我搭 Harness 搭了几个月,最后发现最重要的那一层,叫进化
今年 2 月,OpenAI 发了一篇博客,叫《Harness Engineering: leveraging Codex in an agent-first world》。
读完那一刻我愣了一下。
原来我这一年多干的事,叫这个名字。
从 2025 年初我就在折腾这个东西。只是当时不知道这个词。
I — 我做这件事的起点
2025 年初,我有一个想法。
大模型不只是一个输入输出工具。
那时每个人都用 ChatGPT,都觉得它就是”聊天框 + prompt + 输出”。但它的输出方式其实有很大的调整空间,调整得够彻底的话,甚至可以通过 prompt 把它改造成一个”操作系统”。
老粉应该记得,那阵子我出了很多提示词框架 Prompt Framework 的视频。
那是我第一阶段的尝试。
2025 年 10 月 Skills 这个东西发布之后,我又做了一批 Skills 和 Sub-Agents 的编排方案。
目的一直没变,让 AI 从一个单纯的输入输出工具,变成一个能被我控制、能被我操作的系统。
我做了不少东西。踩了不少坑。但始终觉得差点什么。
差的是一个词。
直到今年 2 月,OpenAI 那篇文章出来。
Anthropic 也发了两篇文章,《Harness design for long-running application development》和《Scaling Managed Agents: Decoupling the brain from the hands》。
我读完之后想明白一件事:
我过去做的所有东西,都有一个统一的名字叫 Harness。而我一直做的事从 Context Engineer 成了 Harness Engineering。
这件事为什么重要,我用最简单的方式解释一下。
Harness 这个词的词源是”马具”。缰绳、马嚼子、马鞍。你有一匹快马,但马自己不知道要去哪。没有马具它可以狂奔,但你拉不住也带不走。
Anthropic 给 harness 下过一个最本质的定义:
“harness 编码的是’模型自己做不到的事’的假设。”
你每加一个 harness 组件,本质上都是在对模型说:”这件事你自己干不靠谱,所以我在你旁边装一个东西。”
OpenAI 那篇文章里还有一句话:
“当 agent 失败,修复几乎从来不是 try harder。”
他们一个小团队(从 3 人起步,后来扩到 7 人)五个月写了约 百万行代码,靠的就是每次 agent 翻车就问一个问题:
“什么能力缺失了?怎么让这个能力对 agent 既可见、又可强制执行?”
然后把答案编码进仓库。
Thoughtworks 的 Birgitta Böckeler 给这套东西做过一个分类:Harness 由三块组成,Guides(前馈引导)+ Sensors(反馈传感)+ Steering Loop(迭代校准)。
这三层我都懂。
我只是不知道有人给这三层起名字了。
II — 这次研究的产物:毒蛇产品经理 4.0
于是就有了我的新版 vibe coding 工作流。
读完那几篇文章之后,我决定重做一版。
把我过去一年多攒下的 Skills、Agents、编排方案,按 Harness 的概念重新结构化一遍,然后加入了我之前没有的进化系统。
跑在 Claude Code 上。覆盖从需求收集到发布的完整产品开发流程。
我先把整个文件结构贴出来。
