面向设计师的机器学习
介绍
从计算机诞生之日起,我们就梦想着(也曾梦见)能像我们一样思考和说话的机器。但我们在过去几十年里使用的电脑与哈尔9000或萨曼莎的电脑相去甚远。尽管如此,机器学习仍处于复兴期,它将改变无计数行业,并为设计师提供各种各样的新工具,以便更好地与用户接触和理解用户。这些技术将带来新的设计挑战,并需要对用户界面和交互设计进行新的思考。
为了充分利用这些系统巨大的技术能力,设计师需要与程序员建立更深入的合作关系。随着这些复杂技术从研究原型发展到面向用户的产品,程序员也将依赖设计师来发现这些系统的迷人应用。
在下文中,我们将探讨机器学习系统的一些技术特性和限制,以及它们对面向用户的设计的影响。我们将研究设计师如何围绕这些技术开发交互范例和设计词汇,并考虑设计师如何开始将机器学习的力量融入到他们的工作中。
为什么机器学习的设计是不同的
另一种逻辑
在我们的日常交流中,我们通常使用逻辑学家所说的模糊逻辑。这种逻辑形式与近似推理有关,而不是精确推理。例如,我们可以将一个对象标识为“非常小”、“略红”或“非常近”这些陈述没有确切的含义,而且往往与上下文有关。当我们说汽车很小时,这意味着与我们说行星很小时的规模非常不同。用这些术语描述一个对象需要对特定意义域内可能存在的价值范围有辅助知识。如果我们只见过一辆车,我们就无法区分小型车和大型车。即使我们见过几辆车,我们也不能很有把握地说我们知道各种可能的汽车尺寸。有了足够的经验,我们永远无法完全确定我们看到的是所有汽车中最小和最大的,但我们可以相对确定的是,我们有一个很好的近似范围。由于我们周围的人往往对汽车有着相对相似的体验,我们可以用模糊的术语彼此进行有意义的讨论。
然而,传统上,计算机无法获得这种辅助知识。相反,他们过着经验匮乏的生活。因此,传统的计算平台被设计为在逻辑表达式上运行,这些表达式可以在不知道任何外部因素的情况下进行计算,这些外部因素超出了明确提供给它们的因素。尽管传统平台可以通过程序员或用户对模糊术语(如“非常小”)的明确描述来使用模糊逻辑表达式,但这些系统通常被设计为处理布尔逻辑(也称为“二进制逻辑”),在布尔逻辑中,每个表达式最终都必须计算为真或假。我们将在下一节中进一步讨论这种方法的一个基本原理是,布尔逻辑允许将计算机程序的行为定义为一组有限的具体状态,从而更容易构建和测试以可预测的方式运行并完全符合其程序意图的系统。
机器学习通过提供在计算系统上传授经验知识的机制来改变这一切。这些技术使机器能够处理更模糊、更复杂或“人类”的概念,但也带来了各种各样的设计挑战,这些挑战与使用不精确的术语和不可预测的行为有时会产生问题有关。
另一种发展
在传统编程环境中,开发人员使用布尔逻辑明确描述程序的每个可能状态,以及用户能够在这些状态之间转换的确切条件。这类似于一本“选择你自己的冒险”的书,书中有这样的说明:“如果你想让王子与龙搏斗,请翻到第32页。”在代码中,如果满足一些预定义的条件集,则使用条件表达式(也称为if语句)将用户移动到代码的特定部分。
在伪代码中,条件表达式可能如下所示:
if ( mouse button is pressed and mouse is over the ‘Login’ button ),
then show the ‘Welcome’ screen
由于程序包含有限数量的状态和转换,可以显式地枚举和检查,因此程序的整体行为应该是可预测的、可重复的和可测试的。当然,这并不是说,传统的编程逻辑不能包含难以预见的“边缘情况”,这些情况会在程序员尚未解决的特定条件下导致未定义或不受欢迎的行为。然而,不管在一个复杂的软件中识别这些有问题的边缘情况有多困难,至少在概念上,可以系统地探索“选择你自己的冒险”中的每一条可能路径,并通过改变或附加程序明确定义的逻辑来防止用户进入不希望的状态。
另一方面,机器学习系统的行为并不是通过这种显式编程过程来定义的。机器学习系统不是使用一组明确的规则来描述程序的可能行为,而是在一组示例行为中寻找模式,以便生成规则本身的近似表示。
这个过程有点像我们自己学习周围世界的心理过程。早在我们遇到任何正式的在描述物理学的“定律”时,我们通过观察我们与物理世界互动的结果来学习在这些定律中操作。孩子可能不知道牛顿方程式,但通过反复观察和实验,孩子会逐渐认识到物体物理性质和行为之间关系的模式。
虽然这种方法为学习在复杂系统上操作提供了一种极其有效的机制,但它并没有产生一套具体或明确的规则来管理该系统。在人类智能的背景下,我们通常将其称为“直觉”,即在不能够正式阐述实现某些预期结果的程序的情况下,对复杂系统进行操作的能力。根据经验,我们提出了一套近似或临时规则,称为启发式(或“经验法则”),并在此基础上进行操作。
在机器学习系统中,这些隐式定义的规则与传统编程语言的显式定义的逻辑表达式完全不同。相反,它们由分布式表示组成,这些表示隐含地描述了复杂系统中一组相互关联的组件之间的概率连接。
机器学习通常需要大量的例子来产生对复杂系统行为的强烈直觉。
从某种意义上说,这一要求与边缘案例问题有关,边缘案例在机器学习环境中提出了一系列不同的挑战。正如很难想象一组规则的每一个可能结果一样,反过来,也很难从一组示例结果中推断出每一个可能的规则。为了推断规则的良好近似性,学习者必须观察其应用的许多变化。学习者必须接触到系统中更极端或不太可能的行为,以及最可能的行为。或者,正如教育哲学家帕特里夏·卡里尼(Patricia Carini)所说,“让意义发生需要时间,需要事物之间丰富多样的关系变得明显的可能性。”
虽然直觉型学习者可能在死记硬背的程序性任务(如由计算器执行的任务)上速度较慢,但他们能够执行更复杂的任务,而这些任务不适合进行精确的程序。尽管如此,即使进行了大量的培训,这些直观的方法有时也会让我们失望。例如,我们可能会发现自己在云层或烤奶酪三明治中错误地识别人脸。
另一种精确度
传统编程语言设计中的一个关键原则是,只要编程人员正确使用每个功能,每个功能都应该以可预测、可重复的方式工作。无论我们做多少次算术运算,比如“2+2”,我们都应该得到相同的答案。如果这是不真实的,那么我们正在使用的语言或工具中就存在一个bug。虽然一种编程语言包含一个bug并不是不可想象的,但它相对较少,而且几乎永远不会涉及像算术运算符那样常用的运算。为了确保常规代码能够按预期运行,大多数大型代码库都附带了一组正式的“单元测试”,可以在安装时在用户的机器上运行,以确保系统的功能完全符合开发人员的期望。
所以,撇开罕见的错误不谈,传统编程语言可以被认为是一个系统,它对具体的数学运算等日常事物总是正确的。另一方面,机器学习算法可以被认为是一种系统,它通常能正确处理更复杂的事情,比如识别图像中的人脸。由于机器学习系统被设计为概率地近似一组已证明的行为,其本质通常阻止它以完全可预测和可复制的方式进行行为,即使它已经在大量示例上进行了适当的训练。当然,这并不是说,一个训练有素的机器学习系统的行为必然会天生不稳定到有害的程度。相反,在机器学习增强型系统的设计中,应该理解并考虑到,它们处理异常复杂的概念和模式的能力也具有一定程度的不精确性和不可预测性,超出了传统计算平台的预期。
在本文的后面,我们将更详细地介绍一些在机器学习系统中处理不精确和不可预测行为的设计策略。
另一种问题
机器学习可以完成传统计算平台无法完成的复杂任务。然而,培训和使用机器学习系统的过程通常比开发传统系统的过程带来更大的开销。因此,虽然机器学习系统可以被教导执行简单的任务,比如算术运算,但作为一般经验法则,只有在没有可行的常规方法存在的情况下,才应该对给定的问题采用机器学习方法。
即使对于非常适合机器学习解决方案的任务,也有许多关于使用哪种学习机制以及如何管理培训数据的考虑,以便学习系统能够最容易理解这些数据。
在接下来的章节中,我们将更仔细地研究如何识别适合机器学习解决方案的问题,以及将学习算法应用于特定问题的众多因素。但就目前而言,我们应该理解机器学习在解决可以用一组示例概括,但不容易用正式术语描述的问题时是有用的。
什么是机器学习?
识别物体的心理过程
想想你自己识别人脸的心理过程。这是一种天生的、自动的行为,很难用具体的术语来思考。但这种困难不仅仅是因为你已经完成了很多次任务。我们可以具体地表达许多其他经常重复的过程,比如如何刷牙或炒鸡蛋。相反,几乎不可能描述识别人脸的过程,因为它涉及一组极其庞大而复杂的相互关联因素的平衡,因此无法将其具体描述为一系列步骤或规则。
首先,不同种族、年龄和性别的人的面部特征有很大差异。此外,在无数的照明场景和周围环境中,每个人都可以从无数的有利位置观看。在评估我们所看到的物体是否是人脸时,我们必须考虑这些属性之间的相互关系。当我们改变面部周围的有利位置时,鼻子相对于眼睛的比例和相对位置也会发生变化。随着面部靠近或远离其他物体和光源,其颜色和对比区域也会发生变化。
有无限多个属性组合可以有效识别人脸,也有同样多的属性组合无法识别人脸。分隔这两个组的规则集太复杂,无法通过条件逻辑来描述。我们能够几乎自动地识别人脸,因为我们在观察可见世界和与可见世界互动方面的丰富经验,使我们能够建立一套启发式方法,用于快速、直观、但有些不精确地衡量特定属性的表达是否处于形成人脸的正确平衡状态。
通过一个例子学习
在逻辑学中,有两种主要的方法来推理一组特定的观察结果和一组一般规则是如何相互关联的。在演绎推理中,我们从关于系统规则的广泛理论开始,将该理论提炼为更具体的假设,收集具体的观察结果,并根据我们的假设进行测试,以确认原始理论是否正确。在归纳推理中,我们从一组特定的观察者开始,在这些观察中寻找模式,制定初步假设,并最终尝试产生一个包含原始观察的一般理论。关于这两种推理形式之间的差异,请参见图1-1。
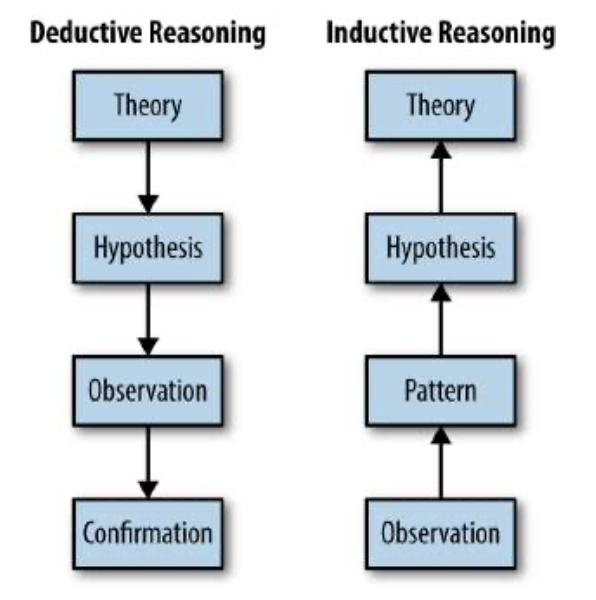
图1-1 演绎推理与归纳推理
这些方法中的每一种都在科学探究中发挥着重要作用。在某些情况下,我们对管理一个系统的原则有一个大致的认识,但需要确认我们的信念在许多具体情况下都是正确的。在其他情况下,我们进行了一系列观察,并希望发展一个解释这些观察的一般理论。
