AI绘画可控性研究与应用
这是昨天在清华美院课程的文字稿和PPT,主要分享的是AI绘画可控性的研究和应用。梳理了一下AI绘画可控性的一些整体知识脉络,和最新发布的controlnet 1.1。
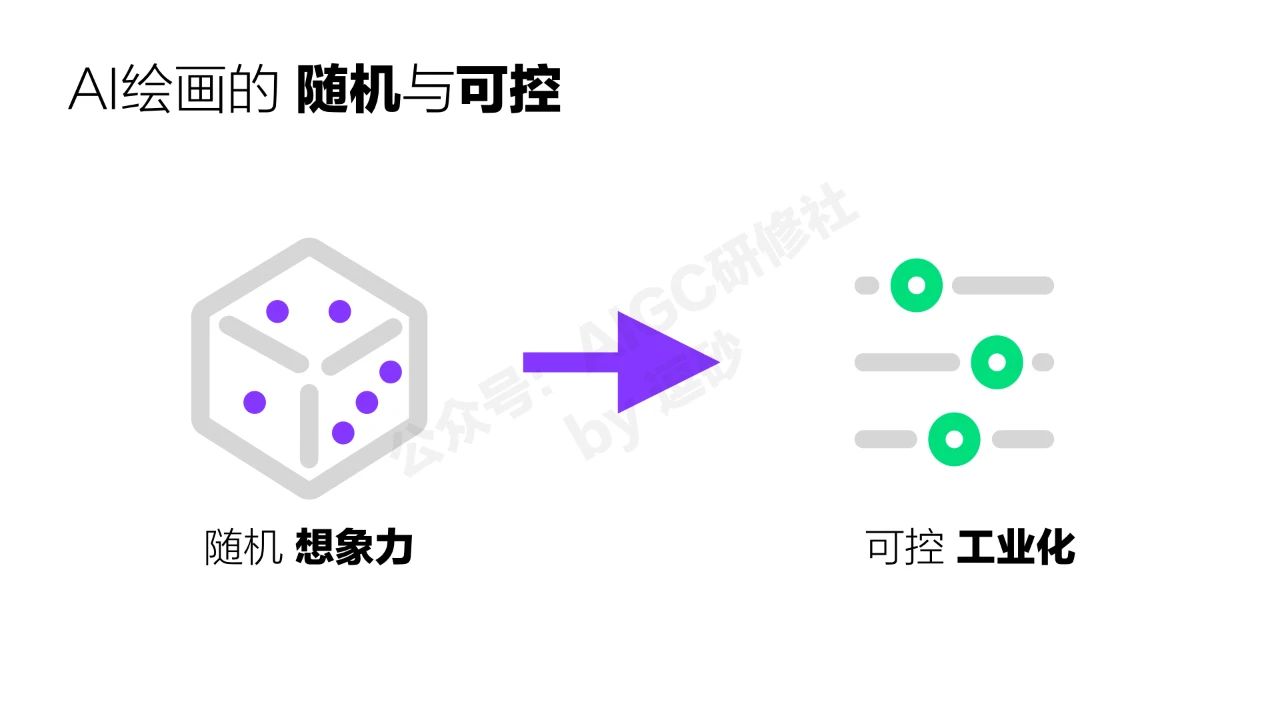
目前的AI绘画大部分都是基于diffusion这个模型的,我们可以注意到无论是现在最流行的开源的 stable diffusion 还是最开始的disco diffusion,它们都是基于扩散算法的,这个算法的优势在于它的随机性,随机性可以给我们带来很多意想不到的结果,扩散模型生成的每一张图都不一样。这个特性最大的好处就是可以带来无穷无尽的想象力,很多时候这些想象力甚至会超越人类自己。
但是这些随机性带来的想象力有一个很大的问题,就是它不可控。大家都戏称这种创作叫抽卡式创作,你也不知道最终的生成效果是什么样的。有时候运气好出来一张非常惊艳的图,但是不可复现,感觉跟你也没啥关系。
这就是去年开始早期AI绘画的状况,它虽然可以生成很多漂亮的图片了,但是它本质上还是一个玩具,因为所有的设计领域都需要对结果可控,对于设计师来说,不能修改,不能控制画面中的内容,无法精准的满足甲方爸爸的要求,这种工具也只能在早期头脑风暴的阶段使用。
但是后面出现的微调模型和controlnet,把这个状态打破了。所以我说controlnet的出现补完了AI绘画工业化生产的最后一块拼图。AI绘画这个工具正式进入设计师的工作流了。

