AI 正在淘汰的 10 种 UI 交互模式
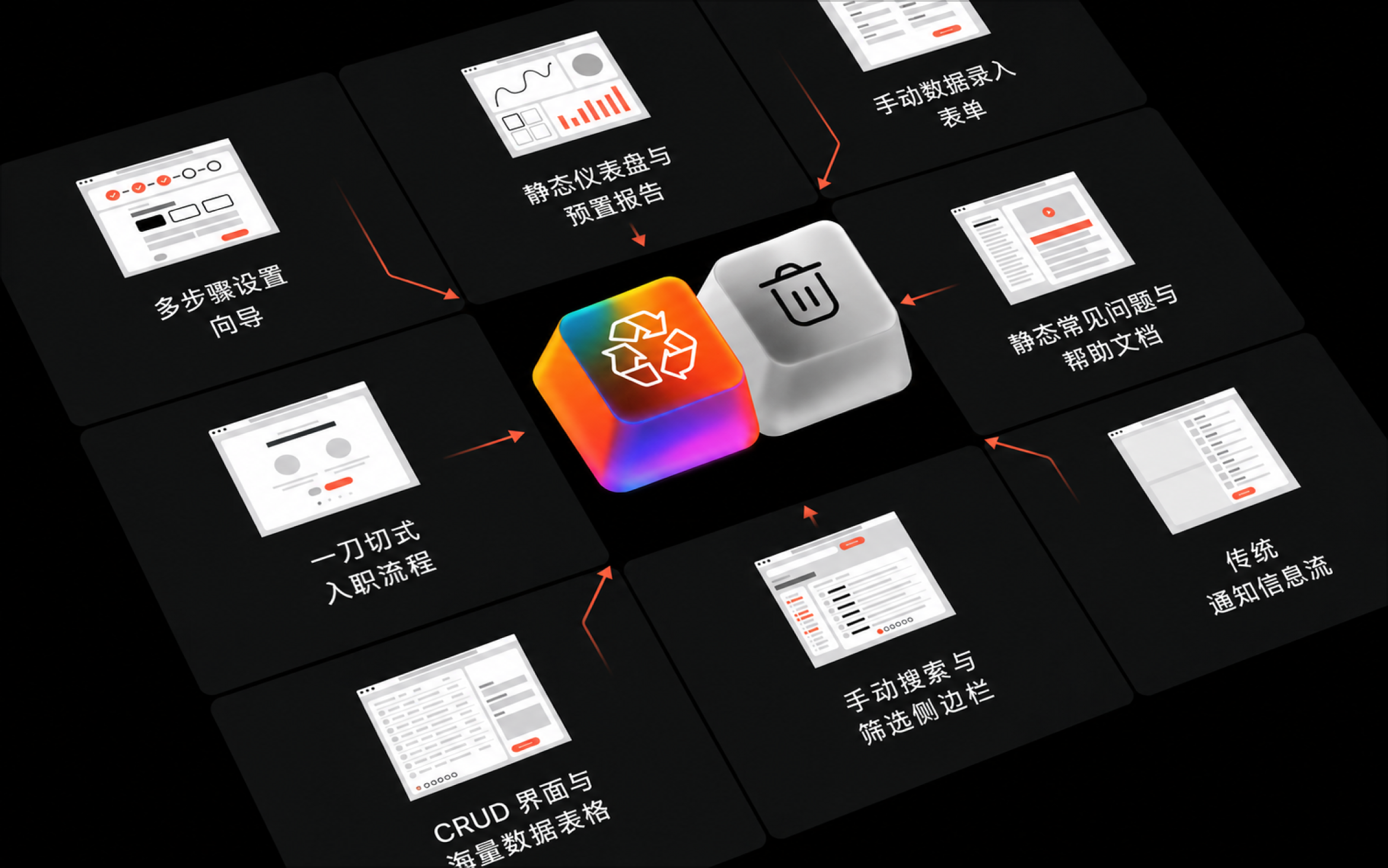
当前,产品与设计团队面临的一个更大挑战,是一种几乎没人追踪的“UX 债务”——那些依然能够运行,却已经逐渐失去存在合理性的交互模式。
过去很多年里,我们不断打磨各种界面形态:仪表盘、数据录入表单、搜索流程、筛选侧边栏、配置向导、通知流、FAQ 页面、用户引导流程……
而这些设计,本质上都建立在同一个前提之上:真正执行操作的人类用户。
几乎每一个界面的存在,都源于设计师反复回答同一个问题:“用户在这里需要完成什么操作?”
而现在,AI 正在直接替代这些界面存在的根本理由。
并不是因为这些 UI 模式已经失效,而是因为它们共享着同一个默认假设——真正执行工作的,是人。
于是问题开始出现:
哪些交互模式应该被淘汰?哪些需要被重新设计?又有哪些,将被赋予一种全新的角色与存在方式?

传统界面模式正在被重新审视——其底层逻辑始终建立在人类亲自操作之上
- 配置向导(Setup Wizards)→ 从“层层询问”转向“智能推断”
- 筛选侧边栏(Filter Sidebars)→ 从“手动条件配置”转向“自然语言表达”
- 搜索结果页(Search Results)→ 从“链接排序”转向“结果生成与综合回答”
- 数据录入表单(Data Entry Forms)→ 从“人工转录填写”转向“结果确认”
- 仪表盘(Dashboards)→ 从“指标网格展示”转向“异常与关键信号感知”
- CRUD 数据表格(CRUD Tables)→ 从“逐行编辑”转向“批量意图操作 + 差异审阅”
- FAQ 页面(FAQ Pages)→ 从“文章式检索浏览”转向“上下文驱动的 AI 问题解决”
- 新手引导(Onboarding Tours)→ 从“预设式流程讲解”转向“即时嵌入式说明”
- 通知流(Notification Feeds)→ 从“按时间排序的信息流”转向“优先级驱动的智能简报”
- “新建”按钮(“Create New” Buttons)→ 从“空白画布”转向“AI 生成初始草稿”
八种正在重塑传统 UI 的核心力量
执行自动化(Automation of Execution)
AI 已经能够在明确约束条件下,端到端地完成多步骤工作流。任何仍然依赖用户“按流程一步步操作”的界面,都正在失去存在合理性。
环境化上下文理解(Ambient Context Understanding)
如今的系统已经能够主动读取用户的文件、工具、历史记录与行为上下文,而不再需要用户显式提供。任何本质上只是为了“收集系统本应已经知道的信息”而存在的界面,都正在承受压力。
基于自然语言的意图解析(Intent Resolution from Natural Language)
系统已经能够理解非结构化的人类表达,并将其映射为精确操作。任何迫使用户将自身目标“翻译”为系统语言的界面——例如筛选器、下拉菜单、布尔查询——都正在被重新定义。

多模态上下文注入(Multi-Modal Context Injection)
如今的机器已经能够同时理解图像、语音、文档以及屏幕内容,并将其与文本一起作为输入进行处理。
任何仍然只允许用户通过“文本输入 + 结构化字段”完成交互的界面,都正在承受压力。
AI 生成式初稿(Generative First Drafts)
AI 已能够基于简短描述,生成几乎任何内容形态的可用初稿。任何让用户从“空白状态”开始创建内容的界面,都正在失去原有意义。
按需上下文解释(Contextual Explanation on Demand)
系统已经能够识别用户当前的困惑点,并在真正需要的时刻即时提供解释。任何在固定流程节点中,预先灌输通用教学内容的界面,都正在被重新审视。