在很大程度上,机器学习系统可以被视为辅助或自动化归纳推理过程的工具。在一个由少量规则控制的简单系统中,通常很容易从几个具体的例子中得出一般的理论。将图1-2作为此类系统的示例。
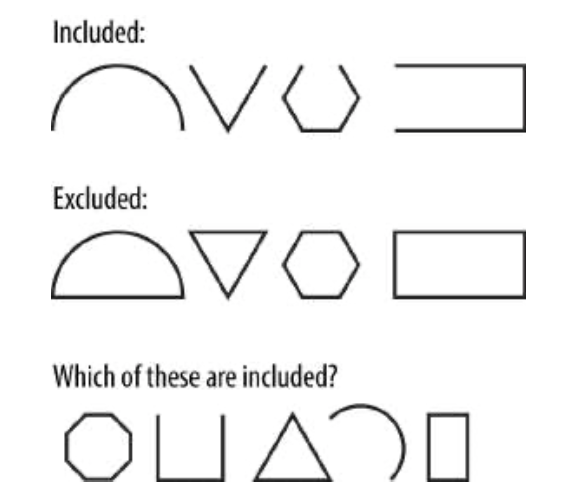
图1-2 一个简单的系统
在这个系统中,你应该可以毫不费力地发现控制包含的单一规则:包括开放图形,排除封闭图形。一旦被发现,你可以很容易地将这条规则应用于最下面一行的未分类数字。
在图1-3中,您可能需要更仔细地观察。
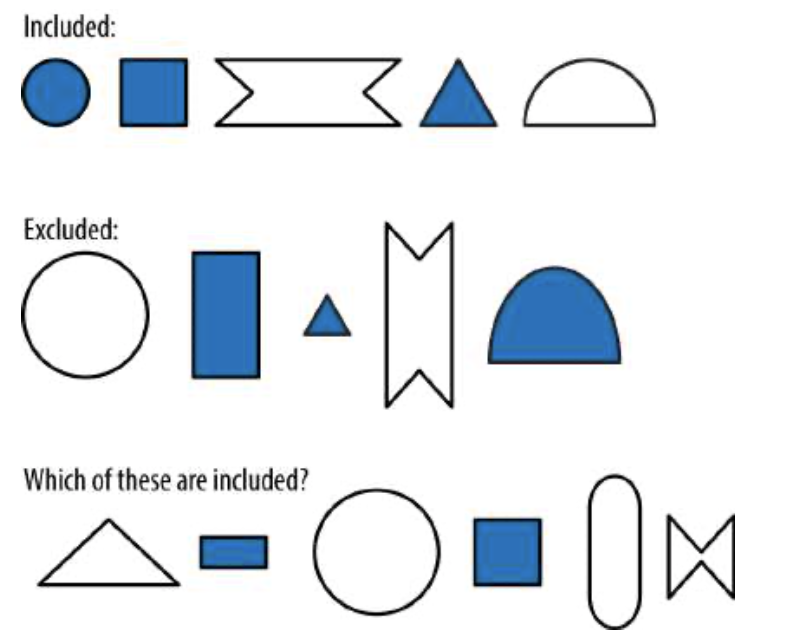
图1-3 更复杂的系统
在这里,似乎涉及到更多的变量。你可能已经考虑了每个人物的形状和底纹,然后才发现实际上这个系统也由一个单一属性控制:人物的高度。如果你花了一点时间才发现规则,很可能是因为你花了时间考虑那些似乎与决定相关但最终不相关的属性。这种“噪声”存在于许多系统中,使得分离有意义的属性变得更加困难。
现在让我们考虑图1-4。
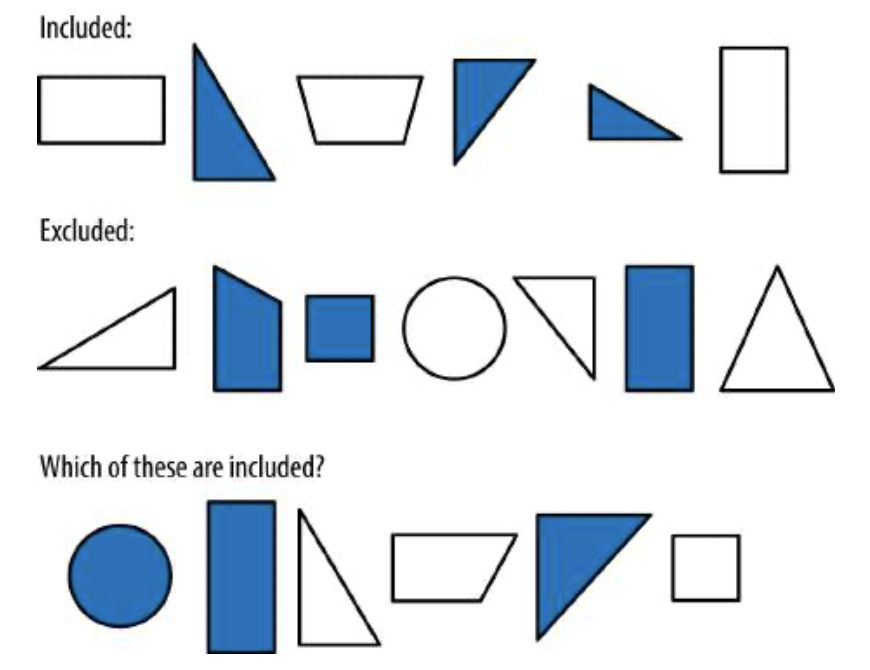
图1-4 更复杂的系统
在这个图表中,规则实际上变得更加复杂。这里包括带阴影的三角形和不带阴影的四边形,不包括所有其他图形。这个规则体系更难揭示,因为它涉及数字的两个属性之间的相互依赖性。形状和阴影都不能单独决定包容性。三角形的包含取决于其着色,着色图形的包含取决于其形状。在机器学习中,这被称为线性不可分割问题,因为不可能使用单个“线”或确定属性来分离包含的图形和排除的图形。线性不可分割的问题对于机器学习系统来说更难解决,而且需要几十年的研究才能发现处理这些问题的可靠技术。见图1-5。
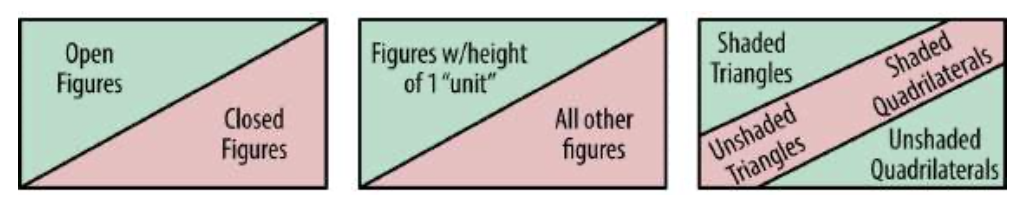
图1-5 线性可分与线性不可分问题
一般来说,归纳推理问题的难度与涉及的相关和不相关属性的数量以及相关属性的微妙性和相互依赖性有关。许多现实问题,比如人脸识别,都涉及大量相互关联的属性和大量噪音。在人类历史的绝大部分时间里,这种问题已经超出了机械自动化的范围。机器学习的出现以及从特定信息自动合成复杂系统的一般知识的能力具有深远的意义。对于设计师来说,这意味着能够通过用户与我们构建的界面和体验的交互,更全面地理解用户。这种理解将使我们能够更好地预测和满足用户的需求,提升他们的能力,扩大他们的影响范围。
机械归纳法
为了更好地了解机器学习算法实际上是如何执行归纳的,让我们考虑图1-6。

图1-6 相当于布尔逻辑表达式“AND”的系统
这个系统相当于布尔逻辑表达式“AND”也就是说,只包括阴影和闭合的图形。在我们把注意力转向感应之前,让我们首先从演绎的角度考虑如何在电气系统中实现这种逻辑。换句话说,如果我们已经知道这个系统的规则,我们如何实施一个电气装置来决定是否应该包括或排除某个特定的数字?
见图1-7。
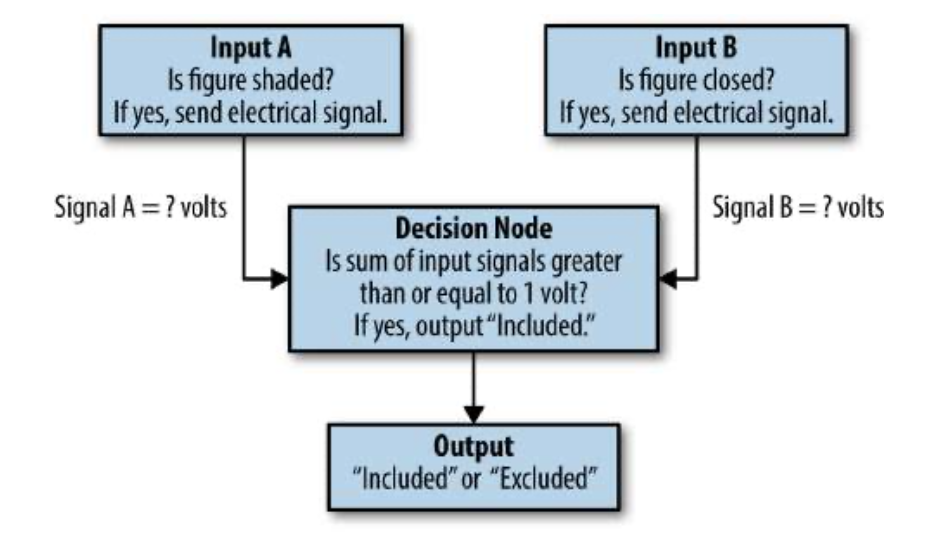
图1-7 一个布尔逻辑表达式,表示为一个电路
在这个图中,我们有一条从每个输入属性到“决策节点”的连线如果给定图形为阴影,则会通过输入a的导线发送电信号。如果图形闭合,则会通过输入B的导线发送电信号。如果输入信号的总和大于或等于1伏,决策节点将输出一个电信号,指示该图形被包括在内。
为了实现与门的行为,我们需要设置与两个输入信号中的每一个相关的电压。由于输出阈值为1伏,我们只希望在两个输入都激活时触发输出,因此我们可以将每个输入的相关电压设置为0.5伏。在此配置中,如果只有一个或两个输入均未激活,则不会达到输出阈值。现在设置了这些信号电压,我们已经实现了控制系统的一般规则的机制,并且可以使用这个电子设备来推断任何示例输入的正确输出。
现在,让我们从归纳的角度来考虑同样的问题。在本例中,我们有一组示例输入和输出,它们示例了一条规则,但不知道该规则是什么。我们希望通过这些例子来确定规则的性质。
让我们再次假设决策节点的输出阈值为1伏。为了通过感应再现与门的行为,我们需要找到输入信号的电压电平,该电平将为每对示例输入产生预期输出,告诉我们这些输入是否包含在规则中。发现正确电压组合的过程可视为一种搜索问题。
我们可能采取的一种方法是为输入信号选择随机电压,使用这些电压预测每个示例的输出,并将这些预测与给定的输出进行比较。如果预测与正确的输出相匹配,那么我们已经找到了良好的电压水平。如果没有,我们可以选择新的随机电压,重新开始这个过程。然后重复这个过程,直到对每个输入的电压进行加权,以便系统能够一致地预测每个输入对是否符合规则。
在这样一个简单的系统中,猜测和检查方法可以让我们在合理的时间内获得合适的电压。但对于一个涉及更多属性的系统,信号电压可能组合的数量将是巨大的,我们不太可能有效地猜测合适的值。每增加一个属性,我们就需要在越来越大的草堆中寻找一根针。
我们可以采用迭代方法,而不是随机猜测,在结果不合适时重新开始。我们可以从随机值开始,检查它们产生的输出预测。但是,如果结果不准确,我们不必从头开始,而是可以看看不准确的程度和方向,并尝试逐步调整电压,以产生更准确的结果。上面概述的过程是对最早的机器学习系统之一所使用的学习过程的简化描述,称为感知器(图1-8),由Frank Rosenblatt在1957年发明
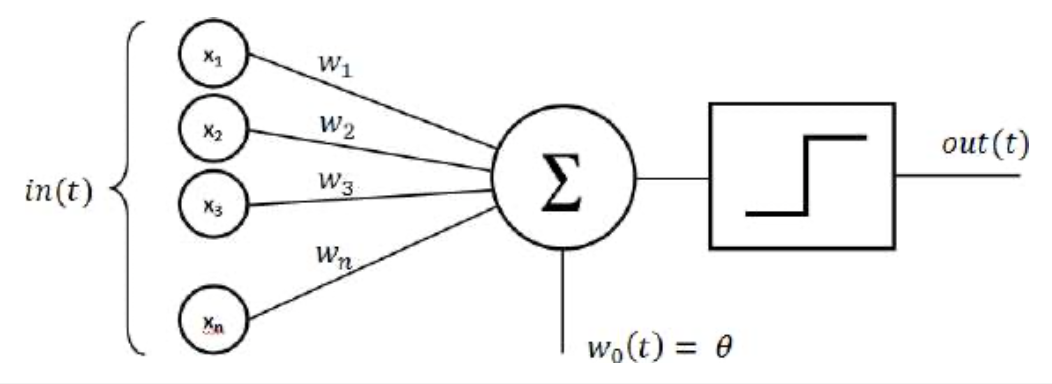
图1-8 e感知器的体系结构
一旦感知器完成了归纳学习过程,我们就有了一个隐式描述规则系统的电压等级网络。我们称之为分布式表示。它可以产生正确的输出,但很难观察分布式表示并明确理解规则。就像我们自己的神经网络一样,这些规则被隐式或印象式地表达出来。尽管如此,它们还是达到了预期的目的。
虽然感知机能够在简单系统上执行归纳学习,但它们不能解决线性不可分解问题。为了解决这类问题,我们需要考虑属性之间的相互依赖关系。在某种意义上,我们可以把相互依赖看作是一种属性本身。然而,在复杂的数据中,仅仅通过查看数据往往很难发现相互依赖关系。因此,我们需要某种方式来允许学习系统发现并解释这些相互依赖关系。这可以通过在输入和输出之间添加一层或多层节点来实现。这些“隐藏”节点的明确目的是描述数据的具体(或“可见”)属性之间的关系中可能隐藏的相互依赖关系。添加这些隐藏节点使归纳学习过程变得更加复杂。
反向传播算法是在20世纪60年代末开发的,但直到1986年David Rumelhart等人的一篇论文4才得到充分利用,它可以对线性不可分问题进行归纳学习。有兴趣进一步了解这些想法的读者,请参阅第67页的“进一步”一节。
机器学习常见类比
生物系统
当列奥纳多·达芬奇开始设计飞行器时,他自然而然地在他那个时代唯一的飞行器上寻找灵感:有翼动物。他研究了鸟类的稳定羽毛,观察了翅膀形状的变化如何用于转向,并为由人类“拍打翅膀”驱动的机器绘制了许多草图
最终,事实证明,围绕旋转涡轮的机械装置设计飞行器比直接模拟鸟类拍打翅膀的运动更实用。然而,从达芬奇开始,人类设计师从他们对生物系统的观察中得出了许多关键的飞行原理和机制。毕竟,大自然在解决这个问题上有一个领先的开端,我们忽视它的发现是愚蠢的。
类似地,由于我们能接触到的唯一的智能例子是这个星球上的生物,因此机器学习研究人员在学习和智能的指导原则和具体设计机制方面都将目光投向了生物系统,这也就不足为奇了。
在1950年的一篇著名论文《计算机械与智能》中,计算机科学界的杰出人物艾伦·图灵思考了机器是否可以用来思考的问题。意识到“思想”是一个很难定义的概念,图灵提出了一种他认为是密切相关且毫不含糊的方式来重新定义这个问题:“有没有可以想象的数字计算机在模仿游戏中表现良好?”在提议的游戏中,现在通常被称为图灵测试,人类审问者向人类和机器提出书面问题。如果审问者无法根据对这些问题的回答确定哪一方是人类,那么可以推断机器是智能的。在这种方法的框架中,很明显,自该领域诞生以来,系统与生物产生的智能的相似性一直是评估机器智能的核心指标。
在该领域的早期历史中,曾多次尝试开发模拟人脑工作的模拟和数字系统。威廉·罗斯·阿什比(William Ross Ashby)于1948年开发的恒速调节器就是这样一种模拟设备,它使用机电过程来检测和补偿物理空间的变化,以创造稳定的环境条件。1959年,赫伯特·西蒙(Herbert Simon)、J.C.肖(J.C.Shaw)和艾伦·纽厄尔(Allen Newell)开发了一个名为通用问题求解器(General Problem Solver)的数字系统,可以自动生成形式逻辑问题的数学证明。该系统能够解决简单的测试问题,如河内塔难题,但由于其基于搜索的方法在解决更复杂的问题时需要存储大量难以处理的组合,因此无法很好地扩展。
随着该领域的成熟,机器学习算法的一个主要类别特别关注于模仿生物学习系统:适当命名的人工神经网络(ANN)。这些机器,包括感知机以及本文后面讨论的深度学习系统,是模仿生物系统建模的,但实现方式与生物系统不同。见图1-9。
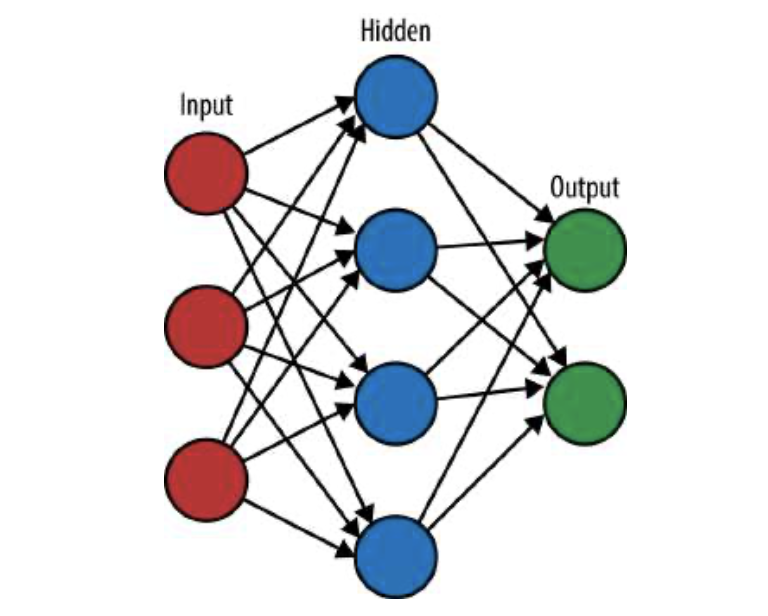
图1-9 e模拟人工神经网络的神经元
人工神经网络不是由生物神经元执行的电化学过程,而是利用传统的计算机电路和代码来生成神经结构和活动的简化数学模型。人工神经网络在接近人类的高级和广义智能方面还有很长的路要走。就像鸟类和飞机之间的关系一样,我们可能会继续寻找偏离生物系统特定机制的实际原因。尽管如此,人工神经网络还是从生物学同行那里借鉴了很多想法,并将随着神经科学和机器学习领域的发展而继续这样做。
热力学系统
机器学习的一个间接结果是,生产实用学习机器的努力也导致了对学习和智力本质上是什么现象的更深入的哲学理解。在科幻小说中,我们倾向于假设所有高级智能都与我们自己相似,因为我们没有显著不同的智能例子可供借鉴。
出于这个原因,了解到机器学习中使用的数学模型的主要灵感之一来自热力学领域可能会令人惊讶,热力学是物理学中与热和能量传递有关的一个分支。虽然我们肯定会把热系统的行为称为复杂的,但我们通常并不认为这些系统与智能和生命的基本原理有着密切的关系。
从我们之前对归纳推理的讨论中,我们可以看到,学习在很大程度上与在许多相互关联的因素之间找到平衡的渐进或迭代过程有关。这一过程与热系统寻求平衡的趋势之间的实际关系,使得机器学习研究者能够采用热力学中建立的一些思想和方程来模拟学习的特征。