我们现在回到AI绘画的可控性有哪些这个问题上。广义上来讲,AI绘画的生成结果可以通过下面几种方式控制。
第一个就是提示词,文生图的意思就是通过文字去控制画面。其实从去年到现在市面上有大量的教程教你如何去写提示词,我们把特别擅长写提示词的人称为提示词工程师。但是作为一个最广泛的控制手段,提示词有它的局限性,这个一会儿讲。
除了文字提示之外,我们还可以使用图片作为提示,也就是垫图。图片提示可以更加精准控制画面的构图和元素。
我们还可以使用AI绘画进行图片编辑,涂抹掉不想要的部分然后重新生成,这个技术最早出现在dalle2上,后面迅速被应用到了SD上。
在最近刚更新的controlnet1.1版本里其实把图像提示和图像编辑都整合进去了。我们今天会重点讲解controlnet1.1的功能。
最后还有一种控制方式也非常重要,叫微调模型,目前市面上最流行的微调模型叫lora。微调模型是通过收敛好的模型来更加精准控制输出的风格和元素。

我们刚刚提到了提示词控制画面有它的局限性,这个局限性主要体现在哪些方面呢?
下面这几张图是同一提示词在midjourney不同模型算法下的生成结果。我这里只使用了一个单词:女孩。我们可以看到在初代版本的人物生成结果是非常差的,这个跟早期disco diffusion 的效果类似。我记得去年4五月份还有很多人去花了大量时间研究怎么写提示词和调整参数让DD来画出一个像样点的人物图。
可是随着MJ算法的迭代和SD的出现,这些对提示词的研究瞬间就失去了意义。我们可以看到从MJ的第三代算法开始,人物生成已经越来越好了,三代算法对于一些手部的细节还有瑕疵。所以那个时候很多人嘲笑AI不会画手,但是最新版本的MJ算法已经解决了这个问题。
这个过程大家可以看到,提示词的生成效果极度依赖模型算法。所以我不建议花太多时间去研究提示词,提示词掌握到78分就差不多了,因为今天研究的东西,废了很多时间总结出来的规律可能新的技术一出来就完全失效了。
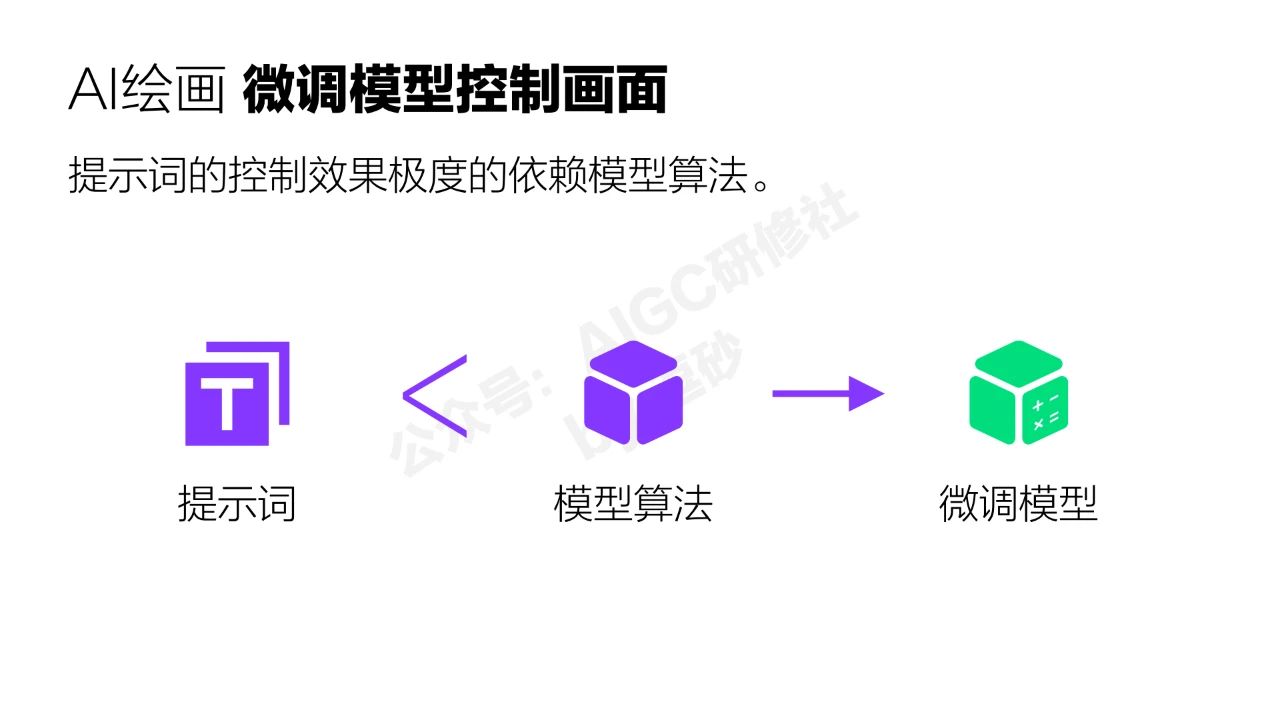
提示词的生成效果极度依赖模型,模型对生成结果的影响力远大于提示词,这个特性我们可以发现,通过微调模型去控制AI绘画的生成结果是一条比写提示词更有效的方式。