交互与信息成本压缩(Compression of Interaction & Information Cost)
智能 Agent 已能够将多步骤流程压缩为单次操作,并把高密度信息提炼为简洁摘要。任何把简单目标拆解成繁琐多步骤操作的界面,都正在面临挑战。
智能分诊与优先级判断(Intelligent Triage & Prioritization)
智能 Agent 已能够结合紧急程度、相关性与上下文,对信息进行自动筛选与优先级排序。任何默认“展示全部内容”,再要求用户自行筛选的界面,都正在承受巨大压力。
🗑️ 多步骤设置向导 → 意图推断 + 确认机制
为什么这一模式正在失效。设置向导(Setup Wizard)最初的设计目标,是通过将复杂配置拆解为线性步骤,来引导用户完成系统设置。其核心前提是:用户必须理解产品内部的专业术语,并按照系统预设的顺序逐步完成操作。
但这一前提正在被AI能力彻底削弱。
当AI可以通过单一动作(例如:连接一个代码仓库、创建第一份文档、加入一次日历事件)推断上下文时,这种“逐步询问式”的交互方式反而变成了纯粹的阻力。用户的第一条自然语言输入,往往已经比十个包含下拉框与开关的界面状态更能准确表达其真实意图。
例如,在 HubSpot 中创建一份销售报价,需要依次经过七个连续界面:手动选择客户联系人、补充公司信息、配置产品条目、设置签名与付款方式、选择模板、调整细节,最后才能进入预览与生成阶段。整个流程的每一步,都隐含一个假设——系统并不知道这些它在 CRM 中早已存储的信息。
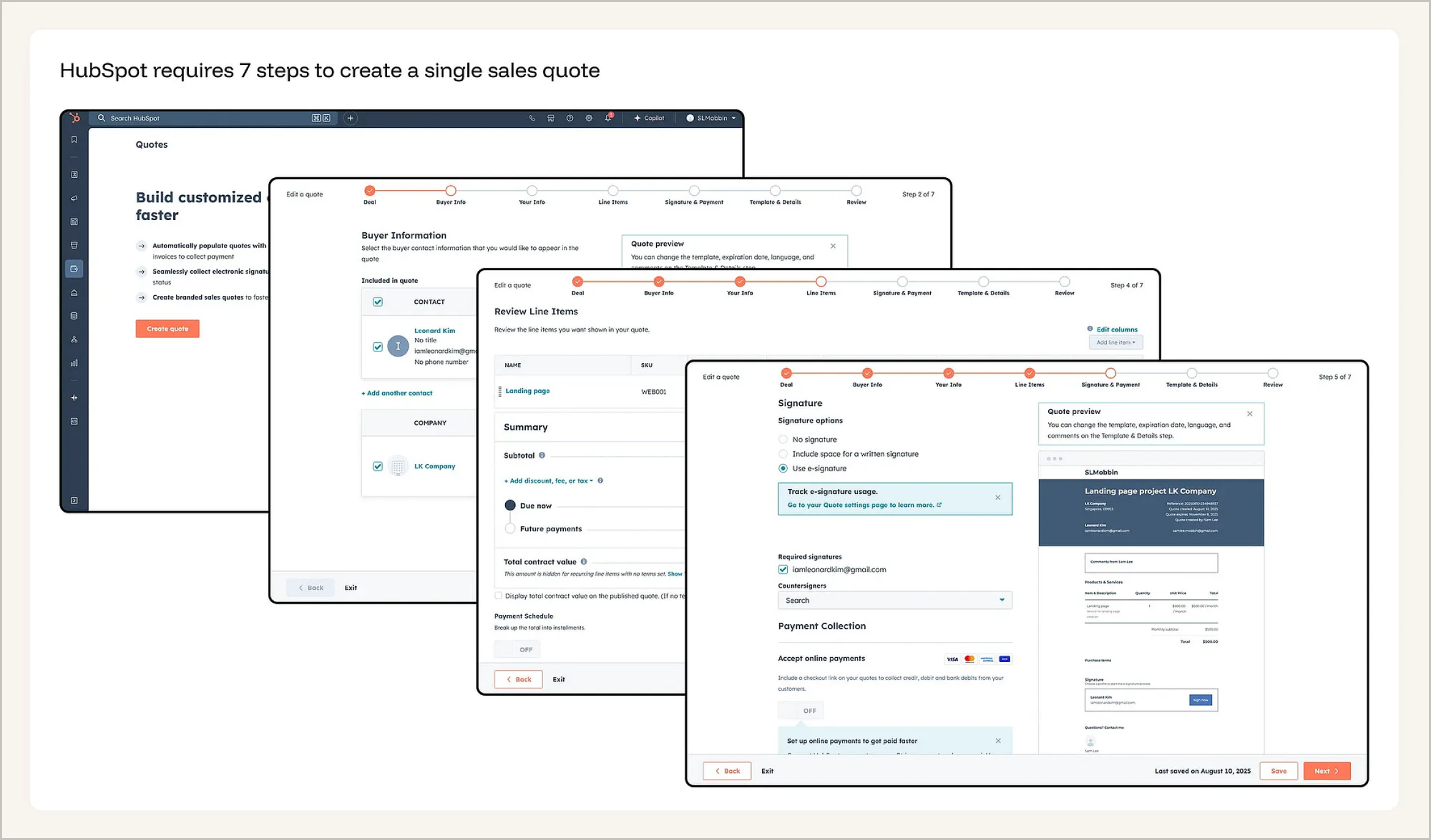
什么取代它:从“配置引导”到“AI驱动的自动组装”。AI正在用一种全新的方式重构配置流程:系统不再通过一系列问题逐步“引导用户完成设置”,而是基于用户的第一个有意义动作,直接推断出整体配置意图,并自动完成初始搭建。
在这种模式下,用户的角色发生了转变——从逐项填写表单的执行者,变为结果校验与纠偏者:用户只需要审核系统生成的配置结果,并对偏差进行修正,而不再需要回答那些系统本可以自行推断的问题。
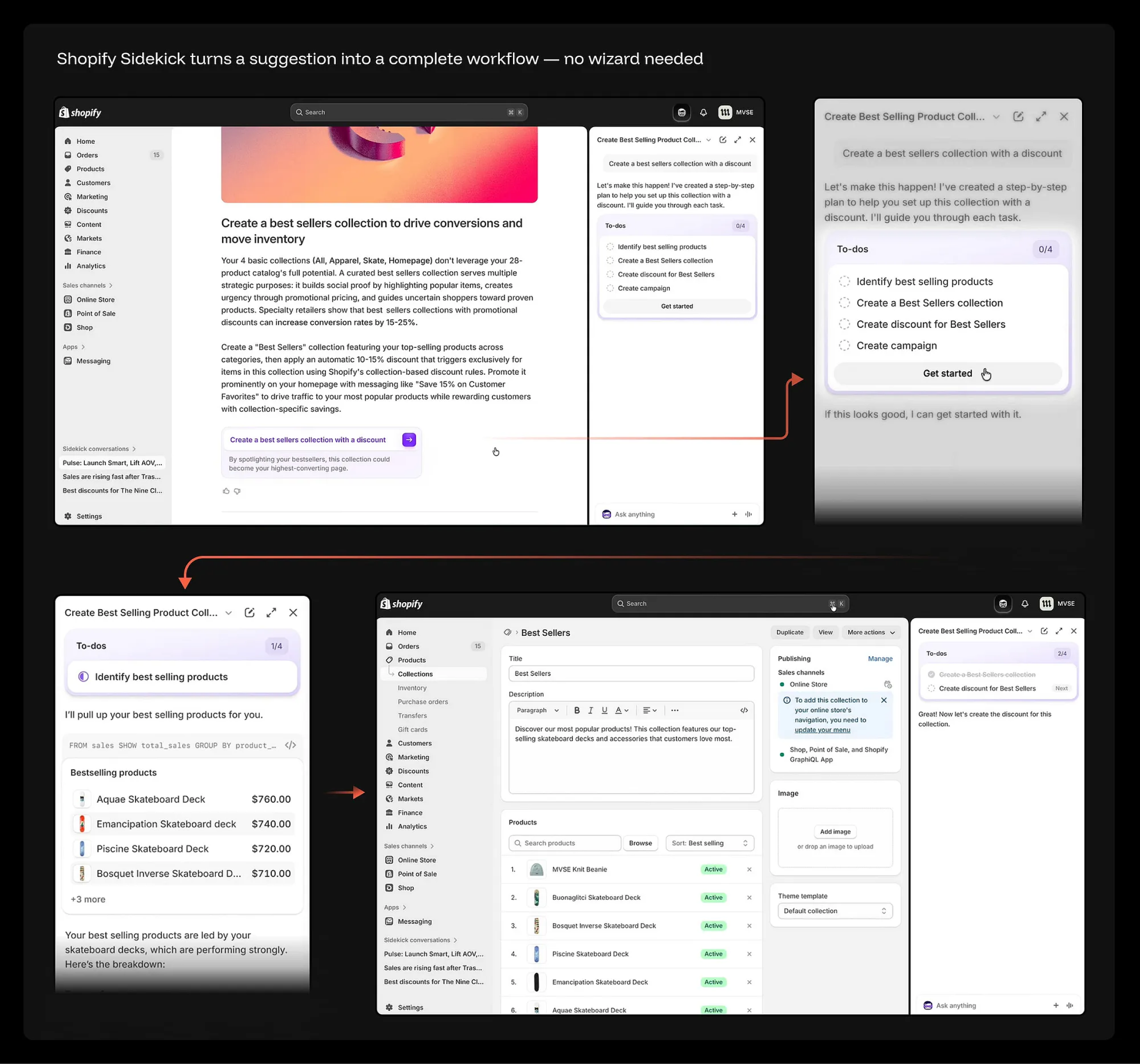
以 Shopify Sidekick 为例,其会分析店铺数据后发现,商家的畅销商品并未被有效展示,从而主动建议创建一个“Best Sellers(畅销商品)”集合,并搭配折扣策略。用户只需点击“Get started”,Sidekick 便会自动执行完整流程:调取销售数据、识别按营收排序的核心商品、创建集合、填充商品、配置折扣规则,并同步搭建营销活动。
在整个过程中,商家不再面对一连串表单字段,而是在每个关键节点对系统输出结果进行审核与确认。
♻️ 手动搜索 + 筛选侧边栏 → 语义意图解析
为什么这一模式正在失效。传统搜索范式本质上要求用户完成“双重翻译”:首先将自身意图转译为关键词表达,然后再通过复选框、范围滑块、下拉菜单等筛选控件对同一意图进行二次重述。这种“表达—再表达”的交互路径,本质上与人类自然的需求表达方式相悖。
在更自然的语义表达下,一句完整的自然语言——例如:“布鲁克林靠近优质学校的性价比两居室,但不要一楼”——本可以直接完成过去需要关键词检索 + 六次筛选交互才能达成的精确定位。在纯关键词时代,筛选侧边栏曾是一次重要的 UX 进化。但在语义搜索与向量检索逐渐成熟之后,它正在从“主路径”退化为“兼容路径”。
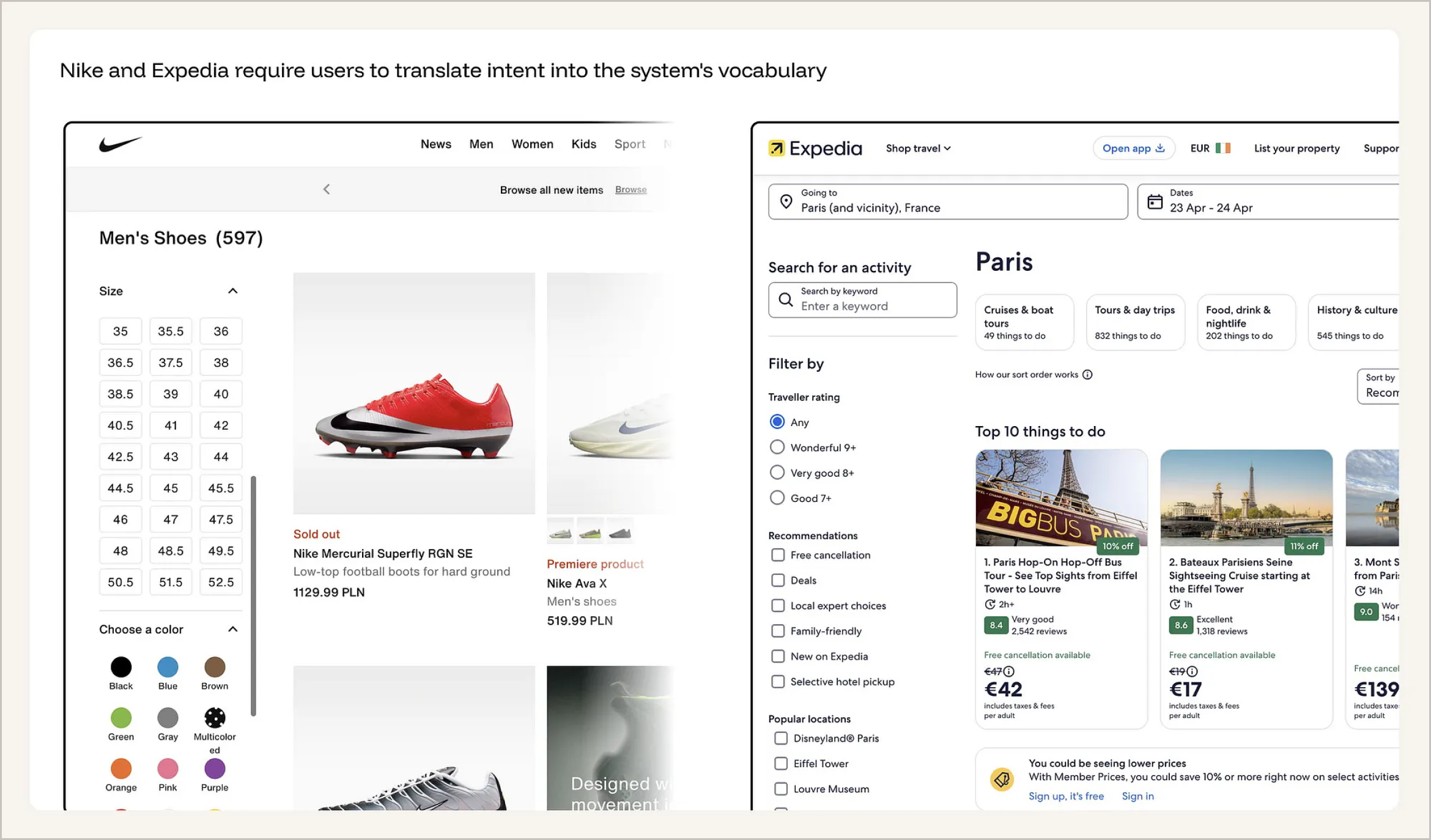
以具体产品体验为例:在 Nike 的商品检索中,用户面对的是 597 双男鞋,需要通过手动方式逐步缩小范围:界面提供 54 个尺码按钮、10 种颜色色板,以及价格、鞋楦宽度、运动类型等多层筛选面板。Expedia 在巴黎活动的检索中也采用类似结构:上方是关键词搜索框,中间是用户评分单选项,旁边是“免费取消”“优惠活动”“亲子友好”等推荐复选项,底部则按区域提供“迪士尼”“埃菲尔铁塔”“卢浮宫”等位置筛选。在这两种场景中,用户的真实需求其实非常明确——例如“黑色足球鞋,42码”或“埃菲尔铁塔附近的亲子游船体验”。但界面却迫使用户将一个完整意图拆解为一组离散筛选条件逐一表达。
