那些说UI会消失的人,把人机交互理解错了一半
最近很多人都在说:”Agent来了,UI会消失,未来只剩CLI和自然语言。”其实这个判断里藏着一个很普遍、也很致命的认知错误。而且这个错误,恰好把人机交互的未来判断,砍掉了一半。
先说结论:消失的不是UI,是”预制的UI”
喊”UI会消失”的人,通常举两类例子:一类是Claude Code、Cursor这种CLI式的编程agent,另一类是”以后直接跟AI说话就行了,谁还点按钮”。
听起来都对。但他们混淆了两件事:
作为输入入口的UI ≠ 作为信息呈现的UI
输入端的UI确实在被自然语言吃掉。这个方向没争议——表达意图这件事,自然语言的带宽比点击路径高一个数量级。
但输出端的UI不但不会消失,反而会爆炸式增长。
要理解这一点,得先回到一个最根本、也最容易被忽略的问题:人类到底是怎么接收信息的?
第一性原理:人类的感官带宽,天生不对称
这件事不是偏好问题,不是习惯问题,是硬件约束。
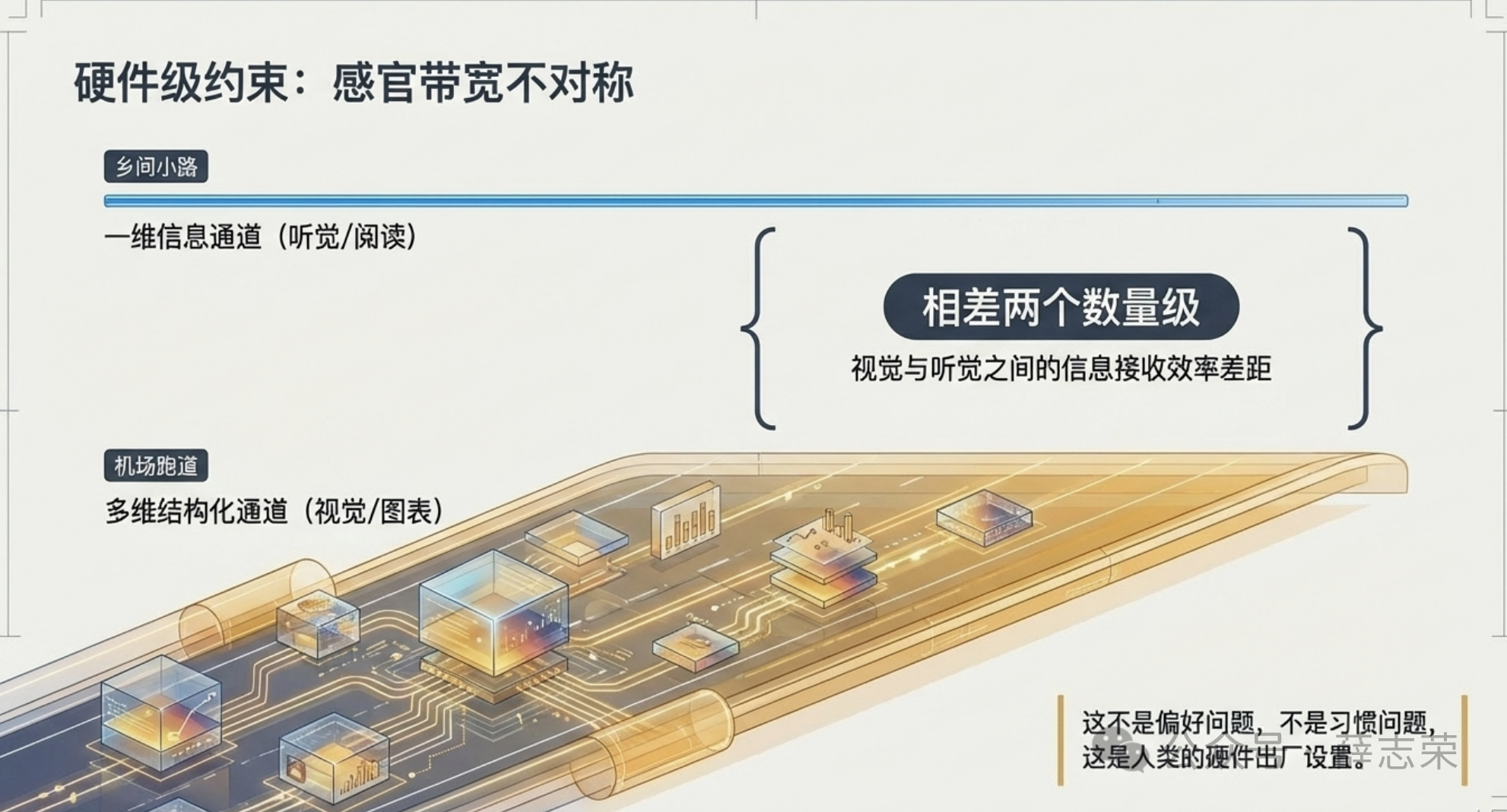 认知科学和信息论的研究大致估算过人类各感官通往大脑的信息通道带宽:视觉远远高于听觉,听觉又高于触觉,视觉和听觉之间的差距大约在两个数量级左右。这不是一点点差距,是一个在机场跑道、一个在乡间小路的差距。