那么有哪些微调模型的自训练方式呢?
目前市面上主要有四种基于SD的微调模型方法。这四种方法里目前最流行的是一款叫lora的方法。
接下来我挨个介绍一下这四种方法的不同之处和应用范围。

首先是这个embedding的微调模型,它是通过使用文本提示来训练模型的方法。它的原理其实是通过在大模型的隐空间,找到对应特征的图像文字映射,然后通过打包重新定义这个映射来达到稳定输出特定图像的效果。
因为它并不会改动原有的大模型,所以文件非常小。效果也还好,并且对系统计算资源要求不高。

接下来这个 hypernetwork 其实是一种针对画风训练的微调模型。生成的模型文件要比embedding大一些。

前面这两种方法其实对于精准生成特定的物体效果都不太理想。dreambooth其实是目前为止最能稳定生成特定人或者物的微调模型。比如你有一个产品需要训练模型,dreambooth是最能让每个产品的细节特征都复现的。而且它不需要太多的数据集就可以训练,前面两种动不动就是几十张上百张的数据,它都不需要,dreambooth最少使用3~5张图就可以了。
话说回来dreambooth这么好,为什么现在不流行呢?因为它有个很大的问题就是模型文件太大了。而且对训练设备的性能要求很高。而且它的训练时间也很慢。

那么我们现在来看看目前最流行的lora。它其实是一种为了简化微调超级大模型需要大量的算力而产生的算法。它对于算力的要求不高,模型大小也适中,对于人物复现的精确度要优于embedding,已经很接近dreambooth了,最重要的是,它还能通过调整权重进行多模型的融合。我们可以像调鸡尾酒一样调整模型。

那么如何使用微调模型去应用到设计的工作流上呢?
其实方式有非常多,可以稳定生成特定的人物或者画风,在游戏,广告,动画等等领域都有非常大的应用空间。
这里我举两个在品牌营销方面的例子。
这是可口可乐通过微调模型稳定输出品牌logo,然后让用户自己去生成创意图片的一个活动。
除了这个国外的案例,去年国内也有一个类似的例子。

雪佛兰做过一个这样的活动。它通过让用户使用微调好的模型,稳定生成雪佛兰汽车在不同环境场景下的图片。通过这个方式让用户参与到品牌的宣传之中。

从这两个活动中我们可以发现什么?
过去的广告方式都是中心化的,广告公司生产创意,然后同一个内容让用户被动接受。
但是AIGC时代的营销方式,可以让每个用户即创意的生产者也是传播者和接收者。这很像病毒营销,但是比传统的病毒营销要好。
过去的病毒营销只是同一创意的转发,没有强的参与感,aigc让每个人都有参与创作的可能。
在这个语境下,设计师需要设计如何引导用户生产内容,而不是自己做一个多么厉害的作品。
微调模型延展资料
国外模型平台:
https://civitai.com/
国内模型平台:
https://draft.art/model
国内在线训练微调模型的产品:
右脑科技:https://work.rightbrain.art/ 目前免费
特赞 AIGC Playground:https://musedam.cc/home/ai 目前免费
无界AI:https://www.wujieai.com/pro 做了个colab的国内镜像版 收费
最后,我补充一些关于微调模型的资料,大部分市面上的教程,都是基于云端colab或者本地训练的,这个我就不重复了。
国内可以简单使用的产品还有下面几个。一个是右脑科技的产品,这个目前还是免费的效果也还不错。
还有的就是特赞的AIGC平台,这个目前暂时也是免费的,无界ai做了一个云端的镜像版本,这个是按算力收费的。
除了这几个训练模型的平台之外,国内外还有一些模型的聚合平台,这些平台上的模型大部分也都是可以调用的,大家自己训练好之后也可以上传到这些平台上。
微调模型部分就介绍到这里。接下来重点讲解contronlnet。