取而代之的是什么?一个以自然语言输入界面(Natural-language input surface)为主导的核心搜索入口。用户可以直接表达意图,系统则会一次性解析所有限制条件。在这里,视觉筛选器(Visual filters)不再与核心意图平起平坐,而是降维成一种次级的修正机制,退居幕后。多轮对话式的渐进明细(Multi-turn refinement)取代了繁琐的重新配置,比如用户只需说:“换个便宜点的,离海滩再近点。”
“12月23日入驻纽约市酒店,住一晚,要求在洛克菲勒中心半英里以内” —— 全程纯文本输入,没有任何表单字段。在 KAYAK 的新版设计中,“AI 模式”与传统的机票、酒店、租车标签并列,但在功能上,它用一个统一的对话框替代了此前所有的独立入口。系统会直接理解用户意图,从数百家供应商中抓取实时价格,并直接返回可操作的搜索结果。底部还配有一个“继续提问……”的输入框,方便用户进行迭代微调。
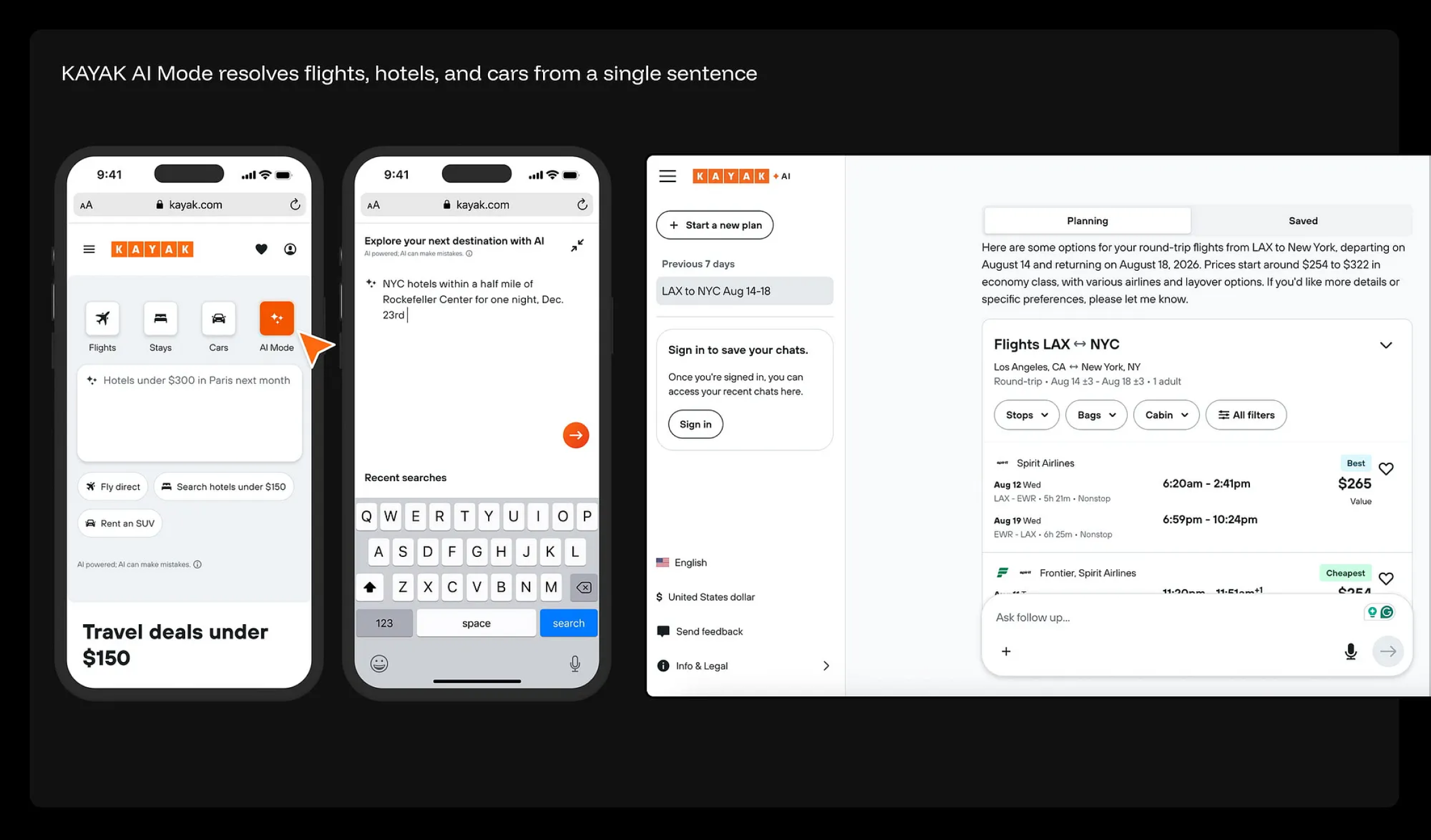
与其费尽心思去配置 15 个筛选字段,招聘人员现在只需输入一句话:“寻找拥有 3 年以上 SaaS 或 B2B 产品经验的产品设计师。需精通用户研究(UX research)、线框图绘制(wireframing)、原型设计(prototyping)及 UI 设计。”随后,Copilot 会自动对照这些维度评估 200 位候选人,并直接返回带有评分的结果:128 位完美匹配(评分 90% 以上)、50 位高匹配(80–89%)、18 位中等匹配,以及 4 位低匹配。每位候选人的档案中都会展示逐项指标的分数拆解(例如:SaaS 经验:5分;用户研究能力:5分;基于 Figma 的线框图绘制:5分),并附带详细的匹配理由。针对单个候选人,系统仅保留两个核心操作:“隐藏”或“加入候选名单(Shortlist)”。至此,传统的侧边栏筛选器彻底退场,取而代之的是一个简单的意图描述框,以及一套置信度可度量、过程可解释(explainable)的搜索结果集。
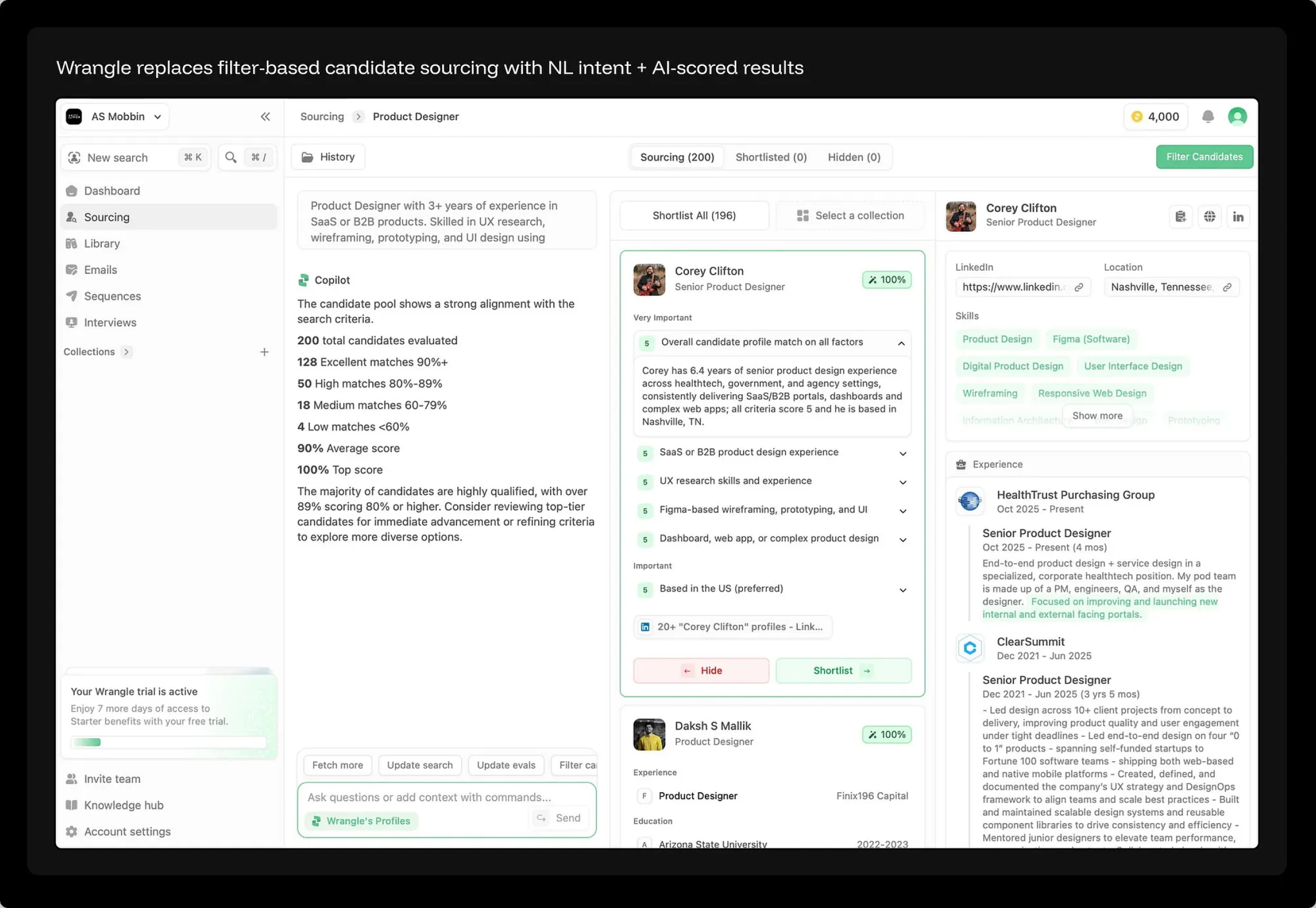
这里需要补充一个必要的客观事实:筛选器(Filters)并未走向消亡,它们只是在被重新定义。在许多业务场景中,筛选器承载着“探索与发现(Discovery)”的功能,而这是自然语言无法完全取代的:比如一个正在逛耐克(Nike)官网的用户,他自己可能并不清楚具体想要什么。他只是想看看自己的鞋码还有哪些款式、浏览一下有哪些配色、对比一下价格区间。此时,筛选器的作用是将整个“选项空间(Option space)”可视化,使其变得可感知、可浏览。这与直接表达明确的既定意图(Known intent),完全是两码事。
因此,这场变革的核心并不是“消灭筛选器”,而是其生态位(Positioning)的转移——筛选器正从过去核心的“信息发现机制”,降维演变成为一种次级的“渐进微调层(Refinement layer)”。
🗑️ 手动数据录入表单 → AI 智能提取 + 置信度提示机制
为什么传统模式正在失效?让用户把已经存在于其他地方(如邮件、文档、收据、日历、扫描件等)的结构化或半结构化信息,再次手动敲进表单里——这在本质上是一种体验债(UX debt)。而现在的文档 AI(Document AI)完全可以在数据提取层直接把债还清。过去的表单设计,一味在优化输入侧的摩擦力(如调整字段顺序、Tab 键跳转流、表单校验等),却从未反思过一个根本问题:为什么非要让用户手动去打字?