project/├── Product-Spec.md # 产品需求文档(自动生成)├── Product-Spec-CHANGELOG.md # 需求变更记录(自动生成)├── Design-Brief.md # 设计规范文档(可选)├── DEV-PLAN.md # 分阶段开发计划(自动生成)├── <project-name>/ # 项目代码│ ├── src/│ └── ...└── .claude/├── CLAUDE.md # 主控配置├── EVOLUTION.md # 进化引擎规则├── settings.json # Hook 配置│├── agents/ # 4 个 Sub-Agent│ ├── implementer.md # 编码实现者│ ├── code-reviewer.md # 代码审查者│ ├── feedback-observer.md # 反馈观察者│ └── evolution-runner.md # 进化引擎执行者│├── skills/ # 8 个主 Skill + 3 个辅助 Skill│ ├── product-spec-builder/ # 需求收集│ ├── design-brief-builder/ # 设计规范│ ├── design-maker/ # 设计图制作│ ├── dev-planner/ # 开发计划│ ├── dev-builder/ # 项目开发│ ├── bug-fixer/ # Bug 修复│ ├── code-review/ # 代码审查│ ├── release-builder/ # 构建发布│ ├── skill-builder/ # 创建新 Skill(进化用)│ ├── feedback-writer/ # 记录反馈│ └── evolution-engine/ # 扫描进化建议│├── hooks/ # 6 个 Hook 脚本│ ├── pre-commit-check.sh│ ├── auto-push.sh│ ├── stop-gate.sh│ ├── detect-feedback-signal.sh│ ├── mark-review-needed.sh│ └── check-evolution.sh│├── feedback/ # 反馈积累│ ├── FEEDBACK-INDEX.md│ └── *.md│└── templates/├── feedback-index-template.md└── feedback-topic-template.md
这是我现在用的全部东西。
下面我按层拆开讲。
III — 8 个 Skill:给 AI 装方法论
Skill 是 Harness 的 Guides 层,在 AI 动手之前告诉它”怎么做”。
我定义了 8 个主 Skill,覆盖产品开发全流程:
- product-spec-builder — 需求收集
- design-brief-builder — 设计规范
- design-maker — 设计图制作
- dev-planner — 开发计划
- dev-builder — 项目开发
- bug-fixer — Bug 修复
- code-review — 代码审查
- release-builder — 构建发布
每个 Skill 是一个独立的 Markdown 文件,描述这个阶段的方法论和验收标准。
Skill 不是 prompt。Skill 是动作要领。
比如 bug-fixer 这个 Skill 不是”看到报错就改”。它是一套四阶段调试法:收集证据 → 分析模式 → 假设验证 → 实施修复。核心原则:不猜不试,一次一个,改完回归验证。
再比如 product-spec-builder。它不是让你写一份需求文档扔给 AI。它是反过来,AI 通过多轮追问帮你把模糊的想法变成结构化的需求。问到你自己都没想过的细节。然后帮你生成一份面向 AI 的 Product Spec。
面向 AI 的。不是面向人的。
这个区别很大。
面向人的需求文档讲用户故事、讲情感、讲愿景。面向 AI 的需求文档要逐条可执行,要覆盖所有边界情况,要明确列出交付物。后者的字不用写得好看,句子可以短,重点是让 AI 读完能干活。
一个人看不下去的需求文档,可能正好是 AI 最好用的需求文档。
为什么要把工作拆成 8 个独立 Skill,而不是塞到一个大而全的超级 Prompt 里?