controlnet就是控制网的意思,其实就是在大模型外部通过叠加一个神经网络来达到精准控制输出的内容。
这个技术是今年二月由一个叫张吕敏的斯坦福博士生发布的。这个人也挺神奇的,他本科在苏州大学读的医学专业,后面才转到编程。但是他从大一就在发表人工智能相关的论文了。
从2017年开始一致专注在AI填色这个领域。之前全世界最火的一款AI填色的程序也是他开发的。
2月的时候他发布了controlnet1.0版本,在火遍全世界之后就消失了,然后最近又发布了1.1的加强版。今天的内容主要针对这个最新版本。
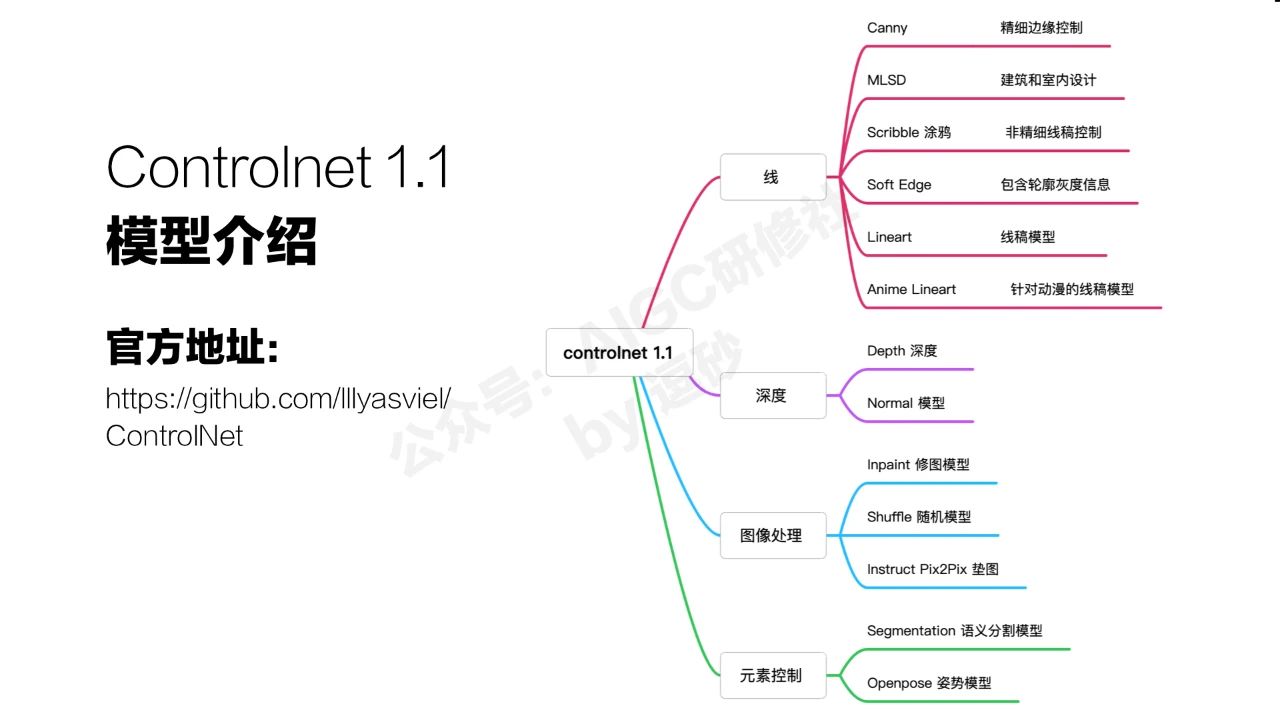