表单字段依然存在,但其角色已经发生了质的转变:它不再是核心的数据录入入口,而是演变成了对 AI 提取结果的“确认面板”。 相应地,设计重心也从“输入优化”转向了“置信度提示(Confidence signaling)”——即如何向用户精准传达 AI 对其抓取内容是“胸有成竹”还是“模棱两可”。
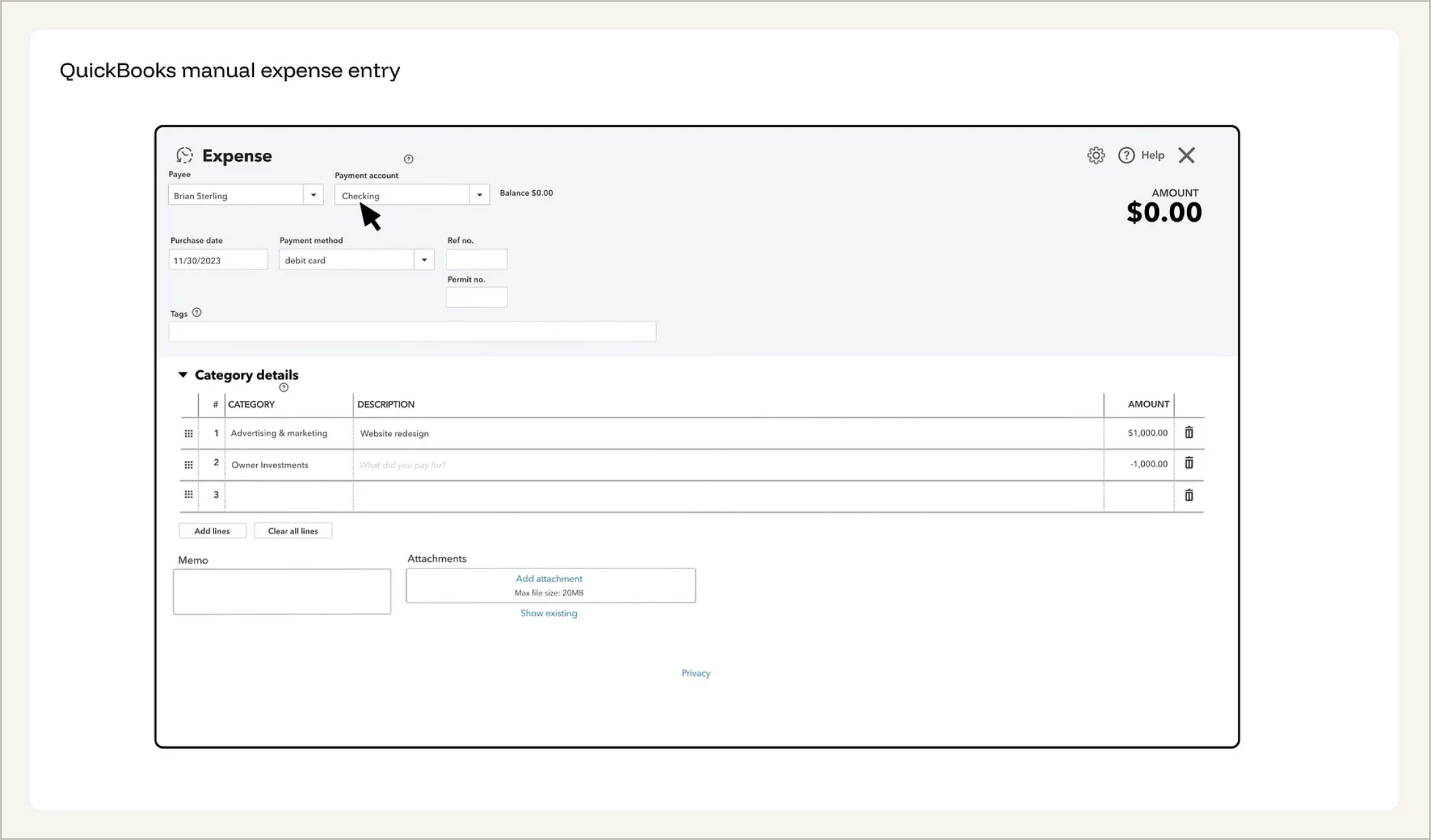
典型反面教材:QuickBooks 传统的手动报销录入
在过去,每一个字段都需要人工手动填写。收款人、支付账户、购买日期、支付方式、凭证号、标签、分类、描述、金额……每一个输入框都需要用户手动敲击键盘或拉取下拉菜单。收据虽然作为附件上传了,但系统根本“读不懂”它。收据上的字和表单里的字,本质上是同一套信息被被迫录入了两次。
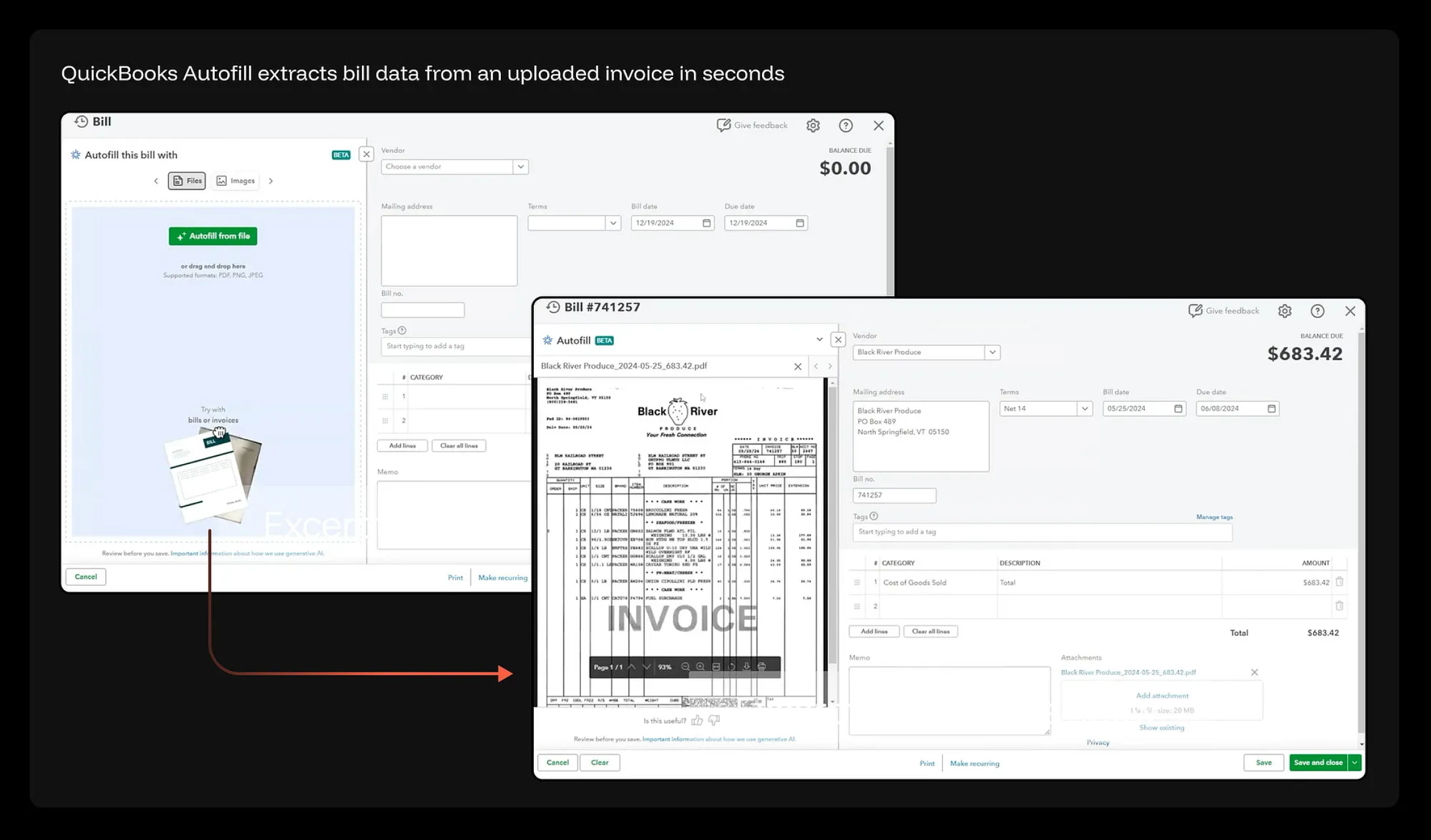
取而代之的是什么?AI 直接从源文档、邮件或图片中提取数据,并自动预填好所有能识别的字段。此时,表单直接演变成了一个“差异对比视图(Diff view)”,其潜台词是:“这是我的提取结果——请您确认或修正。” 系统会将那些高置信度(High confidence)自动填充的字段赋予一种独特的视觉状态;而对于低于置信度阈值的字段,则会做出高亮标记,提示需要人工介入审查。用户的操作逻辑变成了“审核与修正”,而不是“肉眼誊抄”。
典型正面案例:QuickBooks Autofill(自动填充)功能用户上传一张发票,系统在几秒钟内就能完成账单数据的提取。只需把 PDF 或照片拖拽到 Autofill 面板中,AI 就会开始“通读”文档——自动识别并抓取供应商、地址、账单编号、日期、账期、商品明细以及总金额。虽然表单还是那个表单,但用户的角色已经从“打字员”反转成了“审核员”。系统笃定的字段早已被预先填妥,用户需要做的只是“纠错”,而不是去“补漏”。
🗑️ 静态数据看板与预制报表 → 异常指标面(Exception Surfaces)+ 对话式下钻探查
为什么传统模式正在失效?无论是定期发送的周月报,还是固定的静态数据看板,它们回答的其实都是产品上线前,开发者在几个月前就预设好的老问题。这种塞满了各种 KPI 的表格网格,试图展示“所有我们认为重要的东西”,它优化的是信息覆盖率(全面性),而不是当下最核心的“业务相关性”。用户不得不肉眼扫视 20 多个指标,去大海捞针般地寻找哪一个发生了异动——更糟糕的是,很多异动在眼花缭乱的看板中被直接漏掉了。
AI 智能数据分析(AI analytics)的出现,让任何即时问题都能被实时提问并解答。数据看板的角色随之发生跃迁:它不再负责“展示一切”,而是负责“聚焦并抛出那些值得调查的异常指标”。 指板的“指标密度(Metric density)”开始让位于深度解释、洞察摘要以及推荐的下一步动作。
典型反面教材:Cloudflare 与 Google Analytics 的静态平铺。Cloudflare 将请求数、错误率、CPU 占用率和响应耗时(Wall time)等核心指标,全部平铺展示为一个个静态的数字卡片。Google Analytics(GA) 则直接甩出一个包含“实时、留存、受众、流量、用户互动”等庞大报表分类的侧边栏树状菜单,让用户自己去一层层翻找有价值的数据。这两类数据看板都犯了同一个错误:给予所有数据完全等同的视觉权重(Visual weight)。 没有任何机制能主动告诉用户究竟“什么变了”、“什么才是最重要的”,或者“下一步该干什么”。在这里,用户被迫成了那个肉眼识别异常的“人体探测器”。
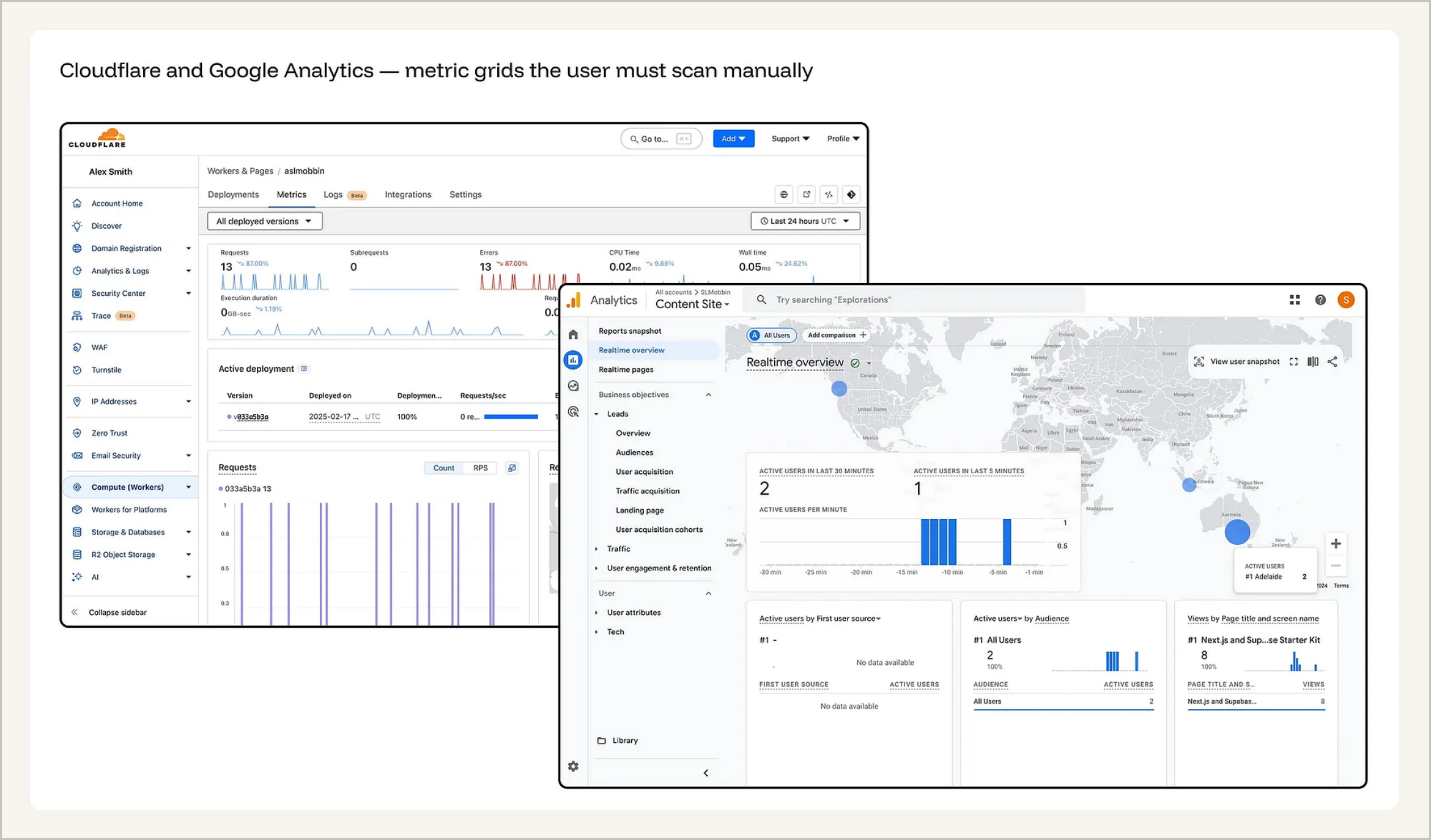