当然,我们选择称之为“智力”或“生命”的东西,更重要的是语言问题。然而,在更广泛的背景下看到这些现象并理解大自然有一种方法可以在许多不同的应用程序中重用某些原则,这是很有趣的。
电气系统
到了20世纪初,科学家们已经开始认识到,大脑在体内存储记忆和触发动作的能力是由神经元之间的电信号传输产生的。到本世纪中叶,包括感知器在内的几个用于模拟单个神经元电行为的初步模型已经开发出来。正如我们在“生物系统”一节中看到的,这些模型与构成电子系统基本构件的逻辑门有一些重要的相似之处。在其最基本的概念中,单个神经元从引入它的其他神经元收集电信号,并在其足够多的输入被电激活时将电信号转发给其连接的输出神经元。
这些早期的发现大大高估了我们制造真正人工智能的难度。随着神经科学和机器学习领域的发展,我们逐渐认识到,理解单个神经元的电行为和潜在的数学特性,只能阐明大脑整体工作的一个小方面。艾伦·图灵(Alan Turing)在描述一台有点像感知器的简单学习机器的机制时说:“一台机器只有这么少的单元,其行为自然是非常微不足道的。然而,当单元数很大时,这种性质的机器可以以非常复杂的方式运行。”
尽管神经网络和传统电子系统的基本构造块有一些相似之处,但它们在组合基本构造块以产生更复杂的行为时使用了非常不同的原理。电子元件有助于通过显式逻辑决策路径路由电信号,其方式与传统计算机程序大致相同。另一方面,单个神经元用于存储归纳近似规则系统的分布式表示的小块。
我们不应该像研究电子系统或神经网络的扩展那样,在真正意义上的机器和学习系统之间进行仔细研究。
学习方式
在机器学习中,术语有监督、无监督、半监督和强化学习用于描述各种模型和算法的学习方式及其学习内容的一些关键差异。机器学习领域还使用了许多其他术语来描述其他重要的区别,但这四个类别为讨论机器学习系统的主要类型提供了基本词汇:
监督学习程序用于我们可以为系统提供示例输入及其相应输出的问题,并希望诱导控制这些相关性的规则或函数的隐式近似。这类程序是“监督”的,因为我们明确指出应该找到什么相关性,只询问机器如何证实这些相关性。经过培训后,有监督学习系统应该能够预测输入示例的正确输出,该输入示例在性质上与培训示例相似,但没有明确包含在其中。监督学习过程可以解决的问题通常分为两类:分类问题和回归问题。在分类问题中,输出与一组离散类别相关。例如,我们可能有一个手写字符的图像,并希望确定它代表26个可能的字母中的哪一个。在回归问题中,输出与实数有关。例如,基于一组财务指标和过去的业绩数据,我们可以尝试猜测特定股票的未来价格。
无监督学习程序不需要一组已知输出。相反,机器的任务是在训练示例中查找内部模式。这类程序是“无监督的”,因为我们没有明确指出系统应该了解什么。相反,我们提供了一组我们认为包含内部模式的培训示例,并让系统自行发现这些模式。一般来说,无监督学习可以帮助我们理解极其复杂的系统,这些系统的内部模式可能过于复杂,人类无法自行发现。无监督学习也可用于生成生成模型,例如,可以学习特定作曲家作品中的风格模式,然后生成该风格的新作品。无监督学习已经成为一个越来越令人兴奋的主题,并在深度学习复兴中发挥着关键作用,下文将对此进行更详细的描述。这种兴奋的主要原因之一是,人们认识到无监督学习可以用来显著提高有监督学习过程的质量,如下所述。
半监督学习程序使用无监督学习系统的自动特征发现功能来提高监督学习问题中的预测质量。与试图将原始输入数据与已知输出相关联不同,原始输入首先由无监督系统进行解释。无监督系统试图在原始输入数据中发现内部模式,消除一些噪音,并帮助提出数据的最重要或指示性特征。然后,这些经过提炼的数据版本被交给一个监督学习模型,该模型将经过提炼的输入与其相应的输出相关联,以生成一个预测模型,其精度通常远高于纯监督学习系统的精度。这种方法在只有一小部分可用培训示例与已知输出相关联的情况下特别有用。其中一个例子是将摄影图像与其所描绘的物体的名称关联起来的任务。在网上可以找到大量的照片,但其中只有一小部分有可靠的语言联系。半监督学习允许系统在全套图像中显示内部模式,并将这些模式与为有限数量的示例提供的描述性标签相关联。这种方法与我们自己的学习过程有些相似,因为我们有许多与特定对象交互的经验,但另一个人明确告诉我们该对象名称的经验要少得多。
强化学习程序使用奖励和惩罚来塑造一个系统相对于一个或几个特定目标的行为。与有监督和无监督的学习系统不同,强化学习系统通常不在现有数据集上进行训练,而是主要从他们通过执行行动和观察结果收集的反馈中学习。在这类系统中,机器的任务是发现能带来最大回报的行为,这种方法特别适用于机器人和学习玩棋盘游戏等任务,在这些任务中,可以明确定义成功动作的特征,但不能明确定义在所有可能情况下如何以及何时执行这些动作。
什么是深度学习?
从艾伦·图灵(Alan Turing)的著作开始,机器学习的历史就以一个交替的时期为标志,人们对该领域将其概念上的进步应用于实际系统,尤其是通用人工智能的构建的前景感到乐观和失望。这些沮丧的时期通常被称为人工智能的冬天,通常源于一种认识,即一个特定的概念模型不能轻易地从简单的测试问题扩展到更复杂的学习任务。这发生在20世纪60年代,当时马文·明斯基(Marvin Minsky)和西摩·帕普特(Seymour Papert)最终证明感知机无法解决线性不可分割的问题。在20世纪80年代末,人们开始对反向传播算法克服这个问题的能力感到兴奋。但另一个人工智能冬天出现了,因为很明显,算法的理论能力实际上受到计算密集型训练过程和当时有限的硬件的限制。
在过去的十年中,与人工神经网络相关的体系结构和训练程序的一系列技术进步,以及计算硬件的快速发展,使人们对机器学习的前景重新感到乐观。推动这些进步的核心思想之一是,认识到复杂模式可以被理解为层次结构,其中简单模式被用来形成描述更复杂模式的构建块,而更复杂的模式又可以被用来描述更复杂的模式。这项研究产生的系统被称为“深层”系统,因为它们通常涉及多层学习系统,其任务是发现越来越抽象或“高级”的模式。这种方法通常被称为分层特征学习。
正如我们在前面关于人脸识别过程的讨论中所看到的,从原始数据中学习复杂的想法是一项挑战,因为代表特定概念或对象的数据样本中可能存在巨大的可变性和噪声。
与其试图将原始像素信息与人脸的概念联系起来,我们可以将问题分解为概念抽象的几个连续阶段(见图1-10)。在第一层中,我们可以尝试发现单个像素之间关系的简单模式。这些图案将描述基本的几何元素,如线条。在下一层中,这些基本图案可用于表示更复杂的几何特征(如曲面)的底层组件,而另一层则可用于描述构成人脸等对象的复杂形状集。

图1-10 图像识别循环神经网络的分层特征层(图像由Jason Yosinski、Jeff Clune、Anh Nguyen、omas Fuchs和Hod Lipson提供,“通过深度可视化理解神经网络”,在深度学习上介绍
2015年国际机器学习会议(ICML)研讨会
事实证明,只要有足够的训练时间和硬件资源,反向传播算法和其他早期机器学习模型能够获得与最近的深度学习模型相关的结果。还应注意的是,推动深度学习实际进展的许多想法都是从早期模型的各个组成部分中挖掘出来的。在许多方面,深度学习的近期成功与其说与发现全新技术有关,不如说与我们对各种组成部分的想法以及如何将它们结合起来的一系列微妙但重要的转变有关。然而,一个适时的视角转变,再加上不断减少的技术限制,可以让一系列机会变得截然不同,这些机会以前可能是可以想象的,但实际上是不可能实现的。
由于这些变化,工程师和设计师准备通过机器学习来解决越来越复杂的问题。他们将能够产生更准确的结果,并更快地迭代机器学习增强型系统。这些系统性能的提高还将使设计师能够在移动和嵌入式设备中加入机器学习功能,这些功能曾经需要超级计算机的资源,从而开启一系列新的应用程序,对用户产生巨大影响。
随着这些技术在未来几年的不断进步,我们将继续看到从艺术和设计到医学、商业和政府的大量理论和现实应用发生根本性转变。
用机器学习增强设计
分析复杂信息
长期以来,计算机一直提供诸如微型手机和照相机等外围输入设备,尽管它们能够传输和存储这些设备产生的数据,但它们无法理解这些数据。从一个复杂的机器到另一个复杂的机器,从一个复杂的机器到另一个复杂的机器。
识别口头语言、面部表情和照片中的物体的能力使设计师能够超越键盘和鼠标等传统输入设备的表达限制,开启一套全新的交互模式,使用户能够以更加自然和直观的方式交流想法。
在接下来的章节中,我们将更仔细地研究其中的一些机会。但在这样做之前,需要注意的是,我们目前将探索的一些可能性需要特殊的硬件或密集型计算资源,而这些资源在目前的所有设计环境中可能都不实用或不可行。例如,允许深度感应和身体跟踪的Microsoft Kinect不容易与基于网络的体验相匹配。快速发展的消费电子产品将逐步将这些功能提供给更广泛的设备和平台。然而,设计师在规划系统功能时必须考虑这些实际限制。
启用多模式用户输入
在我们与他人的日常互动中,我们使用手势和面部表情,指向物体并绘制简单的图表。这些辅助机制使我们能够澄清那些不容易用语言表达的想法的含义。它们提供了微妙的线索,丰富了我们的描述,传达了更多的含义,比如讽刺和语气。正如尼古拉斯·内格罗蓬特(Nicholas Negroponte)在《建筑机器》(Architecture Machine)中所说,“正是手势、微笑和皱眉将对话变成了对话。”
在我们与计算机的通信中,我们仅限于鼠标、键盘和一组小得多的语言表达。机器学习使人们能够与计算机进行更深层次的语言交流,但仍有许多想法可以通过视觉、听觉或其他方式得到最好的表达。随着机器学习不断使更多种类的媒体为计算机所理解,设计师应该开始采用“多模态”形式的人机交互,允许用户通过给定任务的最佳沟通方式来传达想法。正如俗话所说,“一幅画抵得上千言万语”——至少当一个想法本身就是视觉的时候。
例如,假设用户需要一种特殊类型的螺丝刀,但不知道术语“Phillips head”此前,他可能曾尝试用谷歌搜索各种搜索词,或搜索多个亚马逊列表。通过多模式输入,用户可以告诉计算机,“我在找一把能转动这种螺丝的螺丝刀”,然后上传一张照片或画一张草图。然后,计算机将能够推断出需要哪种工具,并向用户指出可能的购买地点。