认知科学和信息论的研究大致估算过人类各感官通往大脑的信息通道带宽:视觉远远高于听觉,听觉又高于触觉,视觉和听觉之间的差距大约在两个数量级左右。这不是一点点差距,是一个在机场跑道、一个在乡间小路的差距。
这意味着什么?意味着任何一维的信息通道——无论是语音流、还是CLI里一行一行滚动的文本——在物理层面就不可能跟视觉竞争。
你听一段3分钟的播客,和看一张信息图,后者传递的信息量可能是前者的几十倍,你花的时间却只有几秒钟。这不是播客做得不好,是听觉这个通道本身的带宽上限就摆在那里。
所以CLI再高效,它本质上仍然是一维的。命令一行行敲,输出一行行读。它擅长表达精确指令,但不擅长接收大量信息。
这是第一层硬约束。
第二层:结构化 vs 线性,不是一回事
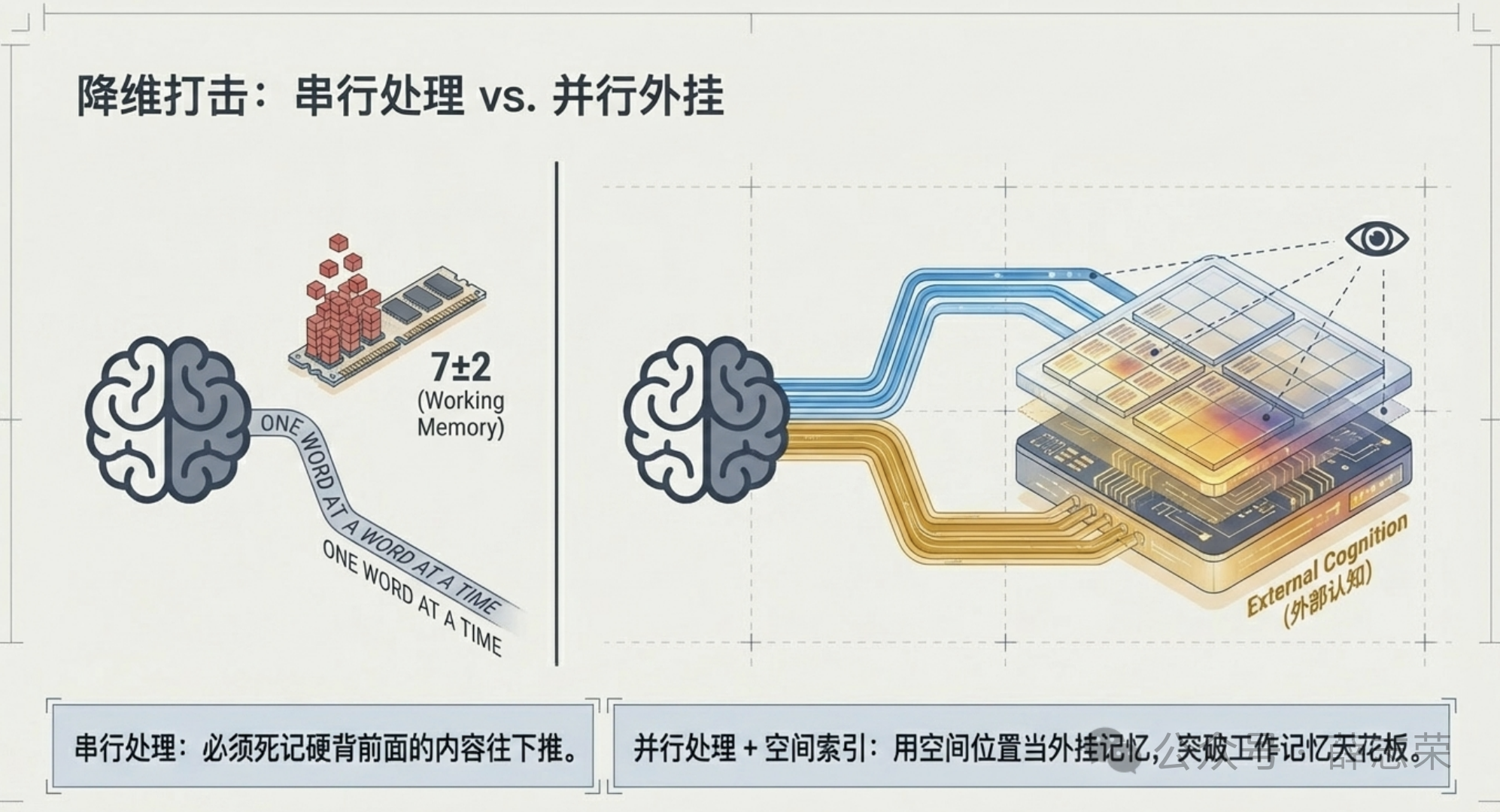 但光有”视觉”还不够。同样用眼睛看,读一段文字和看一张结构化图表,效率完全不同。
但光有”视觉”还不够。同样用眼睛看,读一段文字和看一张结构化图表,效率完全不同。
文本是串行处理。 你必须一个词一个词地读,工作记忆一路背着前面的内容往下推。读到第20行,第3行讲了什么你已经记不清了,得往回翻。
结构化视觉是并行处理 + 空间索引。 你的眼睛可以同时扫描多个区域,大脑用空间位置当”外挂记忆”——左上角是什么、右下角是什么,不需要记,看一眼就回来了。