取而代之的是什么?一个以“异常指标优先(Anomaly-first)”为核心的观测层。它保持后台持续监控,且只高亮那些发生异动的数据,并给出背后归因。此时,整个数据看板只需回答一个核心问题:“为什么系统要把这个推给我?” 至于更深度的业务下钻与溯源,则交由即时响应的自然语言查询界面(NLQ)来处理。相应地,设计师的功课也发生了转移——核心的设计对象变成了阈值与告警机制的设计,而不是去琢磨图表怎么排版。
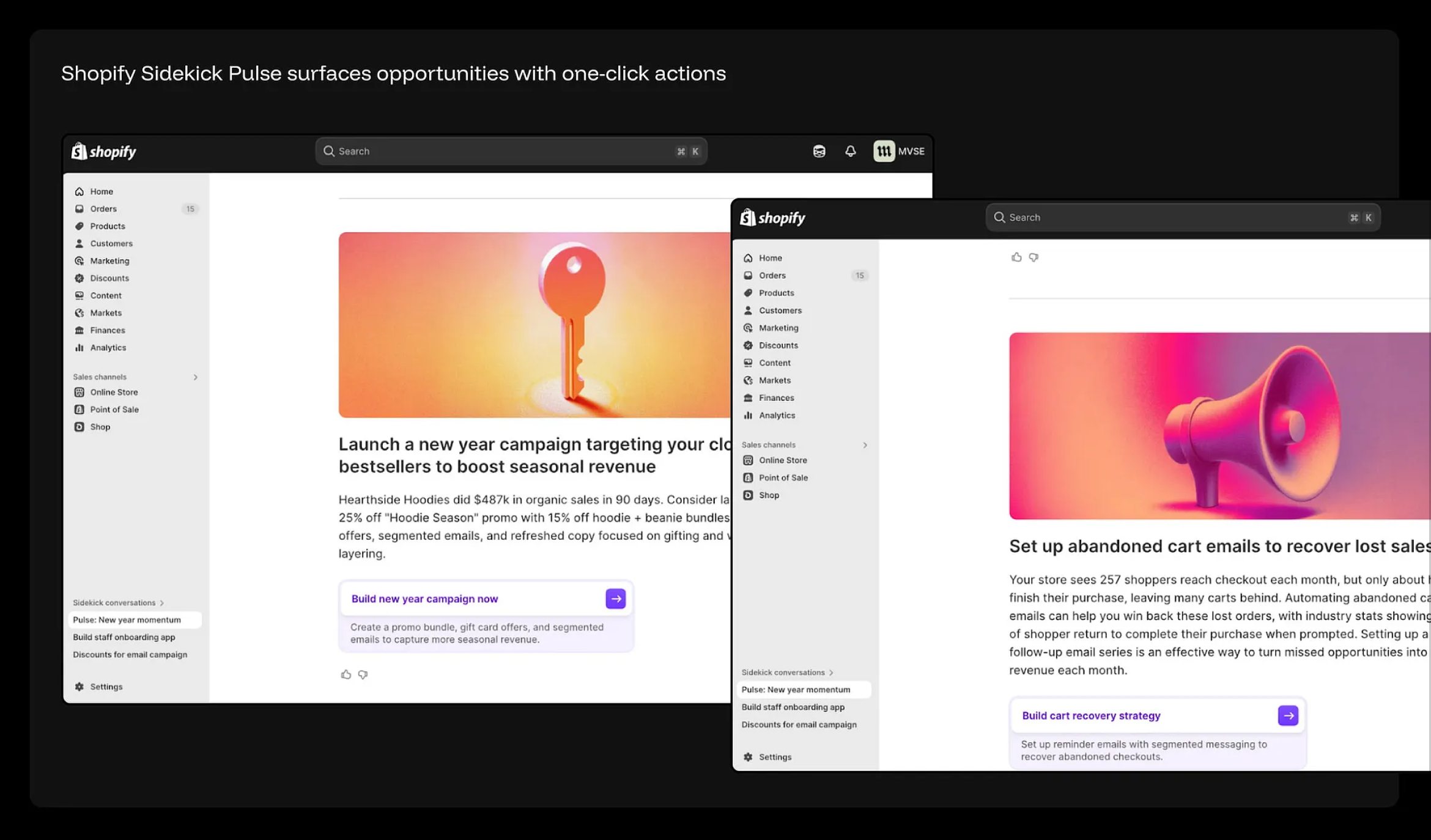
典型正面案例:Shopify Sidekick Pulse 的“一键降维打击”。Shopify Sidekick Pulse 直接将业务增长点以“一键可执行动作”的形式抛给商家。它彻底抛弃了密密麻麻的指标网格,让 Sidekick 在后台默默分析店铺数据,并主动输出精准的业务洞察:“Hearthside 连帽衫在 90 天内实现了 48.7 万美元的自然销售额——建议立即启动‘连帽衫季’专属促销。”“每月有 257 名顾客进入了结账流程却未完成付款——建议配置挽留购物车流失用户的催付邮件。”尤为惊艳的是,每一条业务洞察都直接配有一个具体的行动按钮(如“立即创建新年大促”或“构建购物车挽留策略”)。在这里,商家的日常运营变成了“对系统建议做决策”,而不是“对着图表瞎猜”。
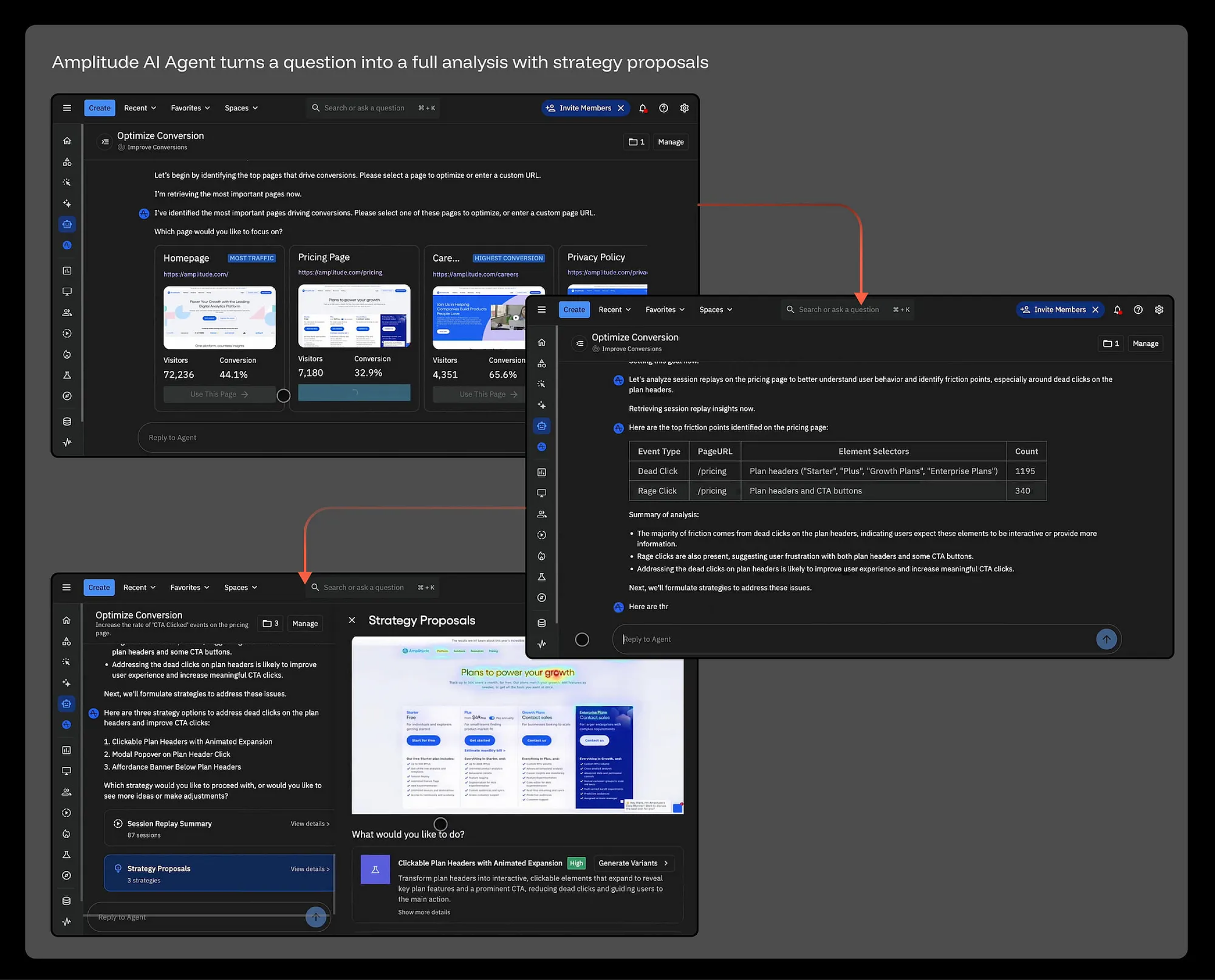
Amplitude AI Agent 能直接将用户的一个提问,转化为一套包含底层策略建议的深度数据分析报告。比如,当一位产品经理(PM)输入“优化转化率”时,AI Agent 会迅速识别出流量和转化率排名前几的核心页面,并追问 PM 接下来希望聚焦于哪一个。在 PM 选择了“定价页(Pricing page)”之后,AI Agent 会进一步调取用户行为录屏(Session replay)数据,精准锁定制约转化的核心摩擦点(Friction points)——例如:“产品方案表头遭遇了 1,195 次无效点击(Dead clicks)”、“行动点按钮(CTA button)遭遇了 340 次愤怒点击(Rage clicks)”。随后,它不仅能归纳出问题的底层根因,还能针对性地给出三套具象的优化策略:表头组件可点击化、弹窗浮层(Modal Popover)以及强化视觉线索(Affordance Banner)。更绝的是,每套策略下方都直接配有一个“一键生成变体(Generate Variants)”的操作按钮。过去需要数据分析师吭哧瘪肚干上一整天的深度下钻调研,现在,在一个对话流(Conversation thread)里就全部搞定了。
♻️ 传统的 CRUD 数据表格 → 批量意图输入 + 差异化检查视图(Diff Review)
为什么传统模式正在失效?CRUD(增删改查)表格的设计,本质上是基于一个古老的前提:单人、单条记录、单字段串行操作。当你只是想改一个联系人信息,或者更新单张工单时,这种模式挑不出毛病。但只要你的核心意图一旦跨越了多条记录,这套模型就会瞬间瘫痪。
这里的痛点在于,用户的思维模型与界面的交互逻辑之间,存在着巨大的断层(The gap)。商品运营人员想的是:“把第三季度除了入门款以外的所有商品价格,全部上调 12%。”运营主管想的是:“把 Anna 手头所有未结案的工单全部指派给 James,并且把其中已经逾期的工单做加急处理。”产品经理想的是:“把所有来自企业级大客户(Enterprise)的需求,全部标记为高优先级。”在用户的脑海中,这些都只是一个单一的决策。然而,落到传统的 CRUD 表格里,用户却不得不把这个单一决策拆解为几十次、甚至上百次枯燥的独立编辑操作。
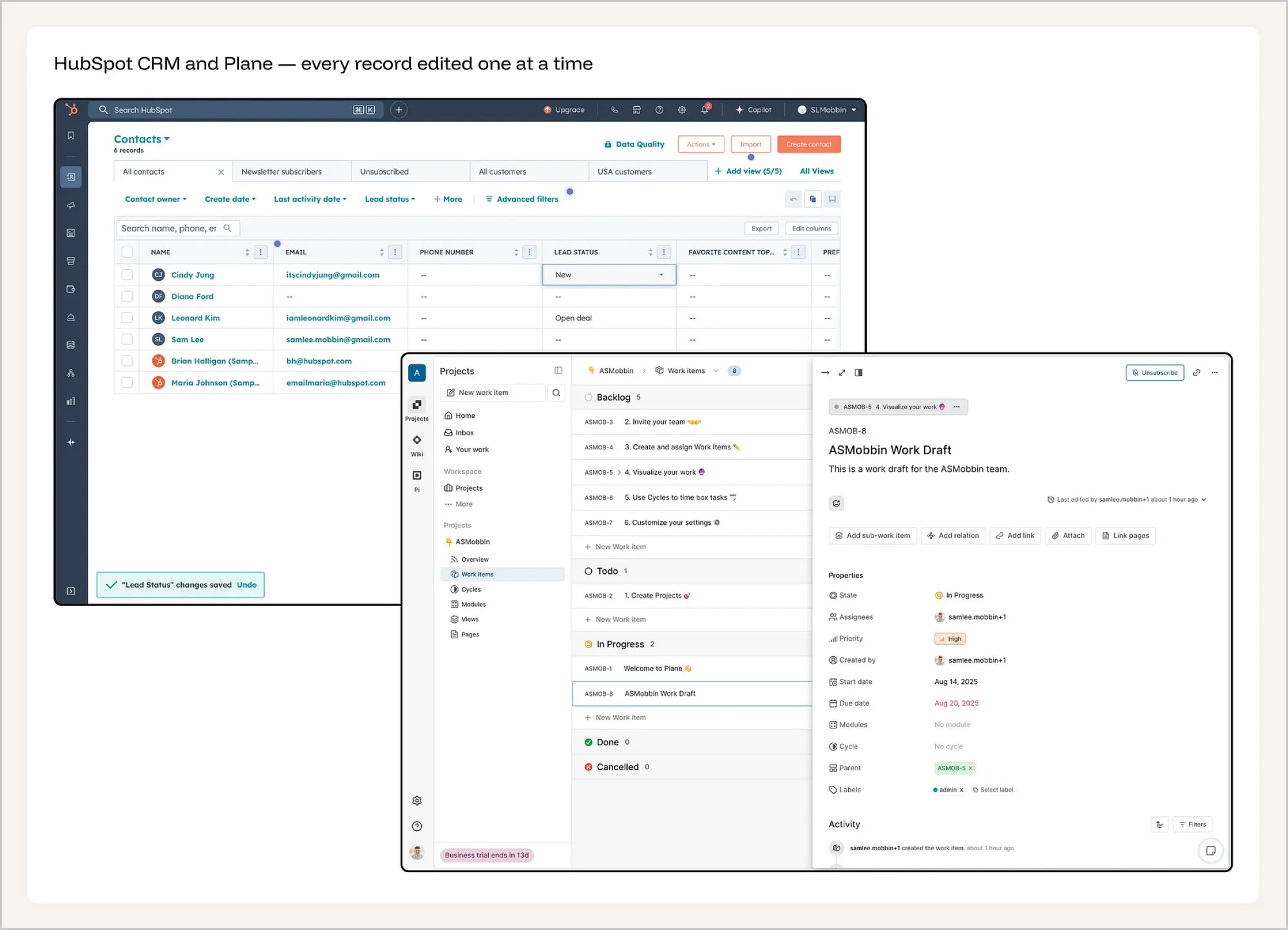