通过以最合适的方式进行每次交流,沟通变得更加高效和准确。用户和机器之间的交互变得更加深入和多样化,使得使用计算机的体验不再那么单调,因此更加有趣。在媒体之间的翻译可能会丢失复杂性和细微差别的地方,复杂性和细微差别得以保留。
机器学习从复杂多样的来源中提取意义的能力使这种表达能力的提高成为可能,这将极大地改变人类的本性;计算机交互需要设计师重新思考用户界面和用户体验设计的一些长期原则。
新的输入模式
视觉输入
可见的世界充满了微妙的信息,不容易通过其他方式传达。因此,从图像中提取信息一直是机器学习历史上的主要应用目标之一。这一领域最早的应用之一是光学字符识别——对来自照片来源的手写或打印文本信息进行解码的任务(见图1-11)。这项技术被广泛应用于现实世界中,从邮政服务需要快速破译地址标签,到谷歌努力实现全球书籍和报纸的数字化和可搜索性。对光学字符识别系统的追求有助于推动机器学习的研究,并一直是评估新发明机器学习算法性能的关键测试问题之一。

图1-11。MNIST数据库中手写的“8”位数
最近,研究人员将注意力转向了更复杂的视觉学习任务,其中许多任务围绕着识别图像中的物体的问题。这些系统的目标既有目的性,也有复杂性。在光谱的简单一端,物体识别系统用于确定颗粒图像是否包含特定类别的物体,如人脸、猫或树。这些技术扩展到更具体、更高级的功能,例如识别图像中的特定人脸。该功能用于照片共享应用程序以及政府用于识别已知罪犯的安全系统。
此外,图像标签和图像描述系统用于生成描述图像内容的关键词或句子(见图1-12)。这些技术可以用来帮助基于图像的搜索过程,也可以帮助视力受损的用户从他们无法访问的源中提取信息。此外,图像分割系统还用于将给定图像的每个像素与该图像区域表示的对象类别相关联。例如,在次城市住宅的图像中,与露台地板相关的所有像素都将被涂成一种颜色,而图像中描绘的草地、户外家具和树木都将被涂成各自独特的颜色,从而创建一种逐像素的图像内容注释。

图1-12 经过训练以产生图像描述的神经网络输出示例(图像由Karpath、Andrej和Li Fei提供,“生成图像描述的深度视觉语义对齐”,IEEE计算机视觉和模式识别会议记录,2015年)
机器学习在视觉任务中的其他应用包括深度估计和三维物体提取。这些技术适用于机器人技术中的任务、自动驾驶汽车的开发以及传统二维电影到立体电影的自动转换。
机器学习的可视化应用范围太广,这里无法一一列举。不过,总体而言,大量机器学习研究和应用工作已经并将继续致力于实现众多组件目标,即将曾经可嵌入的像素网格转化为高级信息,这些信息可以由机器执行,并用于帮助用户完成各种复杂任务。
听觉输入
与视觉信息一样,听觉信息也非常复杂,用于传达广泛的内容,从人类的语音到音乐,再到鸟类的叫声,这些内容不容易通过其他媒体传播。机器理解口语的能力对开发更自然的交互模式有着巨大的影响。然而,不同说话者的不同声音特征和语音模式使得机器,甚至有时是人类听者很难完成这项任务。尽管高度可靠的语音文本转换系统可以极大地促进人机交互,但即使是稍微不那么可靠的系统也会导致用户的极大挫败感和生产力的损失。与视觉学习系统一样,近年来,语音识别这一复杂任务也取得了巨大进展,这主要得益于深度学习研究的突破。对于大多数应用来说,这些技术现在已经成熟到实用性一般超过其能力中任何剩余的不精确性的程度。
除了语音识别,听觉识别音乐的能力一直是机器学习研究的另一个热门领域。Shazam应用程序允许用户通过软件捕获一小段音频来识别歌曲。然而,该系统只能从原始录音中识别歌曲,而不允许用户唱出或哼出他们想要识别的旋律。SoundHound应用程序提供了这一功能,尽管它通常不如Shazam的功能可靠。这是不可理解的,因为Shazam可以利用录制的音频信息中的细微模式来产生准确的识别结果,而SoundHound的功能必须试图解释用户自己的声音对录制的潜在高度不精确或走调近似。然而,这两种系统都为用户提供了其他方式难以替代的功能——大多数读者都能回忆起他们向朋友哼唱旋律的那段时间,希望有人能识别这首歌。这些系统所使用的底层技术也可用于其他音频识别任务,如通过鸟叫声识别鸟,或通过其发出的噪音识别故障机械系统。
肢体输入
肢体语言可以传达有关用户情绪状态的微妙信息,增强或澄清言语表达的语气,或通过指点的行为指定正在讨论的对象。机器学习系统与一系列新的硬件设备相结合,使设计师能够通过人体的无终端表达能力为用户提供与机器通信的机制。见图1-13。

图1-13。Microsoft Kinect 2 for Windows生成的骨架跟踪数据
Microsoft Kinect和Leap Motion等设备使用机器学习从专业硬件生成的摄影数据中提取用户身体位置的信息。Kinect 2 for Windows允许设计师通过其全身骨骼跟踪功能提取20个三维关节位置,并通过其高清人脸跟踪功能提取1000多个三维信息点。Leap Motion设备提供与用户手相关的高分辨率定位信息。
这些形式的输入数据可以与基于机器学习的手势或面部表情识别系统相结合,使用户能够控制具有更具表现力的身体特征的软件界面,并使设计师能够提取有关用户情绪的信息。
在某种程度上,可以使用更低的成本和更广泛使用的摄像头硬件来实现类似的功能。目前,这些专用硬件系统有助于弥补其底层机器学习系统的有限精度。然而,随着这些机器学习工具的能力迅速提高,解决这些形式的物质输入的专业硬件需求将减少或变得不必要。
除了这些输入设备,Fitbit和Apple Watch等健康跟踪设备还可以为设计师提供有关用户及其身体状态的重要信息。从检测升高的压力水平到预测可能的心脏事件,这些形式的用户输入将被证明在更好地为用户服务,甚至挽救生命方面是非常宝贵的。
环境输入
环境传感器和互联网连接的物体可以为设计师提供大量关于用户周围环境的信息,因此也可以提供关于用户自身的信息。例如,Nest Learning恒温器(图1-14)跟踪房主的行为模式,以确定他们何时在家,以及他们在一天中不同时间和不同季节所需的温度设置。这些模式用于自动调整恒温器的设置,以满足用户需求,并使气候控制系统更高效、更经济。

图1-14 家居学习 恒温器
随着物联网设备越来越普及,这些输入设备将为设计师提供新的机会,帮助用户完成各种各样的任务,从知道牛奶何时用完,到地下室何时被淹。
抽象输入
除了物理形式的输入,机器学习允许设计师在用户行为的许多方面发现隐含模式。这些模式具有固有的含义,可以从中学习并采取行动,即使用户没有明确意识到已经传达了它们。从这个意义上说,这些隐含模式可以被视为输入模式,在实践中,它们与上述更具体的输入模式具有非常相似的目的。
通过机器学习挖掘行为模式可以帮助设计师更好地理解用户并满足他们的需求。同时,这些模式还可以帮助设计师理解他们提供的产品或服务,以及这些产品或服务之间的隐含关系。行为模式可以根据单个用户挖掘,也可以从众多用户的集体行为中聚合。
模式挖掘的一种形式有助于为单个用户提供服务并改善整个系统,它是在用户形成的动作序列中发现频繁耦合的行为。例如,用户在购买早餐麦片时可能会购买牛奶。注意到这种模式,设计师就有机会构建界面机制,让用户更轻松、更高效地满足购物需求。当用户将谷物添加到购物车中时,会出现一个模式界面,提示用户购买牛奶。另一方面,尽管这两种产品通常位于商店的两个不同区域,但这两种产品可以在界面中彼此接近地显示。系统可以动态生成一个界面元素,让用户只需单击一下即可购买这些频繁耦合的项目,而不是为每个项目向用户提供单独的界面。除了有利于用户的购物体验和启用多用户推荐引擎外,系统对这些相关行为的了解还可以用于提高系统本身的效率,帮助进行库存估算等业务流程。
挖掘用户行为模式还可以帮助企业更好地了解客户。例如,如果用户经常购买尿布,几乎可以肯定用户是家长。这种用户辅助知识可以帮助设计师制作界面,更好地满足他们的目标客户演示图形,并影响商业和营销决策,例如确定哪些广告场所将产生最大的新客户流入。然而,设计师应该小心,不要对用户做出可能会让他们感到尴尬或冒犯的假设,因为这些假设与他们希望传达的公众形象相冲突。
在一个著名的事件中,零售商Target使用购买模式来确定某个用户是否怀孕,这样商店就可以更好地针对这类备受追捧的客户。尽管这种做法可能会受到一些人的欢迎,但至少在一个案例中,当一位愤怒的父亲来到一家目标商店,要求了解他高中时的女儿为什么收到了大量针对孕妇的优惠券时,这种做法造成了一种不安的局面。该男子不知道女儿怀孕了,在从女儿那里得知真相后,向零售商道歉。尽管如此,这些类型的客户洞察可能会令人不安,需要设计师在对待它们时格外小心。此类问题将在第52页“减轻错误假设”一节中进行更详细的讨论。
然而,如果小心处理,用户洞察可以为客户和企业提供巨大的价值。了解用户的行为模式也有助于安全流程,例如检测欺诈性使用客户账户信息的行为。信用卡公司和一些零售商经常使用消费者购买模式,通过检查交易的地理位置和购买的物品是否与客户的历史相符,来评估给定的购买是否具有欺诈性。如果检测到异常,交易将被阻止,并通知客户其财务信息可能被泄露。
创造对话
传统的用户界面往往依赖菜单系统作为组织用户可用功能集的主要手段。这种方法的一个积极方面是,它为用户探索系统并了解其中可能的内容提供了一种清晰明确的机制。分层菜单使用户可以通过将系统的功能划分为清晰的、特定于领域的组来快速集中搜索特定功能。如果用户不知道某个特定功能,那么它与其他更熟悉的功能的接近程度可能会导致用户尝试使用它,以有机的方式扩展她对系统的知识。
然而,分层菜单系统的缺点是,一旦用户了解了系统的功能,他们仍然需要花费大量时间浏览菜单,以获得常用功能。这种单调乏味的工作有时是由该软件提供的键盘快捷键引起的。但可以合理利用的快捷方式数量有限,而且这种方法不容易嵌入到web和移动界面中。
每增加一项功能,传统的菜单系统就会变得越来越复杂,难以导航。对于3D建模和视频编辑软件这样的专业工具,用户可能会有一个陡峭的学习曲线。但对于针对普通用户的英特尔智能助手和其他具有广泛功能集的应用程序来说,通过菜单系统展示系统功能是不切实际或适得其反的。想象一下,如果采用这种方法,Siri会是什么样子!