我们接下来看看controlnet一共包含多少种不同的控制方式。我这里大致分了四个类别,首先最大的这个类别是通过边缘或者线稿来控制,这个他分得非常细,一共有六种方式。这可能是跟他多年都在研究AI填色有关系。这六种模型里面,canny精细边缘控制用的最多,MLSD是主要应用在建筑和室内的生成上。还有涂鸦这种针对粗糙线条的控制。
可以提取深度信息的主要有两种,depth和normal,它们有一些细微的差别。
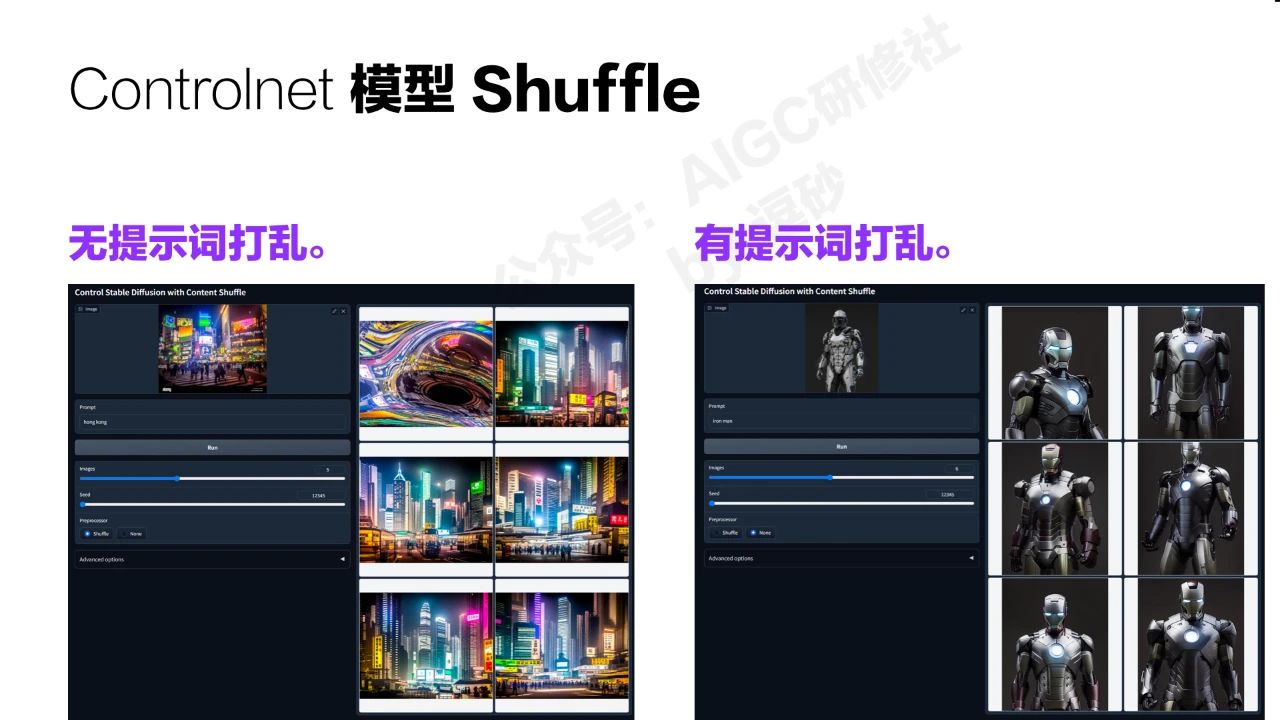
这个版本还增加了几种图像处理的模型,这几种其实都是SD和dalle2之前已经有的功能,不过这次controlnet做了整合。控制网开始包含一切的控制方式。
最重要的部分其实是针对元素的细节控制,这里有两种语义分割和openpose的姿势控制。