典型反面教材:HubSpot 与 Plane 的机械化重复。HubSpot 的联系人表格:修改 6 条记录,需要逐个点击单元格、拉下下拉菜单、选择数值、点击保存。仅仅是修改这 6 个联系人的“线索状态(Lead Status)”,就需要整整 6 次重复的交互,系统甚至还会为此弹出 6 个独立的绿色 Toast 吐司提示框。Plane 的项目管理工具:同样深陷这种泥潭。每一个工作项(Issue)都会打开一个包含 12 个属性字段(状态、负责人、优先级、开始/截止日期、标签等)的详情面板,且全部需要逐一修改。如果团队组织架构调整,需要重新交接 20 个任务怎么办?对不起,请点击打开、修改负责人、关闭,然后重复这套动作 20 次。在这种界面设计下,系统把每一条记录都割裂成了一个个孤立的编辑会话(Editing session)。
取而代之的是什么?一种在大规模数据上直接生效的“自然语言意图(Natural language intent)”,并辅以一个差异化检查视图(Diff review surface)。在任何改动最终提交(Commit)并生效之前,该视图会精准呈现所有即将发生的变化。用户只需描述一次策略——例如:“把第三季度除了入门款以外的所有商品价格,全部上调 12%”,或者“把 Anna 手头所有未结案的工单全部指派给 James,并将优先级调整为高”——系统便会自动生成完整的变更集(Change set)。随后,用户只需审查一份极简的变更摘要:“共涉及 184 条记录,更新了 2 个字段,以下是变更前后的对比。” 在这里,用户拥有绝对的控制权:可以一键全部接受、按分组批量接受、驳回个别高风险项,或者直接修改 prompt 指令让系统重新生成。
至此,用户的角色发生了底层逻辑的质变:从原先的“行级操作员(Row-level operator)”,跃升为了“意图创作者(Intent author)”与“变更审查员(Change reviewer)”。传统的表格不再是核心的编辑入口,而是退化为一个用来核对与校验的纯读状态面板(Read surface)。整个交互模型彻底迎来了倒置:在过去,用户是“一边埋头苦干,一边祈祷别出错”;而现在,用户是“先动嘴描述工作,在数据落地前气定神闲地确认一切无误”。
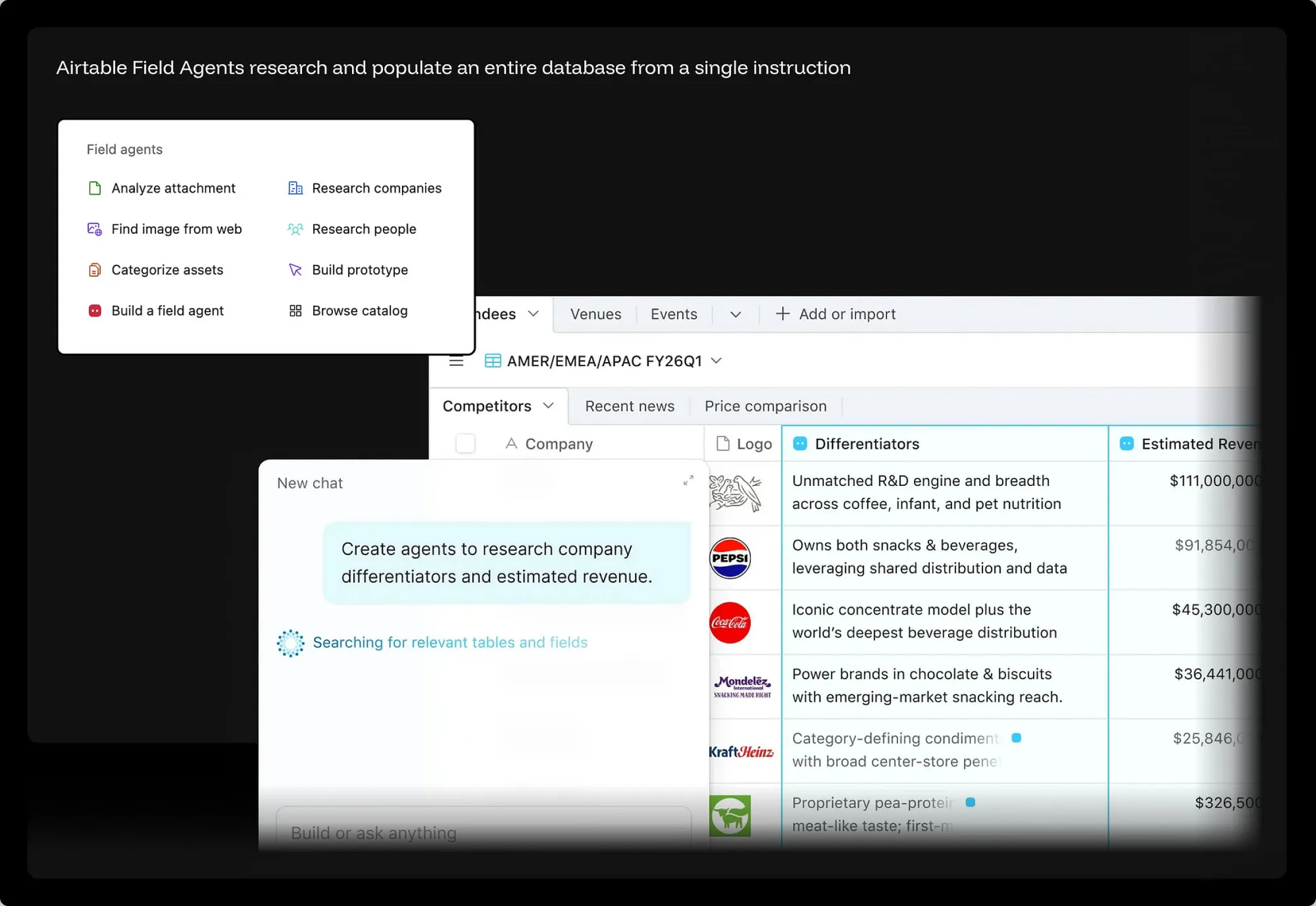
当用户输入“创建智能体来调研各家公司的核心壁垒(Differentiators)与预估营收”时,Airtable 的 AI 便会立刻启动:它会自动扫描整个“竞争对手”表格,去全网定向检索每家公司,并在所有行中完全自主地填充两个全新的列——“核心壁垒”与“预估营收”。雀巢(Nestlé)、百事(PepsiCo)、可口可乐(Coca-Cola)、亿滋(Mondelēz)、卡夫亨氏(Kraft Heinz)……每一家巨头都在不经过任何人工单元格编辑的情况下,拿到了为其量身定制的洞察摘要和营收数字。在这里,“字段级智能体(Field Agents)”的能力早已超越了简单的表单自动填充: 它们能深度解析附件、在全球互联网中精准搜寻配图、为资产进行智能标签分类,甚至还能对目标人物开展全方位背景调查。现在的表格,只需要描述清楚它需要什么;而剩下的脏活累活,智能体会逐行替它搞定。
🗑️ 静态新手引导、FAQ 与帮助文档 → 场景感知型 AI 实时支持(Contextual AI Support)
为什么传统模式正在失效?过去风靡一时的产品功能导览、气泡提示(Tooltips)流以及遮罩式新手教程,都存在一个致命的假设:它们认为所有用户在同一时间,都需要同一套一成不变的开场白。而那些把帮助中心做成静态文章库的模式,则傲慢地假设用户能自行将眼前的具体问题,拆解并归类到某个标准的文档分类中,然后耐着性子读完一篇通用的文章,再照猫画虎地套用到自己的场景里。但绝大多数用户根本做不到——因为用户向你描述的往往是表面症状,而不是系统的架构逻辑。