两个原因。
一是模型的 context window(上下文窗口)就那么大。 你把 8 个Skill全塞进去,AI 读每一条指令的时候都要跟其他 7 份无关的指令竞争注意力。
当一切都重要,就没有什么是重要的。
Skill 是按需加载的。开发阶段就加载 dev-builder,review 阶段就加载 code-review。每次加载,都是一次清晰的注意力焦点。
二是独立加载可以配合 Sub-Agent 的独立上下文窗口机制。
这一点很关键,每个 Sub-Agent 派发时,它自带一个独立的 context window,跟主 Agent 是隔开的。
比如 code-reviewer 被派发的时候,它加载的是 code-review 这一个 Skill,占用的是它自己的 context,不挤占主 Agent 的空间。主 Agent 派完就回去处理别的。
再比如主 Agent 根据开发量判断要并行开发,可以同时派发多个 implementer Sub-Agent,每个各自独立加载 dev-builder skill,各自的 context 互不干扰。
如果所有方法论塞在一个主Agent里,Sub-Agent 就没得独立上下文这一说了。 Skill 拆开 + Sub-Agent 独立上下文,两件事合起来才是完整的上下文管理策略。
除了主要的 8 个,还有 3 个辅助 Skill:
- skill-builder 用来创建新 Skill(进化系统会用到)
- feedback-writer 用来记录反馈(由 sub-agent 调用)
- evolution-engine 用来扫描进化建议(由 sub-agent 调用)
这 3 个不是给人用的。是 harness 系统自己给自己用的。
IV — 4 个 Sub-Agent:执行层的防火墙
主 Agent 是调度者。真正干活的是 Sub-Agent。
我有 4 个:
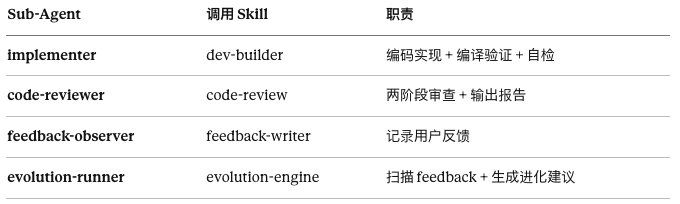
关键的设计是,每个 Sub-Agent 每次派发都用全新实例,不继承之前的上下文。
主 Agent 把每个任务的完整上下文打包好喂给 Sub-Agent,但不传 session 历史。
这个机制叫 Context Firewall(上下文防火墙)。
为什么要这样?
因为如果上一个任务中 AI 形成了某个错误假设,这个假设会跨任务污染下一个任务。一旦污染发生,你会看到 agent 在错得越来越远的路上一路狂奔,而且每一步都”有道理”,因为错误假设在它的 context 里是连贯的。
隔离不是优化。是隔离保证。
这里我要拎出一个最典型的例子:code-reviewer。
为什么 review 要单独开一个 sub-agent?而不是让写代码的 agent 自己 review 一下?
因为 agent 评价自己写的代码,永远是自吹。
这不是模型的问题。这是结构性问题。让同一个实例既当运动员又当裁判,它会客气。它会说”这个实现基本满足需求”、”有小瑕疵但整体可用”。
Anthropic 在 3 月那篇文章里讲得很狠:
“把裁判单独拎出来、再把它调严厉,远比让 generator 自我批判来得可行。”
我这里的 code-reviewer 就是独立拎出来的裁判。两阶段审查:
Stage 1 查 Spec 合规,对照需求文档逐条检查代码。有没有漏实现?有没有多做了 Spec 没写的东西?
Stage 2 查代码质量,命名、类型、结构、安全。
Stage 1 严重问题卡死在 Stage 1,不进 Stage 2。两 Stage 都 PASS 才自动 commit + push。
这是我整个系统里最重要的推理型 Sensor。
V — 6 个 Hook:确定性的硬卡
Hook 是 Harness 的 Sensors 层的另一半。
Sensors 分两种:
计算型:确定性脚本,不依赖模型判断,跑得快,成本低。
推理型:靠另一个 agent 做语义级判断,成本高,但能做计算型做不了的事。
上面讲的 code-reviewer 是推理型。
下面这 6 个 Hook 全部是计算型的。
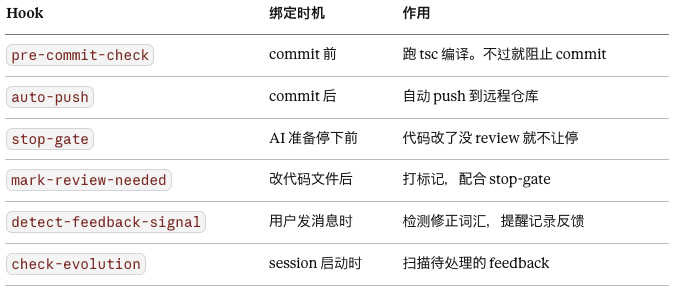
这 6 个脚本做的事有一个共同特点,它们不讲道理。
编译不过就是不让 commit,跟你没得商量。代码改了没 review 就是不让停,AI 说什么都没用。
你跟它讲道理它就会找借口。所以这一层关键是硬卡。
这里有一个容易被忽略的点,计算型 Sensor 是整个 Harness 里最长寿的一层。
为什么?