线的控制方式里,用的最多的就是这种。这里分享一个针对品牌的比较有趣的玩法,就是可以提取品牌的边缘然后生成各种有logo图案的大场景。


normal的模型可以跟3D软件结合进行快速的渲染,而不用通过贴图和各种复杂的材质设置。
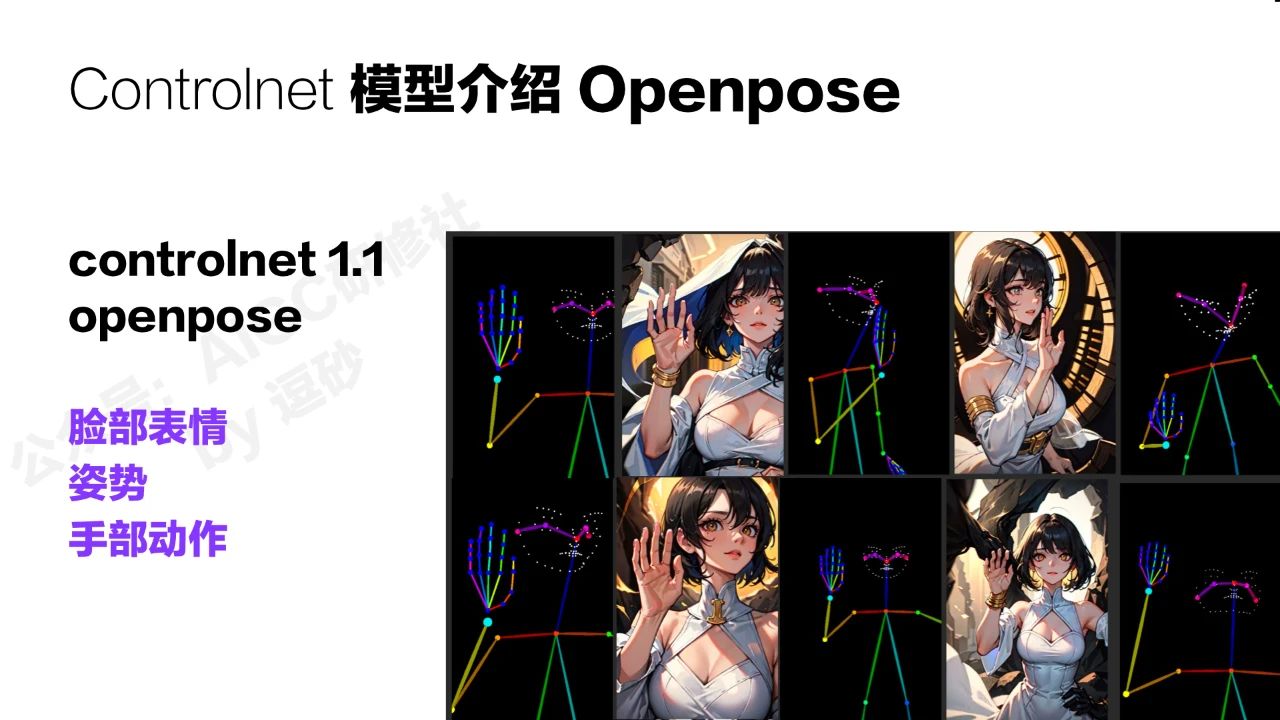
openpose应该是controlnet最重要的功能之一了,之前的1.0版本还只能控制大致的姿势,现在已经对手部和面部的细节也能很好的控制。我们既可以通过提取画面中的人物姿势去生成类似的图像,也可以直接用调整好的姿势图来生成相应的图。

openpose可以应用在漫画,动画,广告海报,游戏设计等诸多领域。不过目前只支持人物的姿势,对于动物和其他类别还不能生成。





https://docs.google.com/spreadsheets/d/1se8YEtb2detS7OuPE86fXGyD269pMycAWe2mtKUj2W8/edit#gid=0



github地址:https://github.com/facebookresearch/segment-anything
demo演示地址:https://segment-anything.com/demo
论文地址:https://arxiv.org/abs/2304.02643



Controlnet 延展资料
controlnet高阶组合用法合集
https://www.bilibili.com/video/BV1cL41197ji/?spm_id_from=333.337.search-card.all.click&vd_source=453933dd6891757733da4e4288779255
腾讯发布类似的controlnet的技术 T2I-Adapters
https://github.com/TencentARC/T2I-Adapter
AIGC教程:如何用Stable Diffusion+ControlNet做角色设计?
https://mp.weixin.qq.com/s/-5U3oHWP4c4YN0X4Vji0LA
提供免费 TPU 的 ControlNet 微调活动来啦
https://mp.weixin.qq.com/s/o7PTTyTXsLjo8ayq93W55w
控制名为 AI 的魔法,关于将 AI 绘画融合于工作流的案例和经验。
https://mp.weixin.qq.com/s/U-ks7Fs0fSDHJp6rCmAYoA
游戏要结束了:ControlNet正在补完AIGC工业化的最后一块拼图
https://mp.weixin.qq.com/s/-r7qAkZbG4K2Clo-EvvRjA
精确控制 AI 图像生成的破冰方案,ControlNet 和 T2I-Adapter
https://mp.weixin.qq.com/s/ylVbqeeZc7XUHmrIrNmw9Q
ControlNet项目地址
https://github.com/lllyasviel/ControlNet
ControlNet 的 WebUI 扩展
https://github.com/Mikubill/sd-webui-controlnet#examples
国内加入controlnet的产品
https://www.wujieai.com/lab 无界AI 付费
https://musedam.cc/home/ai 特赞 AIGC Playground 目前免费
原文:https://mp.weixin.qq.com/s/lWnbHACZqBG4OWDQNoCL7Q
既然来了,说些什么?