静态的 FAQ 回答的只是文档作者自己凭空想象出的问题。而场景感知型 AI 支持(Contextual AI Support)回答的,则是用户在当前特定账户状态、报错上下文以及历史操作路径下,真正遭遇的燃眉之急。在这个范式下,帮助中心正在发生退化:它正成为 AI 的训练语料库——一个退居幕后的“知识库后端”,而不再是供用户直接访问的前台目的地。
典型反面教材:Attio 的迷宫文档与 Notion 的刻板清单。Attio 的支持界面是一个典型的科层制文档树:参考指南 → 数据管理 → 列表管理 → 批量更新列表与视图。用户必须在侧边栏一重重嵌套分类里艰难穿梭,才能勉强找到一篇关于 “CSV 导入” 和 “条目 ID” 的文章。Notion 的首次使用体验则是一个生硬的打卡清单:“点击下方任意位置并输入 /”、“输入 /page 以添加新页面”、“通过侧边栏查找、组织并添加新页面”。这两者都在特定的刻板时间点,向用户硬塞了一套一刀切的通用指令。清单根本不知道用户此刻到底想搭建什么业务系统,文档文章也完全不了解用户刚刚操作了什么,又为什么会失败。
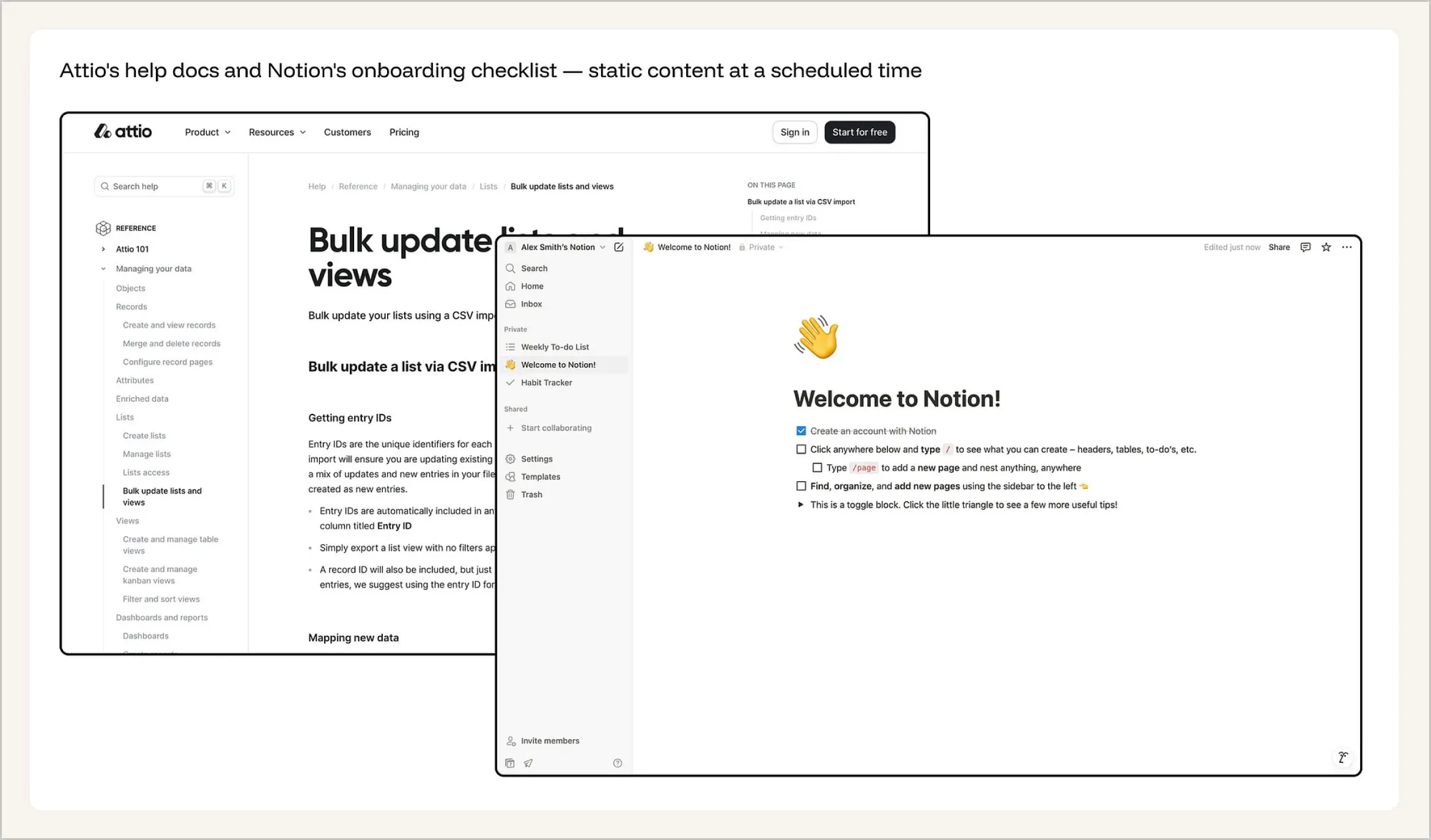
取而代之的是什么?一个能完美感知并融合用户当前特定状态的对话式 AI 实时支持系统。它清晰地知晓你正停留在哪一个页面、刚刚触发了哪条报错信息、当前处于哪种付费订阅级别,甚至在你开口提问之前,它就已经复盘了你之前所有的尝试路径。系统会敏锐地捕捉你的即时行为,并只在当下给出真正有用的解法,而不是硬塞给你一堆“以后可能用得着”的废话。这种讲解甚至会根据用户的熟练度进行动态自适应——随着你对产品越来越精通,AI 的提示就会变得越来越克制和精炼。在这种设计下,人工客服不再是兜底的默认路径,而是变成了一种经过精心设计的降级回退机制(Fallback mechanism)——只有当 AI 的置信度低于特定阈值时,才会启动人工介入。至于 FAQ,它的存在仅仅是为了喂饱 AI 的语料库,而不是留给用户去翻阅的。
全新的多模态交互:三大输入模式。系统提供了语音(Talk)、摄像头(Webcam)以及屏幕共享(Share Screen)三种输入模式。点击“屏幕共享”,AI 就能瞬间拥有与你完全同步的上帝视角——无论是你的 IDE 代码编辑器、电子表格,还是设计工具。你只需对着麦克风把遇到的麻烦说出来,就能立刻获得口头上的、场景感知型的实时引导。整个过程无需敲击键盘、无需漫无目的地搜索,更无需在帮助中心里兜圈子。不可否认,“屏幕共享级”的 AI 助手目前在具体产品中的落地率还不高——高昂的算力成本、延迟(Latency)问题以及隐私合规的红线,使得这种能力目前更多停留在基础设施或底层平台层面(如系统的原生 AI 能力),而未能广泛内嵌进各个独立 App 中。但这种前沿范式已经为“场景感知型支持”指明了终极演进方向:一个能够实时“看见”你当前上下文的 AI,永远不需要干等着你去费尽心机地描述它。
🗑️ 传统通知中心信息流 → AI 编排式决策看板(AI-Curated Decision Surfaces)
为什么传统模式正在失效?传统通知往往扮演着“拍拍用户肩膀、强行索要注意力”的角色,这种机制本质上是为信息匮乏时代设计的——即当时一款软件一天顶多也就发生几次重要事件。而如今,一个用户每天可能在几十款产品中被轰炸数百次。过去那种单纯追求数量的通知思维(认为“消息推送越多,用户活跃度/Engagement 就越高”)已经彻底失效并走向了反面:今天,一条能干掉十条低价值信息的优质通知,才是真正的好设计。
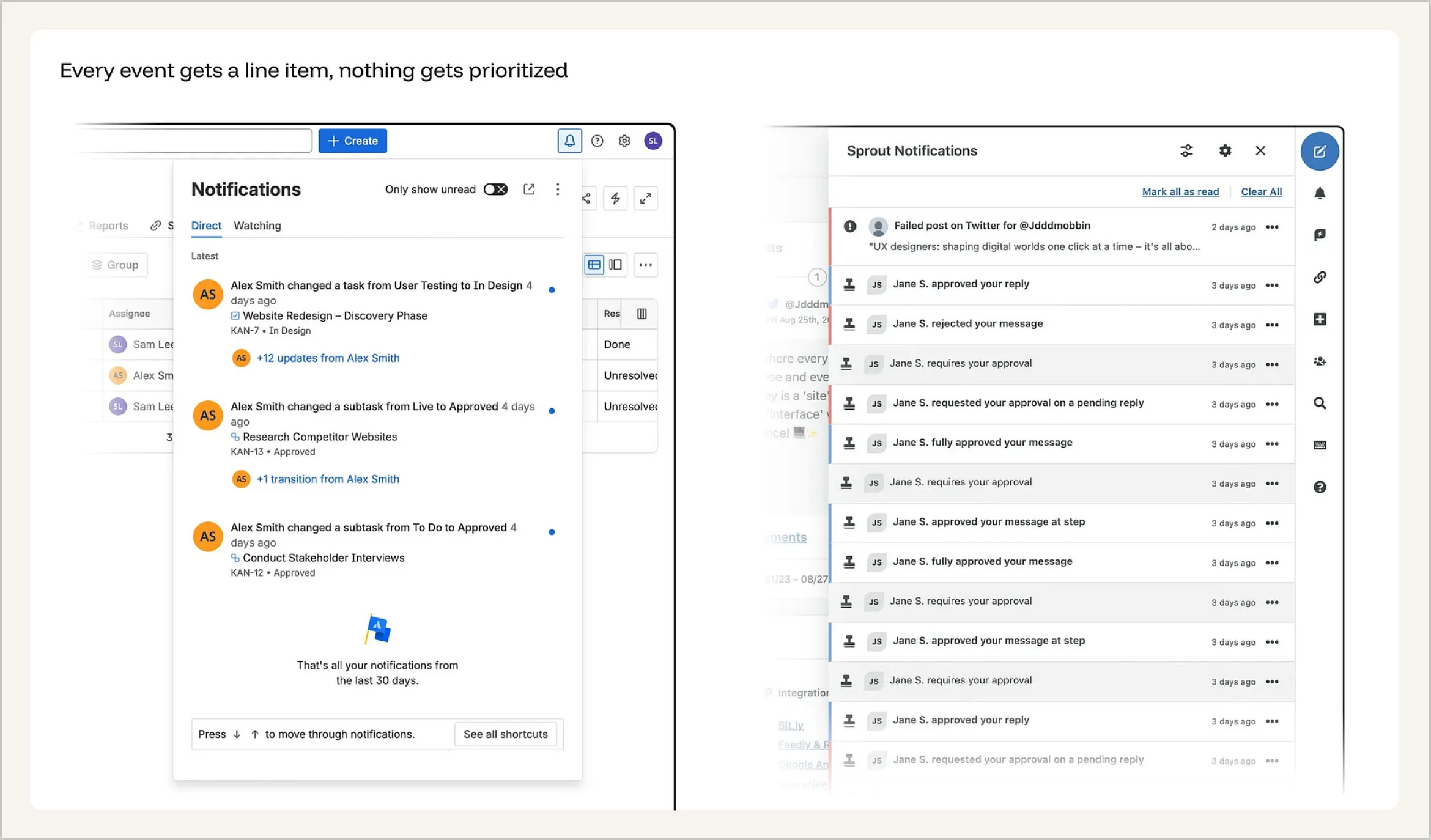
传统模式的核心败笔在于:将所有事件视为同等重要。 团队成员给你的评论点了个赞,居然和生产环境系统崩溃(Production down)拥有完全一样的视觉权重。用户被迫成了那个肉眼筛选信息的“人肉过滤器”——在永无止境的浏览和消除中,真正重要的信息反而被漏掉了。