认知科学里有个说法叫外部认知(external cognition):一张好的可视化,等于给大脑临时装了一块外置硬盘。你的工作记忆从7±2的小格子,扩展成了一整张桌面。
这就是为什么一张表格比一段描述高效,为什么地图比路线文字高效,为什么甘特图比项目列表高效,为什么财务报表要做成dashboard而不是一段段话。
不是因为图”好看”,是因为图让人类第一次突破了工作记忆的天花板。
这是第二层硬约束。
第三层:模态之间不是替代关系,是分工关系
 把上面两层加起来,就能看清”UI会消失派”最致命的错误了。
把上面两层加起来,就能看清”UI会消失派”最致命的错误了。
语音、文本、CLI、GUI——这些从来不是互相替代的关系,它们在不同任务上各有物理最优解:
- 表达模糊意图 → 自然语言最优。因为意图本身就是模糊的,你不想被结构化的表单逼着填每一栏。
- 执行精确指令 → CLI/代码最优。因为指令需要无歧义,点按钮反而会引入二义性。
- 接收大量信息做判断 → 结构化视觉最优。因为人脑只有这一条高带宽通道。
喊”UI会消失”的人,错就错在——他们把”表达意图”这一个场景的最优解,推广到了所有场景。
这是犯了模态越位的错误:用低带宽通道去承担高带宽通道才能胜任的任务。就好比有人发现语音输入法很好用,于是宣布”显示器要消失了,以后大家闭着眼睛用电脑”——你不会觉得这个判断有问题吗?