程序员可能熟悉另一种促进交互的机制:“读取-评估-打印循环”(REPL)。在这种接口中,程序员发出特定的文本命令,机器执行该命令,打印输出,并等待用户发出另一个命令。这种来回对话采用了人们熟悉的消息应用程序的形式,通过避免菜单层次结构的繁琐和不间断导航,程序员可以更快、更动态地工作。
这种对话形式也提供了一种理想的媒介,用于促进上一节所述的各种多模态互动。在这个机器学习增强的环境中,我们可以想象用户和机器之间有许多充满活力和多样性的交流。与人类合作者举办的白板会议非常相似,用户和软件将轮流解决手头任务的各个方面,解决其组件问题,并通过各种语言表达、图表和手势阐明他们的想法。
辅助特征发现
尽管有许多优点,但开放式对话对用户了解系统的功能几乎没有帮助。为了充分利用REPL编程界面,用户必须事先了解可用功能或频繁参考文档,这可能会抵消基于菜单的工作流带来的任何效率提升。对于智能接口,将功能发现过程转移到辅助文档中就更不实际了。
对话用户界面的潜在局限性可以从我们与第一代智能助手(如Siri、Cortana和Echo)的互动中看出(图1-15)。在这种情况下,特征发现通常包括用户在脑海中搜寻可能导致软件做出有趣或有用响应的短语。

图1-15 亚马逊的音响
许多智能助手提供的功能发现问题的一个解决方案是向用户提供一组测试输入,以演示系统中的各种可用功能。计算知识引擎Wolfram Alpha将示例直接嵌入其界面,帮助新用户熟悉系统的交互模式及其能够访问的知识类型。这些精心策划的例子继续吸引着即使是经验丰富的用户,邀请他们进一步探索它们所揭示的娱乐或信息途径。
然而,通过一系列嵌入式示例演示应用程序的全部功能,可能会让软件看起来像一本参考手册。机器学习或传统编程逻辑可用于动态选择与用户活动相关的示例,而不是手工挑选静态示例组。更进一步说,机器智能可以用来生成用户轨迹的推测性扩展,为用户提供一系列概念方向的后续步骤,供用户考虑。这种机制不仅可以扩展用户对界面及其可能性的理解,还可以丰富用户对手头任务或感兴趣领域的流利程度。
帮助用户在对话界面中定位功能的另一个常见机制是,当系统不清楚用户的陈述时,提供建议的含义。这有助于纠正用户或多或少已经知道的命令的格式不正确的表达式。但是,如果用户完全不知道某些潜在的优势功能,他将不会首先考虑请求它,而这种机制无法提供帮助。
从理论上讲,我们可以将特征发现的问题推迟到技术进步的进程中,并假设计算机最终将具有足够的智能,能够执行任何可能被要求完成的任务。然而,机器处理任何请求的能力并不能本质上转化为用户对每一个可能被证明对他的目标有用的请求的意识。此外,用户可能对问题领域不够熟悉,无法首先制定一套目标。
想一想你可能会问一位诺贝尔化学奖得主什么问题。如果没有这一领域的丰富工作知识,你就不可能充分利用她的专业知识提出一个问题。为了充分利用这一机会,您需要一些指导,以找到一条富有成效的调查路线的切入点。
为了帮助用户执行复杂的或特定于领域的任务,设计师应该努力构建不仅能响应用户请求,而且能丰富用户对领域本身的理解的系统。智能接口提供无限多样的功能是不够的;他们还必须找到将用户与其所包含的可能性联系起来的方法。
结识
也许任何谈话中最大的挑战就是知道从哪里开始。当你遇到新朋友时,你无法确定你的个人经历、职业背景,甚至你使用的idi-oms和手势是否与他们的相同。因此,我们通常从简单的寒暄开始,然后试图通过提出关于另一个人的兴趣、工作领域和家庭的基本问题来建立共同点,然后再深入探讨更具体的主题和问题。
同样,在设计对话用户界面时,我们必须与用户建立共同点,并向他们介绍系统的功能和交互模式,因为菜单系统没有明确详细说明这些功能和模式。
空白页面可能会令人窒息,可能会导致一些用户立即失去兴趣。因此,让用户尽快把脚弄湿是很重要的。应用程序可以要求用户执行使用这些功能之一的简单任务,而不是简单地展示一些基本功能的示例输入。这给了用户一个初步的信心提升,并有助于让对话畅通无阻。
随着用户通过这些初始练习获得吸引力,软件在寻求具体行动时会逐渐变得不那么主动,并允许用户根据自己的条件探索工具。随着时间的推移,系统可以继续向用户推荐新功能。但设计师应该小心,不要在用户熟悉系统后,用太多新想法轰炸他们。
一旦适应,用户自己的探索和活动可以帮助系统了解哪些功能对她最有用。随后,如果用户无所事事或似乎陷入僵局,系统可以建议用户从未探索过的与上下文相关的新活动或功能。这种形式的协助将在第43页“设计积木”一节中进一步讨论。
当然,用户应该始终能够选择退出这些建议,或者将它们重定向到更相关的功能。在结束这些介绍性练习之前,确保用户知道如何在需要时从系统获得帮助也很重要。许多新用户将渴望尽快深入了解该软件,这将导致他们匆忙完成这些重要的入职培训。在对话界面中,从系统寻求帮助的一个明显而自然的机制是使用“帮助”这样的关键字然而,在某些情况下,用户的理解可能来自对对话界面的开放性缺乏熟悉或不舒服。因此,提供具体且持久的界面元素(如帮助按钮)可能很有价值,该按钮允许用户快速、明确地寻求帮助。
寻求清晰
在一个带有智能界面的开放式对话中,用户很自然地,甚至可能是希望得到这样的印象,即系统中的任何事情都是可能的。然而,在大多数情况下,情况并非如此。尽管智能助手在概念上具有广泛的多功能性,但其真正的功能通常仍局限于一个或几个特定的功能领域。他们理解人类语言并将其映射到特定功能的能力通常也有点脆弱。
设计师可以通过提供对话线索来帮助调解这些技术限制,引导用户远离宽泛或模棱两可的语句,这些语句不容易被机器解析。其中的一个关键组成部分是为交互设计,以建立用户的现实期望,并通过示例或简要描述明确指出所请求的信息类型。
如果一个应用程序提示你“说出你的想法”,那么对你的想法进行冗长而热情的描述,却让机器简短地回答“对不起,我不明白”,这将是令人失望或尴尬的
在新的互动开始时,帮助用户专注于特定的任务或传达特定的信息点通常是最困难的。用户可能有几个印象深刻的或部分形成的目标,但可能没有足够的清晰度来明确系统的入口点。由于没有从用户最近的行为中获得的累积文本信息,机器在交互开始时也很难推断用户的意图。
该系统不是从一个开放式问题开始,而是可以提出一个具体但基本的问题,这将有助于建立文本,让对话继续进行,以便在随后的交流中获得更多细节。在许多情况下,为用户提供一些分类选项可能会有所帮助,这些选项将他们的目标定位到系统整体功能的特定子集。在电子商务网站的环境中,系统可能会通过询问用户是否希望购买特定商品、浏览商店特定区域的商品或退货来打开对话。一旦建立了广泛的背景,系统可以通过提出从这个切入点有机延伸的问题,向用户寻求更多细节。如果用户表示有兴趣购买特定物品,系统可能会提出一系列关于所需尺寸、材料或与该物品相关的可选配件的问题。
没有什么比让你的想法平淡无奇更令人沮丧的了,没有任何迹象表明什么是令人困惑的,或者如何更好地传达你的意图。也许用户的表达完全超出了机器的理解范围。或者,也许一个单词的选择或措辞的改变就能让陈述变得清晰。但是如果没有机器的任何反馈,用户将在猜测问题时感到沮丧。
当用户的输入被理解后,系统应在继续进行后续交流之前重申其理解的内容。如果系统尚未了解用户,则应尽其所能指出问题的性质。
许多机器学习和自然语言处理平台可以配置为返回用户表达的多个推测性解释,以及在数字上表示机器对其提供的每个解释的正确性的确定性的置信分数。只要有可能,智能应用程序应尝试将这些推测性解释与用户活动的更广泛背景知识相关联,以消除最不合理的选项。如果这种方法没有揭示一个明确的含义,设计师应该考虑直接向用户展示一些排名最高的解释。让用户了解这些推测性的解释将有助于他们理解问题的本质,并重新措辞或纠正陈述。
将相互作用分解为颗粒交换
为了促进用户和智能界面之间的成功交流,设计师可以做的最重要的事情之一是帮助用户将多级工作流及其组件交互分解为小的概念性部分。机器学习和自然语言处理系统比复杂、多方面的语句更容易理解传达单个命令或信息点的简单表达式。设计师可以通过创建界面和工作流来帮助用户提供简洁的陈述,这些界面和工作流引导用户完成一系列简单的练习或决策点,每个练习或决策点都涉及更大、更复杂任务的一个方面。
这种方法的一个很好的例子是20Q,这是游戏《二十个问题》的电子版。与最初的公路旅行游戏一样,20Q要求用户思考一个物体或名人,然后提出一系列选择题,以发现用户的想法(见图1-16)。
在这个过程中提出的第一个问题总是:
“它属于动物、植物、矿物还是概念?”
接下来的问题试图从用户已经提供的信息中发现进一步的区别。例如,如果第一个问题的答案是“动物”,那么下一个问题可能是“它是哺乳动物吗?”如果第一个答案是“蔬菜”,下一个问题可能是“它通常是绿色的吗?”接下来的每个问题都可以用以下选项之一来回答:是、否、未知、无关、有时、可能、可能、可疑、通常、取决于、很少或部分。
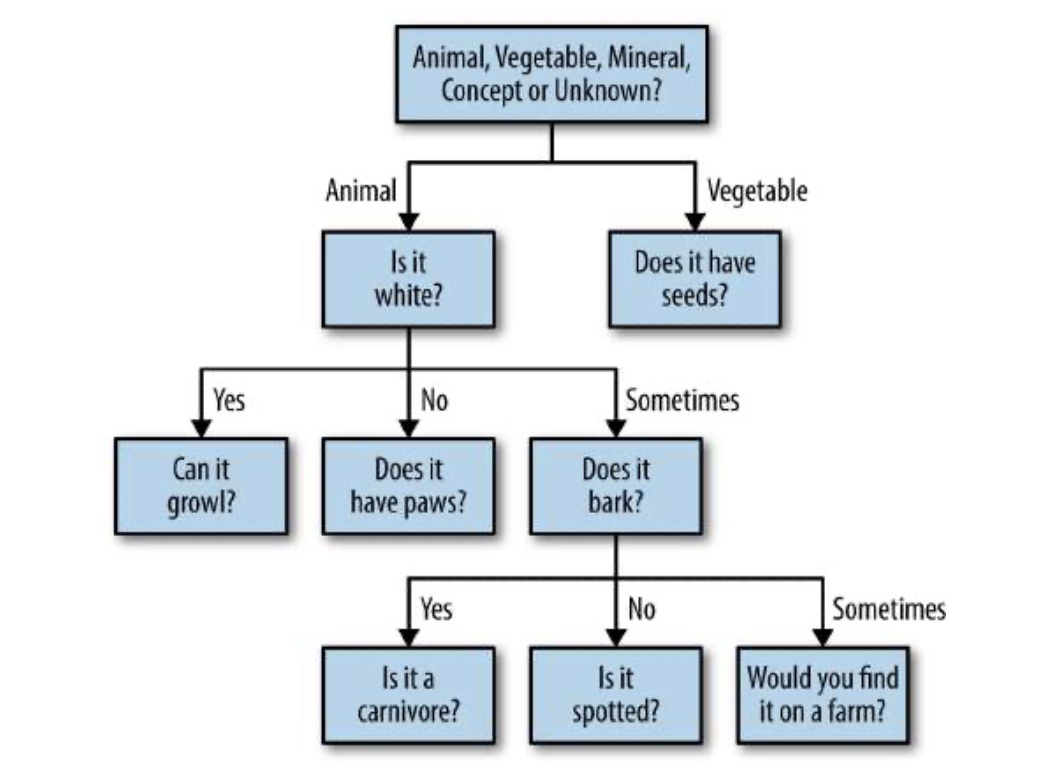
图1-16 游戏的学习决策树20Q
20Q在20个问题后80%的时间和25个问题后98%的时间猜测正确的人、地点或事物。该系统使用一种称为学习决策树(或分类树)的机器学习算法来确定问题的顺序,以尽可能少的步骤得出正确答案。使用之前用户与系统交互产生的数据,该算法在尽可能多地删除错误选项时学习每个问题的相对值,以便能够首先向用户提出最重要的问题。
例如,如果已经知道用户心目中有一位名人,那么下一个问题很可能是此人是否活着,而不是此人是否写过一本书,因为今天只有一小部分历史人物活着,但许多名人都写过这样或那样的书。
虽然这些问题都不能单独概括用户的全部想法,但相对较少的精心挑选的问题可以以惊人的速度找到正确答案。除了帮助系统理解用户的表达之外,这个过程还可以直接帮助用户更清晰、更有目的地交流想法。这个过程还可以让沟通想法的任务对用户来说更有趣、更有吸引力。
除了猜谜游戏,设计师可能会发现这种方法在广泛的人机交互中很有用。在其核心,这个过程可以被看作是一种通过大量相互关联的决策发现最优路径的机制。从这个角度来看,我们可以想象将这种方法应用于金融投资组合的创建或新音乐的发现等过程。
在开发金融投资组合时,会向用户提出一系列与他们的财务优先事项和约束相关的问题,以便找到一套非常适合他们的长期目标、风险承受能力和消费习惯的投资。在音乐或电影发现方面,这个过程可能有助于克服与标准推荐引擎相关的一些限制因素。例如,一个用户可能会给一部特定的电影一个很高的评价,因为它由他最喜欢的演员之一主演,即使这部电影的类型通常对用户没有兴趣。根据这一评级,推荐引擎可能会推荐类似的电影,而不会让用户有机会指出演员而不是类型是其评级的关键因素。使用交互式决策树过程,系统可以更容易地发现这一重要区别。
设计积木
上述各种机器学习增强型工作流可以为设计师提供强大的新工具,使复杂任务更易于理解、更高效、更有趣。同时,启用这些交互模式可能需要设计师偏离至少一些长期存在的用户界面和用户体验设计惯例。
在第11页的“机械归纳”一节中,我们讨论了归纳学习作为一种搜索过程。类似地,任何任务,如果用户心中有某种期望的最终状态,并且必须发现一系列将达到此目标的操作,则可以将其视为一种搜索。从这个角度来看,让我们想象一个非常大的地图,其中每个可能的结束状态以及我们的起点都由一组独特的坐标表示。
在这张地图上,软件的每一个功能都可以被看作是一条在特定方向上带我们走一定距离的道路。要在这个空间中导航,我们必须找到一系列动作或驾驶方向,这些动作或方向从我们的出发位置指向所需的目的地(见图1-17)。低级别要素相当于一条本地道路,因为它只会在地图上移动我们一小段距离,而高级别要素则更像一条高速公路。
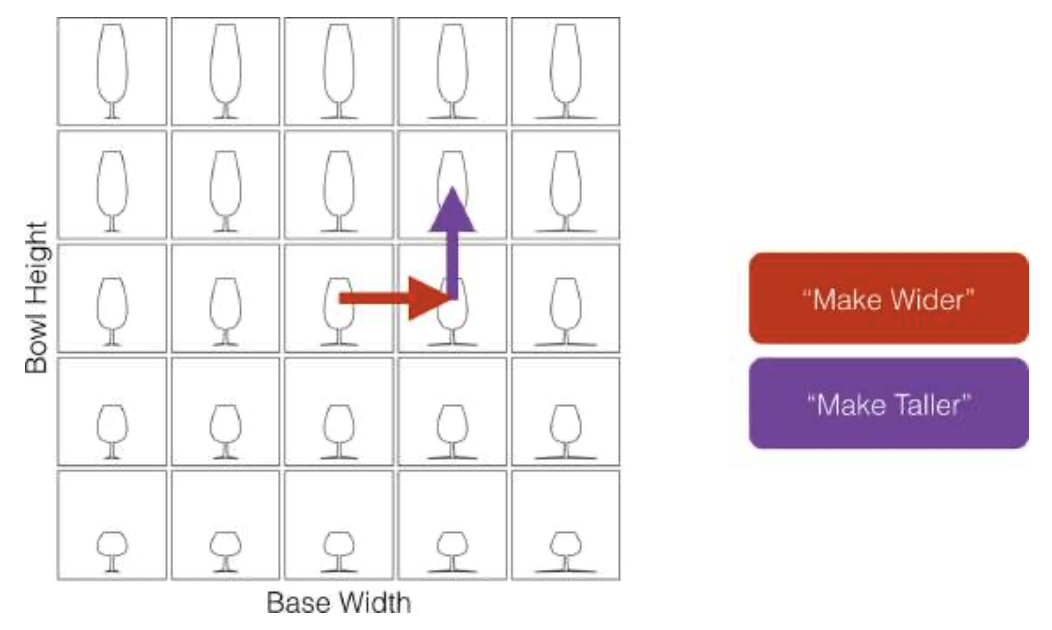
图1-17 与酒杯设计相关的一系列低级功能