因为它不依赖模型能力。
不管模型是 Opus 4.5 还是 Opus 5.0 还是 6.0,编译器还是编译器,lint 还是 lint,测试还是测试。这些规则永远不会过期。
模型变强了,很多软性规则可以拆。
但这一层不会拆。
这个结论后面会用到。
VI — 进化系统:让这一切会自己长
好,前面三层讲完。
Skills 是 Guides。 Hooks + code-reviewer 是 Sensors。
但这两层都还没解决一件事:
你的 Harness 会随着时间生锈。
今天你搭的规则,明天会过时。 今天你没想到的坑,明天会栽进去。 今天你觉得够用的 Skill,跑五次就发现有漏洞。
如果没有一套机制处理”变”字,你的 harness 三个月就是垃圾。
所以我有第三层,Steering Loop,进化系统。
这是我这次研究里花最多时间的一块。
四层。
第一层:经验沉淀(你根本不知道它发生了)
你跟 AI 说话的时候,每次说”不是这样”、”你又忘了”、”不对”、”我不是让你这么干”这类词:
后台的 detect-feedback-signal 脚本会捕捉到。
然后主 Agent 派一个 feedback-observer sub-agent,在后台静默记录这条反馈,写进 .claude/feedback/ 目录。
这一步你根本感知不到。
你不需要说”帮我记下来”。你骂它的那一瞬间,系统已经记下来了。
这一层的精髓是无感。就像自动备份。
第二层:规则毕业(3+ 次)
每次 session 启动,evolution-runner 扫一遍 feedback 目录,统计每条反馈的出现次数。
同一条反馈出现 3 次以上 → 它提议把这条反馈”毕业”,升级成写进对应 Skill 或 CLAUDE.md 里的正式规则。
举个我真实踩过的坑。
早期我反复遇到一个问题:AI 改了 UI 之后只改了 Spec 和代码,忘了同步更新设计稿。
我骂过它三次。
第四次 session 启动的时候,evolution-runner 跑出来提议:
“要不要把’UI 变更必须同步更新设计稿’写成正式规则?”
我说要。它改了 Skill 文件。
从那之后再也没犯过这个错。
注意这里的关键,它不会自动改。它只提议。我确认了才改。
自动改规则是危险的。你不知道它理解得对不对。所以进化必须是”建议 + 用户确认”。不能绕开人。
第三层:Skill 优化(评分偏低)
每个 Skill 执行完之后,feedback-observer 可以给这次执行打分,准确性、覆盖度、效率、满意度。
evolution-runner 扫到某个 Skill 的历史评分持续偏低 → 提议优化这个 Skill。
我那个 design-maker skill 就被优化过一次。
跑了几次之后我发现它总漏东西。主页面都对,但那些跳转中间的弹窗、空状态、确认对话框、错误提示,永远不在初始规划里。用户每次都要提醒。
评分持续 2/5。
evolution-runner 提议:
“这个 Skill 的覆盖度偏低,建议修改方法论,加入’走查每一条用户流程,逐步枚举所有中间屏幕’的步骤。”
我确认。Skill 被改。下次执行就不漏了。
第四层:造新 Skill(5+ 次无覆盖)
最顶一层。
某种操作模式反复出现,但现有 Skill 都没覆盖 → 提议造一个全新的 Skill。
这一层触发概率不高。但它是让 harness 系统能自我扩展的机制。
你今天定义的 8 个 Skill,不是上限。