自然语言在输入端是王,但在输出端,它永远打不过结构化视觉。因为这不是技术问题,是人类大脑的出厂设置。
所以agent越强,可视化反而越不可替代
把第一性原理搞清楚之后,再回头看agent时代,你会发现一个反直觉的结论:
agent越强,人对结构化可视化的需求越高,而不是越低。
为什么?因为agent能产出的信息量,是人类手工产出的几十倍。一次任务涉及几十个决策点、上百条数据、多个执行路径。这些东西如果以纯文本、聊天气泡的形式吐给你,你的工作记忆会当场崩溃——串行处理根本来不及。
人类的决策瓶颈从来不在算力,而在注意力带宽。agent越能干,人就越需要一个高带宽界面来快速判断它干得对不对。
这就是为什么Claude Code要做diff视图,Cursor要做change preview,v0要做实时预览窗。这些不是锦上添花,是agent时代的刚需——它们在做的事情只有一件:把agent产出的信息,从一维文本转译成结构化视觉,让人类的高带宽通道能够接得住。
真正在发生的事:UI从”产品”变成了”产物”
2025年底最值得关注的技术信号是:Google开源了A2UI协议,Vercel推出了streamUI,CopilotKit在做generative UI框架。这些东西指向同一个范式转移:
UI不再由开发者预先写死,而是agent在运行时根据当前任务即时生成。
过去做一个SaaS,团队要花几百万做UI设计,因为它要服务千万用户的所有可能场景——每个按钮、每个表单、每个dashboard,都得预先想清楚、画出来、开发好、维护好。
未来不是这样。未来的agent看到你当下的context,几秒钟,当场铸造一个只服务”你+现在+这个任务”的一次性界面,用完即焚。
你问它”帮我看看这季度的销售数据”,它不返回一段文字,也不打开一个固定dashboard,而是根据你的问题临时决定图表类型、维度选择、高亮重点,当场生成一个只为这一次对话存在的可视化。
放到HCI的历史坐标上看,这是第三段:
- CLI时代:人适应机器(你必须记住命令)
- GUI时代:机器呈现固定的世界给人(所有人看到同一个界面)
- Agent时代:机器为每一次具体任务,临时铸造一个专属界面
GUI从”产品”变成了”产物”。从”几百万用户共用一套”,变成”一个人一次任务用一次”。
这不是UI的消失,这是UI的解放。而它之所以必然会发生,正是因为第一性原理里的那三层约束——人类需要高带宽、结构化、针对当前任务的信息接收界面,而agent第一次让这件事在经济上变得可行。
一条被忽略的定律:界面复杂度守恒
再给你一个更锋利的框架。
 任务的信息复杂度是守恒的,它只是在”人侧”和”机器侧”之间重新分配。