高速公路的好处在于,它们只需相对较少的组件动作就能将我们带到很远的距离(见图1-18)。然而,问题是,高速公路只有在常去的目的地才有出口匝道。为了到达更加模糊的目的地,驾驶员必须走当地道路,这需要更多的组件操作。理想情况下,无论何时我们离开家,都会为我们修建一条新的公路,这样我们就可以通过少量的行动到达任何可能的目的地(见图1-19)。但对于预构建的高级接口,这是不可能的。
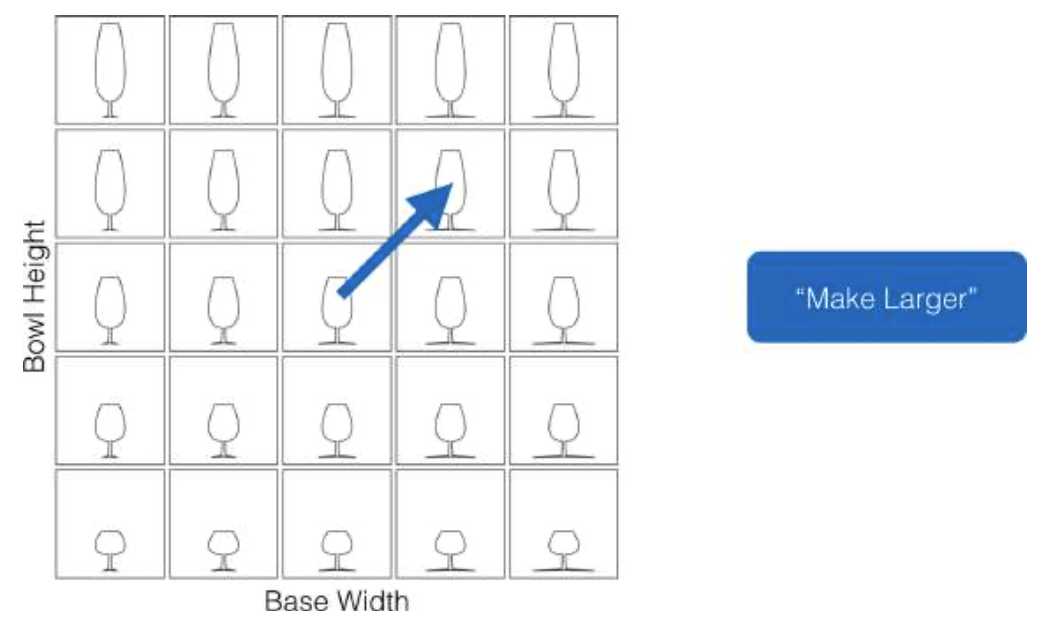
图1-18 更高级的功能

图1-19 这是一个潜在的可取之处,但并不存在
机器学习允许我们推断出大量关于用户的信息,以及他们希望通过观察他们的行为来实现的目标。与其试图通过一组预先构建的高级界面来预测用户的需求,我们可以设计从用户对软件的参与中学习的系统。例如,我们可以发现常用的低级功能序列,然后动态地将这些低级功能组合成与系统内用户当前活动相关的定制、专门构建的功能。
用户高级功能的自动化生产中使用的行为模式可以从单个用户或多个用户中挖掘。有点像根据用户喜好的相似性来推荐音乐或电影的推荐系统,跨多个用户的模式发现可以用于根据个人倾向于使用的工作流向个人推荐相关功能。这将允许设计师更好地解决用户的多样性,以及他们消化信息、做出决策和与软件交互的各种方式。它允许设计师在用户所在的地方与他们见面,而不是要求他们适应由更传统的静态用户界面提供的单一的预定思维或工作流程。此外,通过对许多用户的行为模式进行外推,设计师可以更好地理解其系统中提供的功能之间的隐含关系,为软件如何进一步开发以更好地满足用户需求提供重要见解。
通过该过程生成的高级功能可以通过多种方式提供给用户。根据用户最近的动作轨迹,可以通过一种类似于某些文本编辑应用程序提供的自动完成功能的机制,向用户呈现一个模式界面,提供一个或多个可能的后续步骤。或者,自定义生成的功能可以与按钮等常规界面元素相关联。然而,这种方法提出了一个问题,即如何让用户意识到这个新生成的功能将产生的影响。在传统界面中,按钮通常与指示功能用途的文本标签或图标相关联。对于将多个更细粒度功能捆绑在一起的自定义生成功能,生成此类标签或图标可能是一项挑战。此外,用户可能很难跟踪界面的巨大且不断变化的图标。
为了规避这一挑战,当用户将鼠标悬停在与功能相关联的界面元素上时,系统可以直接演示其效果,而不是通过标签或图标指示给定功能的效果。例如,在网上购买汽车的用户可能会选择更改油漆颜色。在这样做时,可以生成一个按钮,这样当用户将鼠标悬停在该按钮上时,汽车视图将显示一组建议的附加更改的预览,例如内饰织物、内饰等。如果用户单击按钮,这些更改将被执行,但如果用户选择不单击按钮并将光标移开,汽车预览将删除这些更改。
通过采用这种方法,设计师的角色将从高级功能的整体策划转向创建更细粒度的界面元素。整体策展将从用户传达的各个信息点的聚合中产生。这种从预设规则系统和界面到隐式、智能生成的规则系统和界面的转变意味着设计师将放弃对设计某些方面的控制。然而,这样做可以让用户解决软件设计者没有明确预期的任务。这种范式的转变将极大地推进设计最重要的目标:服务于用户的需求。
获取训练数据
机器学习系统的好坏取决于它所训练的数据。无论一个算法有多强大,如果这些模式不由数据表示,它都无法提取有意义的模式。事实上,在某些情况下,更强大的机器学习算法可能会因较差的训练数据而产生特别错误的结果,因为在没有有意义的模式的情况下,系统可能会将其能力用于学习数据集噪声中存在的不相关模式。
一般来说,给定数据集的质量与以下特征有关:
完整性:数据在多大程度上表明了所代表系统内可能发生的所有行为。例如,如果只在雨天记录某个城市的温度数据,那么该城市的温度数据将非常不完整。
准确性:数据在多大程度上符合其所代表的真实世界行为。换句话说,某一天记录的温度应该与实际温度完全匹配。
一致性:集合中不同数据点之间不冲突的程度。这意味着在同一时间段和位置的数据集中,记录的温度不应超过一个。
及时性:数据与系统当前状态的关联程度。例如,一个给定城市1900年的温度数据可能无法表明该城市最近的天气模式。
为了在数据集中实现这些特性,通常需要大量人力。准确性、一致性和及时性要求仔细收集、整理和维护数据。完整性通常在一定程度上是通过数据集中的大量示例实现的。有了更多的例子,数据集就更有可能解释所有可能的行为。因此,大型机器学习系统使用的数据集包含数十万或数百万个训练样本并不罕见。用于训练谷歌图像分类系统的ImageNet数据集(见图1-20)包含1400多万张图像,每一张图像都附有一个文本标签,用于识别图像描述的22000多个类别的对象中的哪一个。

图1-20 从ImageNet数据集中选择图像
对于某些已经受到行业和研究界显著关注的机器学习问题,可以在Web上免费获得大型和精心策划的数据集。查找这些数据集的资源可在第67页的“进一步”一节中找到。但对于尚未被广泛研究的机器学习问题,可用数据的可用性一直是应用机器学习系统发展的最大瓶颈之一。
智能反馈循环
在上一节中,我们讨论了界面设计如何帮助用户将想法和信息清晰地传达给机器学习增强型系统。相反,这些相同的机制可以用来提高机器学习系统从用户生成的数据中学习的能力。通过这种共生关系,机器学习系统和人类用户的能力可以相互增强,将双方的能力提升到新的高度。在reCAPTCHA系统(图1-21)中可以看到这种共生关系的一个重要例子,许多读者已经熟悉该系统。
图1-21 举个例子 reCAPTCHA
CAPTCHA被开发为一种机制,用于验证试图访问网站的用户是否是人类,方法是让他们执行机器无法轻易破译的任务。卡内基梅隆大学的路易斯·冯·安(Luis von Ahn)和其他几名研究人员意识到,这些卑微的任务的执行将共同代表大量浪费的人类努力,因此设计了一个名为reCAPTCHA的系统,将这一努力很好地加以利用。
在早期版本中,reCAPTCHA系统会向用户呈现一个单词的图像,该单词无法被一个负责打印文本数字化的光学字符识别系统破译。这个图像通常与已经被破译的“控制”字的图像配对。要访问该网站,用户需要输入这两个单词。如果他们正确地输入了控制字,则假定用户的输入是有效的,他们将被授予访问该网站的权限。然后,他们对之前未加密的单词的输入将与其他几个用户对同一图像的输入进行比较。如果多个用户对特定图像的输入是一致的,则假定输入是正确的,并将插入原始文本的数字化版本中。
谷歌后来收购了这项技术,这项技术在《纽约时报》档案和谷歌图书项目下几所大学图书馆的内容数字化方面发挥了重要作用。最近,通过向用户展示一组缩略图像,并要求他们仅选择描述特定类别对象的图像,ReCAPTCH已被用于改善谷歌图像识别系统的性能。
这一聪明的想法为网站提供了更高的安全性,同时将少量的人类努力聚集在一起,以提高机器学习系统的能力,从而使人类用户受益。reCAPTCHA是一个相对简单的想法,但它强大而高效。设计师可以将这一理念的基本精神应用到机器学习增强系统开发中的各种应用中。设计师可以在用户和计算系统之间建立共生关系,使双方受益,同时简化系统开发人员的艰巨数据收集和清理任务。
应对挑战
不确定性设计
一个不可靠的系统往往比没有系统更糟糕。在我们的日常生活中,我们依靠无数的系统来帮助我们完成与一切相关的任务,从跟踪日程安排到确保家庭安全。无论这些系统能提供什么样的服务,只有它们始终如一地工作,它们才对我们有价值。单一故障的有害影响可能远远超过系统正常工作的一千个实例所带来的好处。
在任何情况下,设计一个完美的系统都是一项艰巨的任务。但在机器学习的背景下,这尤其具有挑战性,在机器学习中,系统的行为可能是通过机器在有限数量的离散考试样本上的经验训练来定义的。机器无法知道这些训练示例是否指示了在实际使用中可能遇到的每种情况。此外,如果机器确实遇到了不熟悉的情况,而不是宣布其不适合处理这种情况,它可能会尝试将新数据拟合到其现有模型中,并将其结果返回给用户,而不显示出有什么问题。
如果机器学习系统被设计为在其预测的同时返回置信度得分,则系统尝试将不一致的数据拟合到现有模型中很可能会产生较低的置信度得分,从而使设计者有机会在错误结果到达用户之前捕捉到错误结果。然而,不幸的是,无法明确保证不会出现一场完美的条件风暴,它会混淆特定数据样本的不一致性。
尽管传统的计算机程序可能包含bug,但它们的显式编码逻辑提供了相对有力的保证,即它们的行为是可预测和可重复的。随着计算机成为我们日常生活中不可或缺的一部分,我们越来越习惯于它们的可预测性和可靠性。随着我们逐步采用智能系统,用户将很难改变他们对可靠性的期望,即使他们降低的可靠性带来了更先进功能的承诺。
为了降低与机器学习系统错误行为相关的风险,并为用户提供最佳体验,设计师应在向公众发布其软件之前采取以下步骤:
1.交互设计,其中系统明确重申其对要求其执行的任务的理解,使用户有机会发现错误并重定向系统行为。
2.如果可能,通过常规用户界面提供回退机制,允许用户绕过机器学习增强功能,并使用显式逻辑和界面执行任务。
3.在尽可能多的环境和使用场景中对软件进行严格测试,以发现与原始开发环境不同的条件可能导致的故障或不一致。在更广泛地向公众发布之前,向知识更渊博、容错能力更强的测试人员进行有限的发布可能有助于发现环境中的不一致之处。
4.使用所有可用指标,即信心分数,来评估所包含特征的有效性。在如何向用户展示功能及其有效性方面设定现实的期望。
5.如果一个令人印象深刻的功能的行为太不可靠,请抵制其诱惑。这种评估应该权衡功能的复杂性和潜在价值与失败的可能性。如果一个功能提供了一些潜在的革命性的新功能,用户可能更愿意接受它只有90%的工作时间。
6.让用户意识到使用软件或特定功能可能带来的任何风险,并允许他们自行决定这些风险是否被系统功能的潜在好处所抵消。
7.如果系统故障可能会造成非常严重的后果,如对用户财产造成不可挽回的损害、人员伤亡,则应极其谨慎地权衡功能的价值,并应咨询律师,以评估风险和责任,以及制定任何必要的免责声明,提交给用户。
减轻错误的假设
让任何人,无论是人类还是其他人,对我们的身份做出决定性的描述,这与我们看待自己的方式或希望被他人感知的方式相冲突,我们都会感到不舒服。随着机器学习继续深入个人见解和客户偏好领域,将用户与他们可能感兴趣的产品联系起来的能力将带来更好的客户体验和更高效的市场,但也为许多可能的尴尬局面打开了大门。
对用户说:“我想你会喜欢这场即将到来的巴里·马尼洛演唱会。”这完全是另一回事,“你的品味与我们的‘老屁’用户类别一致,因此我认为你会喜欢巴里·马尼洛的演唱会。”我们可以将机器学习系统的统计相关性留在统计领域和幕后,而不是显式地描述用户。我们可以对用户可能感兴趣的事情提出建议,而无需说明是什么让机器相信用户会感兴趣。
然而,做出此类建议所依据的统计基础可能会无意中反映出文化偏见或其他关于用户的错误假设。在过去几年中,机器学习系统在执行图像标记等复杂任务的能力方面取得了惊人的进步。这些系统的创造者们很高兴能尽快与世界分享他们的工作,即使软件还处于开发的早期阶段。然而,很难防范甚至预见这些新兴技术的所有可能失败,因此发生了几起尴尬或冒犯性事件。在其中最严重的事件中,谷歌的照片应用程序将几名黑人用户标记为“大猩猩”。
这一事件造成的不安是完全可以理解的。然而,重要的是要记住,所涉及的机器学习系统无法接触或意识到使这种错误具有攻击性的复杂社会概念。这一错误的部分原因是用于训练系统的图像集不平衡,谷歌和其他科技公司应该设法纠正这种情况。但是,正如机器学习专家Andrew Ng(吴恩达)所说,“……很明显,这是一个无辜的错误,而不是故意的错误,只是学习算法每天无疑会犯的数百万个错误之一。”
尽管机器是无辜的,但这个错误暴露了一个缺陷,造成了不快的情绪,我们应该尽一切努力防止类似事件在未来发生。其中一个组成部分是努力建立更加精确的机器学习模型。另一个是努力发现我们提前提供给机器的数据集中可能存在的任何隐含偏见。然而,考虑到机器与人类世界在经验上的隔绝,在可预见的未来,机器不太可能绕过所有可能的文化偏见。因此,我们必须通过设计找到防止此类错误的方法。例如,设计人员应该考虑为用户提供明确的机制来标记攻击性内容,就他们希望如何描述提供指导,或者选择不使用可能产生错误假设的特定功能。
