. 6, pp. 1817–1853, 2005.
[25] T. Evgeniou and M. Pontil, “Regularized multi–task learning,” in Proceedings of the tenth ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2004, pp. 109–117.
[26] L. S. Daniel and P. Ryan, “Sequential consolidation of learned task knowledge,” 2004.
[27] S. Ben-David and R. Schuller, “Exploiting task relatedness for multiple task learning,” in Proceedings of Computational Learning Theory (COLT), 2003.
[28] I. W. Tsang, J. T. Kwok, and P.-M. Cheung, “Core vector machines: Fast svm training on very large data sets,” The Journal of Machine Learning Research, vol. 6, pp. 363 – 392, 2005.
[29] E. Welzl, “Smallest enclosing disks (balls and ellipsoids),” Results and New Trends in Computer Science, pp. 359–370, 1991.
[30] O. Chapelle, B. Scholkopf, and A. Zien, Semi-supervised learning. Cambridge, MA: MIT Press, 2006.
[31] M. Kim, D. Kim, S. Bang, and S. Lee, “Face recognition descriptor using the embedded hmm with the 2nd-order block-specific eigenvectors,” ISO/IEC JTC1/SC21/WG11/M7997, Jeju, 2002.
原文:https://zhuanlan.zhihu.com/p/28732079
既然来了,说些什么?