任务的信息复杂度是守恒的,它只是在”人侧”和”机器侧”之间重新分配。
- CLI时代:复杂度全压在人这边。你要记命令、写脚本、懂语法,机器什么都不替你想。
- GUI时代:开发者把一部分复杂度预先吸收进界面里。用户只需要”识别”,不需要”回忆”。
- Agent时代:复杂度被agent吸收了大半——但决策点的可视化反而需要加强。
因为人在回路里的位置变了。
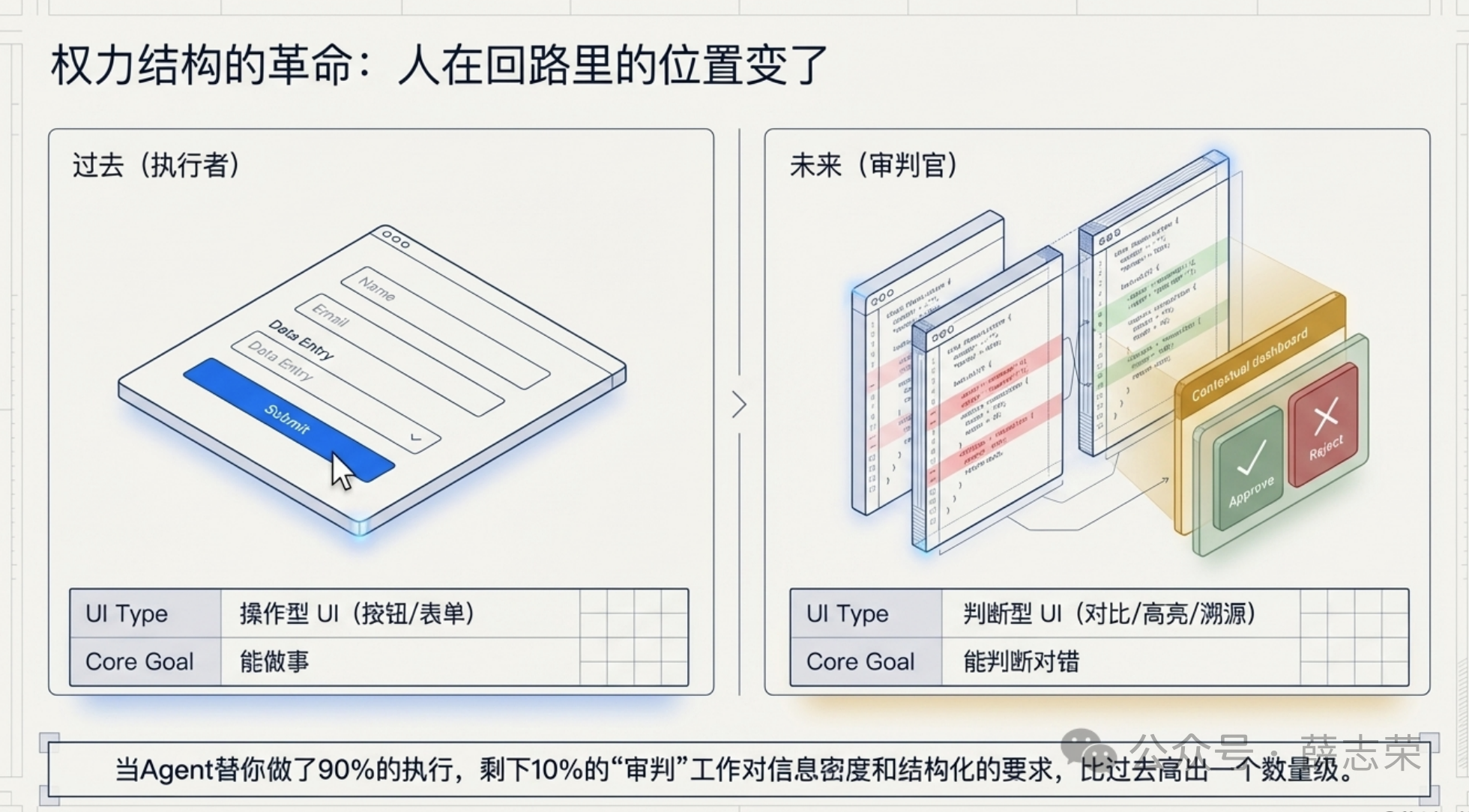
做执行者的时候,人需要的是操作型UI:按钮、表单、输入框,能让我”做事”就行。
做审判官的时候,人需要的是判断型UI:对比图、差异高亮、风险标注、来源可追溯,能让我”判断对不对”。
后者对信息密度和结构化的要求,比前者高一个数量级。 这不是设计风格问题,是回到第一性原理——审判需要在短时间内并行比较大量信息,只有高带宽的结构化视觉才承担得起。
当agent替你做了90%的事,剩下那10%——”要不要批准”、”这个对不对”、”我是不是漏了什么”——就成了人唯一的、也是最关键的工作。而这个工作,纯文本根本承载不了。
这场范式转移的真正含义:人的位置变了
我想讲清楚这件事的重量。
过去40年的HCI革命,从CLI到GUI,核心改变的是 “谁能用电脑” ——从程序员扩展到普通人。这是准入门槛的革命。
而agent + generative UI的这场革命,核心改变的是”人在决策回路里的位置”——从执行者变成审判官。这是权力结构的革命。
前者让更多人进来,后者让进来的人去做更重要的事。
从这个角度看,那句”UI会消失”的判断,它不是在预测未来,它是在错过未来。它把人机交互的下半场——那个最有意思、最有商业价值、最考验设计功力的下半场——当成了终点站。
真正的终局叙事应该是这样两句话:
自然语言是人输入意图的终局。
动态生成的结构化可视化,是机器回馈信息的终局。
这两句话是一个整体。只讲前半句的人,只看懂了交互的一半。而之所以是这两句话而不是别的,根本原因只有一个——人类的大脑,输入端靠的是模糊意图生成器(语言),输出端靠的是高带宽并行处理器(视觉)。这是几百万年演化下来的硬件配置,AI再强也改不了。
写在最后
做HCI这么多年,我见过太多”某某会消失”的判断。鼠标会消失、键盘会消失、App会消失、网页会消失——每一次都有人言之凿凿。
每一次都没消失。
因为人类的感官结构、认知带宽、决策方式,这些东西不会因为AI的出现而改变。改变的是机器如何配合人,而不是人被迫去配合机器。
这恰恰是人机交互这门学科存在的意义——它始终研究的是人,而不是机器。
原文:
https://mp.weixin.qq.com/s/wGgipQio8DeU2b_ksYBKiA
既然来了,说些什么?