用得够久,它会自己告诉你:”你需要第 9 个。”
把这四层放一起看,你会发现一件事。
OpenAI 那个小团队五个月写约百万行代码,靠的是每次 agent 翻车就问一个问题:“什么能力缺失了?怎么让这个能力对 agent 既可见、又可强制执行?” 然后人类介入、分析、把这条规则编码进仓库、让同样的错不再发生。
我的思路也差不多,但我希望是让这个过程自动化。
你骂一次是经验。 骂三次变规则。 骂到一整个 Skill 都不行就优化它。 骂到这个 Skill 根本不存在就造一个新的。
你每次被气到的瞬间,都在让系统变得更厉害。
这才是一个 harness 真正值钱的地方。
不是它一开始设计得多漂亮。
是它能自己长。
VII — 几个容易被忽略但致命的细节
做这套东西的过程中,有几个细节我一开始没想到,但后来发现非常关键。
第一个:feedback 和 memory 是两套系统,不能混。
Claude 本身有 memory 机制,记住用户偏好、跨 session 的上下文。很多人搭 harness 的时候会把用户的修正反馈塞进 memory。
错了。
memory 是给用户看的,”这个用户喜欢深色主题”。 feedback 是给系统进化看的,”这个场景下 AI 会漏掉设计稿同步”。
两者用途不同、生命周期不同、处理机制不同。塞进 memory 里,进化引擎扫不到;塞进 feedback 里,用户偏好又丢了。
我在 CLAUDE.md 里明确写了这条规则。分清楚这两个是关键。
第二个:self-evaluation(自我评估)的失败是结构性的,不是能力性的。
agent 评价自己写的代码永远是自吹,这不是因为模型不够强,是因为同一个实例既当运动员又当裁判,天然会客气。
这意味着:即使未来 Opus 10 出来,让它自评自己的代码,还是会自吹。这个问题不会被模型能力解决。
所以”独立 reviewer agent”这一层 harness,结构性原因决定它会长期存在。
第三个:agent legibility(AI 可读性)比 code readability(代码可读性)更重要。
OpenAI 有个说法,”从 agent 的视角,任何它在运行时上下文里访问不到的东西,effectively 不存在。“
知识如果只在飞书里、Obsidian 里、Notion 里、你的脑子里,对 agent 来说都不存在。
一个重要决定如果只记录在聊天里,而没有写进仓库、写进 CLAUDE.md、写进某个 Skill,它对 agent 来说就等于没有发生过。
我做 feedback 系统的时候踩过这个坑。我以为跟 AI 说一次就够了。后来发现没写进文件系统的反馈,下个 session 就消失了。
所以现在所有重要决定都落到文件。feedback 目录是系统的”组织记忆”。
第四个:给你的 harness 分结构性和权宜之计两类。
不是所有 harness 组件都同样重要。
结构性的,解决结构性问题的,比如独立 reviewer、context firewall、编译检查、lint。这些跟模型能力无关,长期有效。
权宜之计的,解决当前模型能力不足的,比如某些 prompt 提醒、某些流程约束。这些会过期。
这两类规则的命运不一样。结构性的要保护。权宜之计的要定期审核。
VIII — 模型变强了,这套东西会废吗
这是我花最多时间思考的一个问题。
也是所有人第一次看到这种复杂系统时会问的问题:
“我花几个月搭这套东西,明年 Opus 5.0 出来,是不是全都白搭了?”