创建安全检查
由于机器学习模型没有检测自身知识差距或偏见的固有方法,设计师应注意外部机制,以防止潜在的攻击性或错误行为。在许多情况下,这可能很困难,因为首先使用机器学习的主要动机之一是这些系统能够处理对于常规计算机程序的显式逻辑来说过于复杂或微妙的信息。然而,传统的代码至少可以在发现明显的问题方面提供一些帮助,比如引发明显的贬义语言。
在撰写本文的时候,微软发布了一个名为Tay的聊天机器人,旨在回应Twitter和其他消息服务上的用户。在发布了数量惊人的煽动性信息后,该机器人在一天之内就被关闭了。也许这起事件最令人惊讶的是,相关信息中没有含沙射影或容易误解的联想;相反,它们包含了公开的贬损语言和情绪,使用了广为人知的种族主义和性别歧视术语,以及对阿道夫·希特勒等的引用。
事实证明,该系统是针对用户生成的内容进行培训的,并且是那些希望通过诱导系统从自己的仇恨言论中学习来产生这种结果的人的目标。然而,如果该系统的设计者在发布到Twitter之前,使用代码对照冒犯性词汇词典检查机器人的消息,那么这种结果至少可以部分避免。这种方法可能会变成一种猫捉老鼠的游戏,因为想要颠覆这种安全措施的用户通常会采用创造性的单词拼写或策略,比如用数字“3”替换字母“e:”,这样他们使用标记的术语就不会被发现。然而,值得注意的是,泰伊的信息中使用的许多冒犯性术语拼写正确,即使是最基本的保护机制也很容易捕捉到。
虽然有点违反直觉,但在这种情况下可能会采取的另一种方法是使用经过专门培训的二级机器学习系统来检测攻击性内容。这类系统用于电子邮件和用户论坛等服务中的垃圾邮件过滤。营销人员还可以在情绪分析工具中使用它们,以便更好地理解社交网络上对其产品的评论。
尽管这两种方法都不能完全解决问题,但它们至少可以防止最公然的滥用。除了这些机制之外,设计师还应该依靠用户群的集体智慧,提供明确的界面元素,允许用户标记攻击性或错误的内容,供系统管理员审查,并随后集成到机器学习模型中。这种方法比任何自动方法都更能帮助设计师领先于恶意用户和有缺陷的数据集。
使用机器学习平台
理论上,机器学习可以应用于包含模式的任何类型的信息,只要这些模式可以由一组训练数据充分证明。然而,在实践中,与其他形式的信息相比,某些形式的信息更容易访问并应用于现实世界的设计问题。对于图像标记和语音文本功能等更常见的机器学习任务,设计师可以利用各种机器学习即服务(MLaaS)平台提供的交钥匙解决方案,这些平台通过RESTful API和设计模式实现与面向用户的系统的直接集成。在MLaaS提供的许多定制数据集上,也可以使用MLaaS提供的定制数据集。对于更奇特或特定领域的用例,设计人员可能会寻求更可定制的开源机器学习工具包,甚至是完全定制的软件,这往往需要对底层算法以及与在大规模面向用户的系统中部署此类技术相关的技术问题有更深入的技术理解。
机器学习即服务平台
几家大型科技公司和初创公司提供高级机器学习平台,为设计师提供直接访问交钥匙解决方案的途径,或对设计师提供的数据进行定制培训。MLaaS平台的列表正在快速增长。一些最流行的平台包括:IBM Watson、亚马逊机器学习、谷歌预测API、Microsoft Azure、BigML和ClarifAI。
尽管这些系统有许多优点,但设计师在决定是否使用此类平台构建系统时,可能会考虑到一些重要的缺点。首先,这些系统的使用伴随着经常性成本,随着用户群的扩大,这些成本将不断增加。尽管单个查询的成本通常很低,而且批量费率也可用,但对于足够大的用户群来说,如果没有可行的收入模型来支持该产品,这些成本可能会变得令人望而却步。此外,这些平台通常不提供将在一个MLaaS平台内开发的系统移动到竞争平台的直接路径。这种平台锁定可能会增加自有品牌的长期成本,并可能会限制设计师系统内的未来创新。最后,建立在MLaaS平台之上的系统往往需要用户的设备具有互联网连接,以便查询远程托管模型。这在某些应用程序中可能会受到限制,并且可能会给用户带来数据使用成本。然而,与许多复杂机器学习相关的模型可能太大或计算密集,无法在用户设备上运行,因此无论是否使用了MLaaS或定制机器学习解决方案,基于云的部署都是唯一可行的途径。
整体解决方案
如果您希望在设计中提供的基于机器学习的功能得到其中一个平台的交钥匙功能的特别支持,那么这种方法将为面向用户的可部署产品提供最快速、最简单的途径。尽管所提供的具体功能因平台而异,但许多MLaaS平台为包括自然语言解析、语言翻译、语音到文本、个性洞察、情感分析、图像分类和标记、人脸检测和光学字符识别在内的任务提供了交钥匙解决方案。
这些系统的创建者已经投入了大量的工作来开发和测试他们的底层算法,以及收集大型和干净的数据集,以确保强大的功能。这些交钥匙功能可以在不进一步了解底层算法或数据集的情况下使用,使用各种语言中简单的API调用。
例如,可以使用IBM Watson平台的节点接口和图1-22中使用的代码执行图像分类查询。

图1-22 Watson图像分类查询
Watson随后将返回图1-23中的JSON响应,客户端系统可以轻松解析该响应,并将其集成到面向用户的设计中:
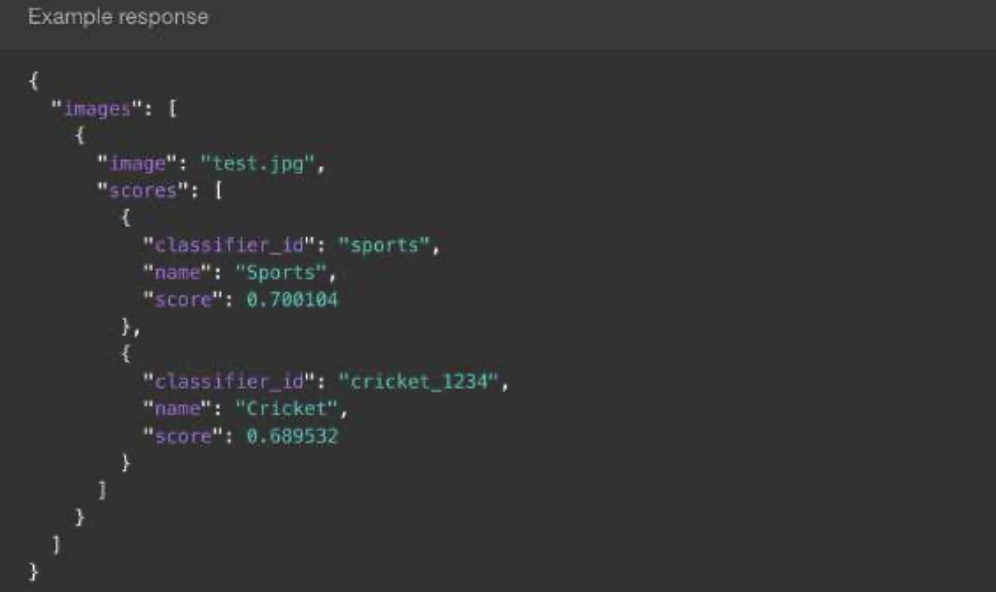
图1-23 对Watson图像分类查询的易于解析的JSON响应
定制培训系统
除了上面列出的整体解决方案外,MLaaS平台还可以用于需要定制、设计师提供的数据集的各种机器学习问题。在这种情况下,设计师可能会绕过构建、测试和部署机器学习系统本身的艰巨过程。然而,他们仍然需要投入时间和资源,以确保他们提供给这些系统的数据集是干净且经过良好管理的,尽管许多MLaaS平台也在简化这些过程方面提供了实质性的帮助。
尽管提供的具体功能因平台而异,但许多MLaaS平台提供与用户行为预测、客户分析和洞察、库存趋势、推荐引擎、内容个性化、欺诈和异常检测以及任何其他监督学习问题相关的功能。
这些系统的培训过程通常涉及设计师将电子表格或格式化数据上传到平台,等待模型在云中接受培训,然后在面向用户的设计中部署功能之前测试其行为。对于大多数有监督的学习问题,提供给MLaaS平台的数据电子表格将至少包含两列:一列或多列代表特定示例的输入属性,另一列代表与该输入相关的期望输出。与任何培训过程一样,大量的示例(或电子表格行)可能会生成更健壮的模型。经过培训后,对模型的查询将以类似于上述交钥匙功能示例的方式进行。
开源机器学习工具包
对于一些机器学习问题和面向用户的平台,尤其是为离线使用而设计的本机应用程序,可能需要在上述MLaaS平台之外部署技术。在这种情况下,设计师可以通过在越来越多的开源机器学习工具包(可用于多种编程语言和平台)的基础上构建,避免与完全定制解决方案相关的冗长开发过程的某些方面。这类流行工具包包括:TensorFlow, Torch, Caffe, cuDNN, Theano, Scikit-learn, Shogun, Spark MLlib, and Deeplearning4j 。
这些较低级别的工具包通常需要比使用MLaaS平台所需的更多编程经验。此外,有效使用特定机器学习算法及其相关培训技术可能需要更深入的知识。虽然上面列出的MLaaS平台往往包括自动培训过程,但这些工具包将要求设计师调整算法超参数,如学习率,以符合所选数据集的特定特征。这种调整过程借助于更深入的数学知识,通常至少需要一些时间密集的尝试和错误,以找到合适的值。
机器学习系统的培训往往是一个高度计算密集的过程,对于大型或复杂的数据集,在单个消费者级机器上执行此过程通常是不切实际的,甚至是不可能的。上面提到的许多工具包都是为使用大量CPU或高性能GPU执行培训的大型硬件系统而设计的。这种硬件可能成本高昂,并且可能需要与特定工具包使用的性能增强机制相关的专业知识。
一旦经过培训,该系统仍然需要部署到所需的面向用户的平台上。在这些工具包适用的大多数情况下,面向用户的平台与培训过程中使用的大型系统几乎没有共同之处。这意味着设计师在开发他们的系统并使其可供用户使用时,必须应对两组不同的技术和基础设施挑战。
尽管存在这些挑战,但这些工具包为希望向面向用户的系统添加定制机器学习功能的设计师提供了一条可行的途径。这些工具中的许多都得到了大型科技公司的支持,这些公司在其更广泛的应用中有着既得利益,并正在努力逐步使其工具更容易被更广泛的设计师和开发人员使用。
这些工具包在MLaaS平台上的另一个卖点是,这些工具本身可以自由使用和部署,尽管在大型平台上培训它们可能需要设计师购买自己昂贵的硬件或支付使用基于云的系统的费用。
与MLaaS平台一样,使用此类工具包开发的经过培训的模型可能不容易转移到其他工具包中使用。然而,在大多数情况下,这些可定制的工具包提供了一种比由一个MLaaS平台支持的系统更直接的方法。
完全定制的机器学习工具
上面列出的开源工具包致力于提供经过充分测试的、经过验证的机器学习算法和技术的实现。因此,这些工具可能不包括来自最近研究的更多实验算法,这些研究尚未经过彻底审查和现场测试。在某些情况下,这些进步可能会对现有算法进行增量改进,在其他情况下可能会提供革命性的新功能。将这些技术集成到面向用户的系统中几乎总是需要定制的实现工作,包括将算法从正式研究论文中的数学符号转换为工作代码。还可能需要进行与系统性能和扩展相关的严格测试以及其他实施工作。这项工作通常需要一个拥有先进理论机器学习知识和部署技术的大型开发团队。由于这些原因,这种方法在大多数情况下是不可取的。
对实验性机器学习技术感兴趣的设计师应该考虑加入更大的团队,这些团队更适合于让这些新兴技术为生产做好准备的多方面任务。
机器学习原型工具
原型设计是许多设计过程的重要组成部分。它帮助设计师勾勒出系统的基本功能,测试用户将如何与计划的功能交互的假设,并在转向成本更高、时间更密集的实现过程之前对这些功能进行微调。不幸的是,与机器学习相关的复杂体系结构和计算密集型培训过程对机器学习增强型系统的快速原型化提出了挑战。在适用交钥匙MLaaS解决方案的情况下,设计师可以相对轻松地输入他们的想法。但在所需功能需要定制数据集或代码的情况下,即使是基本原型的生成也可能需要大量的时间、精力和技术诀窍。目前,可用于辅助机器学习系统原型设计的工具数量有限,这种情况有望在未来几年发生变化。
同时,一些现有的工具可能有助于简化原型过程。从编程自由的Wekinator到数学ematica界面,再到编程密集型的Keras,下面介绍的一系列工具可以作为学生和设计师的垫脚石,帮助他们在亲身体验机器学习系统和工作流程的同时,为现实世界的设计问题提供原型解决方案。
Wekinator
Wekinator是Rebecca Fiebrink创建的一个免费开源工具。它允许用户为各种输入设备开发实验性手势识别系统和接口控制器,包括网络摄像头、麦克风、游戏控制器、Kinect、Leap Motion、物理执行器(通过Arduino)、键盘和鼠标。与许多机器学习工作流不同,Wekinator不需要对数据集进行编程或争论。相反,软件引导设计师完成一个交互过程,在这个过程中,设计师通过向机器演示来定义特定的手势,然后将该手势与所需的输出动作关联起来。为了帮助原型设计和与其他软件的集成,可以使用流行的OSC原型将经过培训的Wekinator模型设置为广播其输出事件。尽管Wekinator仅适用于机器学习功能的特定领域,但它为原型设计和设计机器学习增强型多模式用户界面提供了强大的媒介。见图1-24。
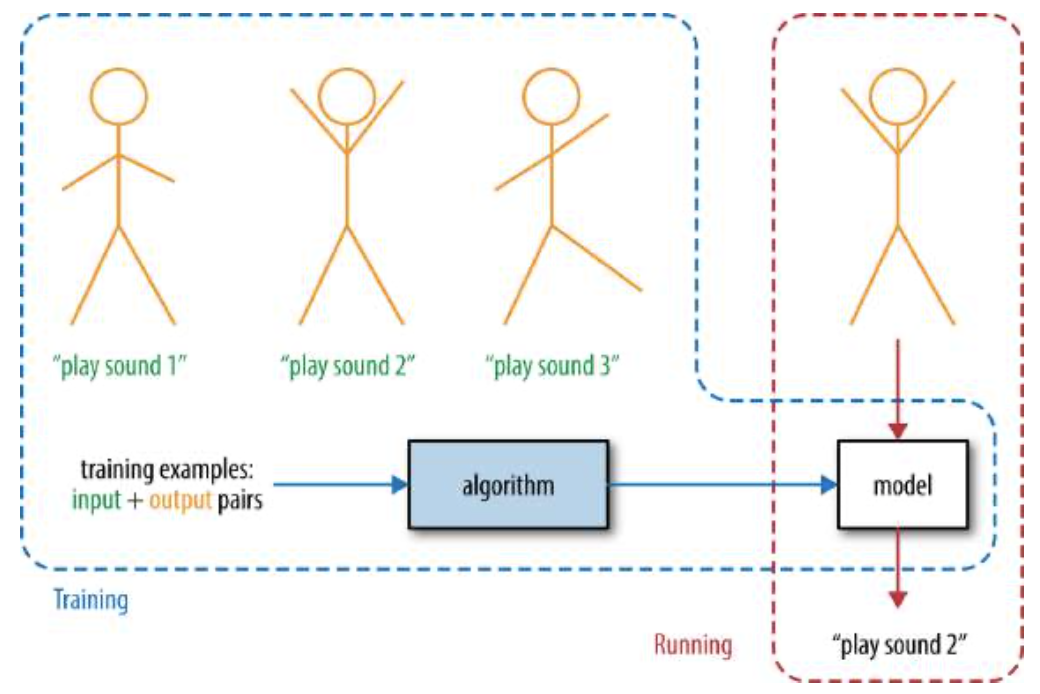
图1-24 使用Wekinator Wekinator设计事件触发器的工作流可从以下网站下载: http://www.wekinator.org.