Anthropic Labs 的工程师 Prithvi Rajasekaran 在 3 月下旬的文章里给了一个答案,我看完挺受启发:
“有意思的 harness 组合空间不会随模型变强而缩小。它只是在移动。AI 工程师真正有意思的工作,是持续去寻找下一个新颖的组合。”
他给了实验数据。
从 Opus 4.5 换到 4.6 的时候,他主动拆掉了 harness 的一半:
Context reset 全删。4.5 context 快满会仓促收尾,得硬 reset;4.6 这个毛病没了。 Sprint 拆解全删。4.5 得把任务拆成小块才能连贯;4.6 能直接连续跑两小时。
但 evaluator 留下了。只是位置变了。
4.5 时代 evaluator 处处抓到 bug。4.6 时代很多原本需要 evaluator 的场景,模型自己就搞定了。但能力边界外移之后,新的边界之外的任务仍然需要 evaluator。
同时他加了新的引导,让 generator 在生成的 app 里嵌入能用工具驱动功能的 AI Agent。这是新模型能力腾出空间之后才值得做的事。
净总量没变。复杂度只是换了位置。
这就是”harness 会移动,不会缩小”的实证。
所以真正的问题从来不是”模型变强之后 harness 会不会过时”。
真正的问题是:你的 harness 会不会跟着模型一起长。
一个静态的 harness,半年后就是你给自己的天花板。你在用新模型跑去年的轨道。
一个会进化的 harness,每次模型升级都是它升级的机会,拆掉没用的,加上新解锁的。
这就回到第六章那个进化系统。
没有它,你搭得再精致也是一次性的。 有了它,你搭得再粗糙都是会长大的。
IX — 我从这次研究里给自己总结了三条
第一,给系统加一个”harness 修剪仪式”。
每次 Claude 新模型发布,派一个 agent 跑一遍所有 Skill 规则和 Hook,逐条压力测试,这条规则在新模型上还 load-bearing 吗?
过时的规则不是中立的。它会占 context、占注意力、甚至会误导更聪明的模型。
harness 需要修剪,跟代码库需要 refactor 是一个道理。
我目前的进化系统擅长”加”,不擅长”删”。下一步我要给它加一个”修剪”机制。
第二,在每条规则上打”结构性 / 权宜之计”标签。
第七章讲过这个分类。我现在要把这个分类做成元数据。
feedback 文件的 frontmatter 里加一个字段:nature: structural | contingent。
Skill 规则也一样。哪些是跟模型能力无关的(结构性),哪些是解决当前能力短板的(权宜之计)。
这样模型升级的时候,我可以一眼识别哪些要保留、哪些要审核、哪些要拆。
第三,把 CLAUDE.md 做成”元 harness”而不是”具体 harness”。
Anthropic 最近发了一篇文章叫《Managed Agents》,他们把 session、harness、sandbox 虚拟化成稳定接口,具体实现可替换。
思路是:harness 会变,但 harness 的接口可以稳定。
我现在的 CLAUDE.md 里把具体 Skill 名、具体 Hook、具体 Sub-Agent 都硬编码了。这其实是脆弱的,将来如果 Skill 数量变了、结构变了,CLAUDE.md 要大改。
更好的做法是:CLAUDE.md 描述”有 N 个 Skill 负责 X,有 M 个 Agent 负责 Y”,具体是谁让 evolution-runner 去决定、或者交给 skill-builder 去生成。
这是我下一版要做的方向。
X — 最后一句
Vibe Coding 真正的分水岭不是谁的 prompt 写得更好。
不是谁用的模型更强。 不是谁背了更多技巧。
是谁有 harness,以及谁的 harness 会进化。
你今天用的每一条 harness 规则,都来自某次你被 AI 气到的具体瞬间。
你的 harness 就是你踩过的坑的地图。
所以它好不好,不取决于你读了多少前沿文章、背了多少术语。
不是你在 GitHub 上 clone 了多少个所谓开源又好用的 skill。 不是你抄了多少个头部博主公开的所谓开源方案。 不是你的 .claude/ 目录堆了多少东西。
龙虾火的那阵子,一堆人疯狂安装 skill、囤开源项目,看着热闹,真正跑通的、真正用顺的没几个。
因为别人的 skill 再精巧,那是别人从他的坑里爬出来的地图。套你身上不合身。
你的 harness 的好坏,取决于你有没有认真对待,自己被气到的那些瞬间。
原文:
https://mp.weixin.qq.com/s/7udJ267oN7fL_5QjA7RBeg
既然来了,说些什么?