Mathematica
流行的技术计算平台Mathematica在其最新版本Mathematica10的基础上增加了一系列自动机器学习功能。该工具的特点是拥有一个完善的用户界面,不需要对编程有深入的了解,尽管对基于文本的脚本有一些基本的熟悉将对新用户有所帮助。其机器学习功能可应用于多种数据类型,其自动数据预处理和模型选择功能将帮助用户获得良好的结果,而无需大量尝试和错误,也无需深入了解特定模型的训练参数。Mathematica为一系列常见的机器学习任务提供全包支持,如图像识别、文本分类以及通用数据的分类或回归。数据集可以通过交互式可视化界面加载。Mathematica的文档非常丰富,并将功能建议和自动完成等辅助工具直接嵌入其界面。见图1-25。

图1-25。Mathematica中手写数字的分类
Mathematic可从以下网站: https://www.wolfram.com/ mathematica.
Keras
该工具需要更深入的编程知识,以及对基于命令行的安装过程的熟悉,但为高性能机器学习工具包TensorFlow和Theano提供了相对用户友好的包装。虽然需要编程,但Keras致力于快速原型化高度定制的机器学习系统。它提供了高级API和模块化组件,将帮助用户组装通用的机器学习体系结构,如卷积神经网络和递归神经网络。此工具不适用于新用户,但可能有助于弥合上述工具与更多开放式平台之间的差距,如第70页下一节“开源机器学习工具包”中列出的平台。
Keras安装说明可在以下网址找到: http://keras.io.
将机器学习融入设计过程
在思考如何教一个人一项复杂的任务时,很难将任务分解为一系列定义明确的离散步骤。在设计机器学习增强型系统时也会出现同样的问题。我们可能会想,“智能助手应该了解用户的情绪状态,并做出相应的反应。”但这意味着什么?虽然从人类的角度来看,答案似乎相对清晰,但从计算角度来看,答案就不那么清晰了。用户的情绪状态是由他的词语选择决定的吗?如果是这样,我们如何确定哪些词与哪些情绪相关?
将机器学习引入设计项目的第一步应该始终是尽可能清晰、全面地定义学习问题。我们将为机器提供哪些输入参数?我们需要什么样的产出?什么样的培训数据将举例说明这些输入和输出之间的相关性?
一旦你确信学习问题已经得到了很好的定义,暂时把技术细节放在一边,将机器学习组件视为系统整体架构中的一个黑匣子功能可能会有所帮助。这意味着,就像一个数学运算,比如平方根,你知道输入和相应的输出应该是什么,但你不一定知道平方根在这个函数中是如何计算的。这样,当你勾勒出系统的用户和数据流时,机器学习组件可以像软件的任何其他功能一样对待。例如,图像识别组件可以被视为一个框,它将图像作为输入并输出一系列单词。这种方法允许设计师将机器学习功能整合到他们的系统中,而不会在重要的构思和素描阶段陷入技术细节的泥潭,这通常需要流畅的思维。
然而,与简单的数学函数不同,更难确定机器学习功能是否能满足您的需要,或者您是否能够找到适当的训练数据来实现所需的行为。因此,这个素描过程应该小心处理。如果机器学习增强功能对软件的整体行为至关重要,且其有效性受到质疑,那么在围绕该机器学习功能设计其他功能之前,先对黑匣子功能性进行原型化以测试假设是很重要的。上一节中列出的原型工具可能有助于了解功能是否可以实现。
这个原型化和验证假设的过程可能会非常耗费人力。它可能需要采购和清理数据集、选择机器学习模型和漫长的培训过程,才能看到任何初步结果。然而,随着时间的推移,当你更多地使用机器学习系统时,你会对什么可能起作用以及什么样的学习问题可能更敏感或脆弱产生直觉。重要的是要积极参与,尽可能多地获得第一手经验是至关重要的。合作也非常重要。如果你与机器学习工程师合作,试着形成自己对某个特定想法是否可行的意见,然后征求工程师的意见。如果她的意见与你的意见不一致,可以提问。你的哪些假设是错误的?你没有考虑哪些因素?机器学习可能是一门严谨的科学,但它仍然是你可以建立直觉的东西。
当你朝着这种直觉努力时,从更简单的机制开始,朝着更复杂的机制发展。举例来说,凭直觉推测一个玩危险游戏的人工智能是如何构建的并不容易。事实上,IBM的Watson并不是由一个机器学习系统组成的,而是由许多相互关联的组件组成的。在设计中引入机器学习功能时,请将其视为单独的组件。如果你不能清楚地解释一个特定的组件应该做什么,以及它应该在什么数据上进行训练,那么机器很可能也无法解决这个问题。
学习是一种抽象现象,但它在设计的个体组成部分中的作用不一定是抽象的。在任何设计过程中,为了平衡复杂系统的许多相互关联的特性,有必要在功能的高级目的和特定技术约束之间来回思考。对于机器学习增强的功能,找到这种平衡可能很困难。但是,如果设计师愿意进行实验,质疑自己的思维,并在这样做的过程中不断增强他们对机器学习本质的直觉,他们就可以迎接这一挑战。
结语
在许多方面,机器学习是一种解决问题的方法。机器学习算法能够在提供给它们的数据中发现复杂的模式,但只有当它们经过训练,注意到有用的东西时,它们才有用。对于金融和医学等一些领域,该领域的现有需求与机器学习系统的能力之间存在着明显的联系。金融机构一直以来都需要工具来帮助根据过去的表现预测市场的未来行为。医疗机构一直需要能够预测患者预后的工具。机器学习只是为实现这些目标提供了更有效的机制。
在未来几年里,无数其他领域将通过机器学习进行变革。然而,在许多情况下,这种转变并不是将现有目标与实现这些目标的新机制联系起来。这将需要发现新的前提和思维模式,这些前提和思维模式暴露出只有通过机器学习才能看到的全新机会和目标。
有远见的设计师巴克明斯特·富勒在他的《地球号宇宙飞船操作手册》一书中写道, “如果你在一场海难中,所有的船都不见了,那么一个足以让你漂浮的钢琴顶部就会成为一个偶然的救生圈。但这并不是说,设计救生圈的最佳方式就是设计一个钢琴顶部。我认为,我们正紧紧抓住许多钢琴顶部,接受昨天的偶然设计,认为这是解决问题的唯一途径。”“解决给定的问题。”11
回顾数字设计工具本身的历史,我们可能会看到数不清的钢琴桌面。例如,视频编辑软件提供的许多功能都参考了前面的平板电影编辑词汇。虽然这些参考资料有助于将一代电影人转变为数字工作流程,但它们几乎没有发现新兴视频媒体中的新可能性。发现一种媒介的独特可能性需要实验、一双新鲜的眼睛,以及对现有范例进行思考的意愿。正是在这里,设计师将被证明对机器学习的未来至关重要。
为了充分利用机器学习系统的技术可能性,设计师将在一定程度上依赖编程人员。但程序员也必须依靠设计师来寻找突破性的应用程序和思考这些通用工具的方式。为了促进与程序员的合作并开发新的应用程序,设计师不一定需要了解与机器学习技术相关的所有数学细节。尽管如此,要想自由地、创造性地思考一种媒介的可能性,理解其潜在属性和约束是很重要的。正如鲍勃·迪伦所说,“要想生活在法律之外,你必须诚实。”换句话说,你必须理解规则,才能知道哪些是值得弯曲或打破的。
为此,为了让机器学习领域在未来得到扩展和繁荣,设计师必须让自己沉浸在这项技术的可能性中,通过他们看待和思考世界的方式改变这项技术。
更进一步
及时了解该领域的最新进展
arXiv
arXiv(发音为“archive”)是印前科学论文的存储库。机器学习领域的许多前沿进展首先发布在arXiv上。关注发布到arXiv的最新论文是跟上最新进展的最佳方式之一。但是,由于每个月都有数千篇不同领域的论文被发布到该网站上,找到与你的特定兴趣相关的论文并不总是那么容易。
arXiv Machine Learning: http://arxiv.org/list/stat.ML/recent
arXiv Neural and Evolutionary Computing: http://arxiv.org/list/cs.NE/recent
arXiv Artificial Intelligence: http://arxiv.org/list/cs.AI/recent
CreativeAI
找到关于arXiv的相关论文可能是一个挑战。Crea-tiveAI网站策划了一系列与设计和艺术直接相关的机器学习项目。该网站上展示的项目包括书面论文、视频,甚至代码示例。CreativeAI强调了将机器学习融入创造性应用的许多鼓舞人心的可能性。
CreativeAI: http://www.creativeai.net
在arXiv论坛上,保持对人工智能和其他学习资源的关注是另一个重要的方法。读者可以找到最近发表的文章的链接,以及关于机器学习研究人员或设计师感兴趣的主题的广泛讨论。
Reddit Machine Learning: https://www.reddit.com/r/machinelearning
Reddit Artificial Intelligence: https://www.reddit.com/r/artificial
Deep Learning News & Hacker News
最近建立的Deep Learning新闻网站以类似于上文讨论的Reddit论坛的方式对机器学习进行了专题讨论。更通用的黑客新闻讨论论坛还提供了许多关于最先进的机器学习技术的相关对话。
Deep Learning News: http://news.startup.ml
Hacker News: https://news.ycombinator.com
机器学习的进一步研究资源
在线课程
“Machine Learning for Musicians and Artists” taught by Rebecca Fiebrink:
https://www.kadenze.com/courses/machine-learning-for-musicians-and-artists/info
“Machine Learning” taught by Andrew Ng:
https://www.coursera.org/learn/machine-learning
“Neural Networks for Machine Learning” taught by Geoffrey Hin‐ ton:
https://www.coursera.org/course/neuralnets
机器学习的数学
“Some Basic Mathematics for Machine Learning” by Iain Murray and Angela J. Yu:
http://www.cogsci.ucsd.edu/~ajyu/Teaching/Cogs118A_wi10/Refs/basic_math.pdf
“Math for Machine Learning” by Hal Daumé III:
http://www.umiacs.umd.edu/~hal/courses/2013S_ML/math4ml.pdf
“Machine Learning Math Essentials Part I & II” by Jeff Howbert:
http://courses.washington.edu/css490/2012.Winter/lecture_slides/02_math_essentials.pdf
http://courses.washington.edu/css490/2012.Winter/lecture_slides/06a_math_essentials_2.pdf
“Immersive Linear Algebra” by J. Ström, K. Åström, and T. Akenine Möller:
http://immersivemath.com/ila/index.html
“Linear Algebra” by Khan Academy:
https://www.khanacademy.org/math/linear-algebra
“Probability and Statistics” by Khan Academy:
https://www.khanacademy.org/math/probability
“Differential Calculus” by Khan Academy:
https://www.khanacademy.org/math/differential-calculus
教程
“Deep Learning Tutorials”:
http://deeplearning.net/reading-list/tutorials
“A Deep Learning Tutorial: From Perceptrons to Deep Networks”:
“Deep Learning From the Bottom Up”:
https://www.metacademy.org/roadmaps/rgrosse/deep_learning
技术资源
机器学习即服务平台MLaaS
IBM Watson: http://www.ibm.com/smarterplanet/us/en/ibmwatson
Amazon Machine Learning: https://aws.amazon.com/machine learning
Google Prediction API: https://cloud.google.com/prediction
Microsoft Azure: https://azure.microsoft.com/en-us/services/machine-learning
BigML: https://bigml.com
ClarifAI: https://www.clarifai.com/
开源机器学习工具包
TensorFlow (C++, Python): https://www.tensorflow.org
Torch (C, Lua): http://torch.ch
Caffe (C++): http://caffe.berkeleyvision.org
cuDNN (C++, CUDA): https://developer.nvidia.com/cudnn
Theano (Python): http://deeplearning.net/software/theano
Scikit-learn (Python): http://scikit-learn.org
Shogun (C++, Python, Java, Lua, others): http://www.shogun.toolbox.org/
Spark MLlib (Python, Java, Scala): http://spark.apache.org/mllib
Deeplearning4j (Java, Scala): http://deeplearning4j.org
数据集
UCI Machine Learning Repository: http://archive.ics.uci.edu/ml
MNIST Database of Handwritten Digits: http://yann.lecun.com/exdb/mnist
CIFAR Labeled Image Datasets: http://www.cs.toronto.edu/~kriz/cifar.html
ImageNet Image Database: http://www.image-net.org
Microsoft Common Objects in Context: http://mscoco.org/home
关于作者
帕特里克·希布伦(Patrick Hebron)是纽约大学互动电信项目的常驻科学家和兼职研究生教授。他的研究涉及机器学习增强型数字设计工具的开发。他是Foil的创造者,Foil是一个新一代设计和编程环境,旨在通过机器学习的辅助功能扩展用户的创造性范围。帕特里克曾为众多企业和文化机构客户担任软件开发和设计顾问,包括谷歌、甲骨文、古根海姆/宝马实验室和爱德华·M·肯尼迪研究所。
翻译:银河诗人
既然来了,说些什么?