典型反面教材:Jira 的流水账与 Sprout Social 的视觉轰炸。Jira 的设计将每一次任务更新都作为一条独立的流水账信息平铺直叙。Sprout Social 的通知中心则一口气展示了来自同一个人的 14 条几乎一模一样的通知——审批通过、驳回、回复,全都拥有等同的视觉权重。发帖失败这种故障和例行的日常审批看起来毫无区别。用户不得不硬着头皮滑完所有内容,去沙里淘金般地寻找真正需要处理的事项。
取而代之的是什么?AI 转换角色,化身为一个智能分诊层(Triage layer):它会基于当前上下文、紧急程度、与用户当前活跃目标的关联性以及当前状态,来综合研判究竟哪些事情才配得上“打扰用户”。低优先级的更新会被自动打包并收纳进结构化的摘要简报(Digests)中;而高优先级的突发事件则会以一种“上下文极其充沛”的姿态被推送升级,确保用户能够立即采取行动。它不再是过去那种冷冰冰的“有事发生”,而是清晰地告诉你:“发生了什么、为什么这很重要,以及你应该怎么做。”至此,通知中心已经彻底蜕变,它变成了一个高效的决策看板,而不再是一条被动接受的告警洪流(Alert stream)。
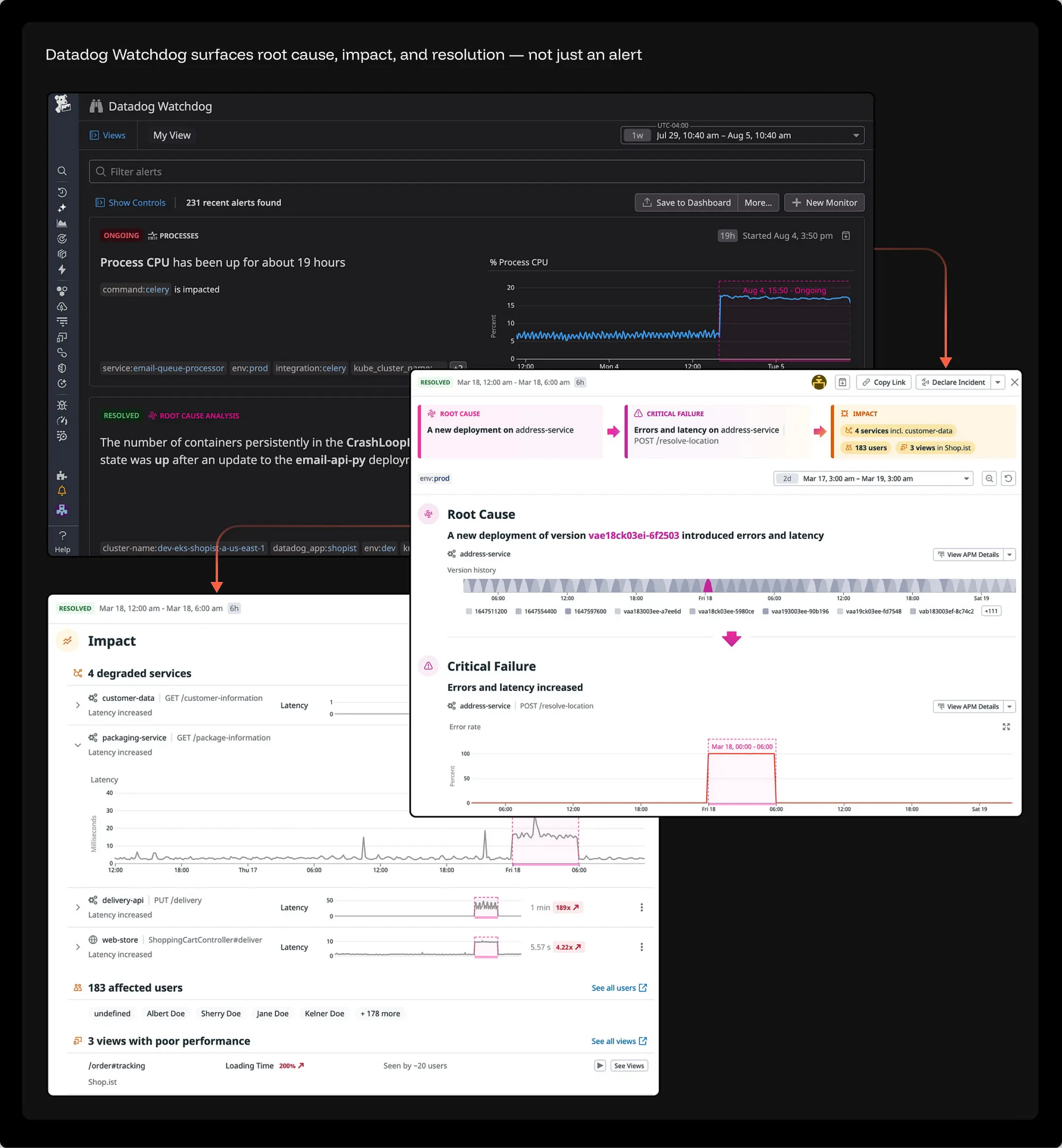
典型正面案例:Watchdog 的“因果链式”主动防御。Watchdog 将一次突发故障以极其清晰的“因果链(Causal chain)”结构呈现出来:底层根因(Root Cause) → 核心故障(Critical Failure) → 业务影响(Impact)。某次代码部署(Deployment)导致某个 API 端点(Endpoint)崩溃;进而引发 4 个核心服务发生降级;最终导致 183 位用户受到实质影响。运维工程师在不翻阅任何一条冗长告警列表的情况下,就能一眼看清事情的来龙去脉、底层诱因以及灾难的严重程度。
♻️ 传统的“新建”按钮 → 生成 / 建议 / 续写工作流(Generate / Suggest / Continue Flows)
为什么传统模式正在失效?“新建文档”、“新建幻灯片”或“新建项目”这类按钮,本质上是在把用户直接扔进一个“零状态(Zero state)”。它傲慢地假设所有的创作都必须从虚无中开始——面对一块惨白的画布、一个不断闪烁的输入光标,或是一张空空如也的电子表格。这种默认机制只讨好了那些对目标极度明确的“专家级用户”,却惩罚了绝大多数普通用户,让他们瞬间陷入“空白画布恐惧症(Blank-canvas paralysis)”。
取而代之的是什么?一种由意图驱动、而非从零开始的“生成 / 建议 / 续写”流。用户只需描述他们想要什么——可以是一个主题、一个核心目标、一份参考资料,或者是一个限制条件——系统就会立刻生成一份初稿供用户查阅与调整。至此,“内容创作(Creation)”正式蜕变为了“内容精选(Curation)”:用户的第一个创造性动作不再是“从无到有地死磕(Origination)”,而是“基于既有成果做出反馈(Reaction)”。这一交互范式的颠覆,正席卷所有的创作界面:从文档、演示文稿、图片、邮件,到代码、电子表格乃至整个业务工作流。
这场变革并非一蹴而就的开关,而是一场长期的迁徙
任何传统的设计模式都不会在一夜之间销声匿迹。Zillow 依然保留着它的侧边栏筛选器;PowerPoint 依然保留着新建空白幻灯片的入口;HubSpot 也依旧保留着那长达 7 步的报价引导向导。而它们本就该被保留——因为并不是每个用户都能随时用上 AI 功能,不是每个业务场景都跨过了对 AI 的信任阈值(Trust threshold),更不是所有的长尾边缘情况(Edge cases)都能被机器完美覆盖。
这场变革不是非此即彼的硬切换(Switch),而是一场春风化雨的长期迁徙(Migration)。
传统的交互模式正从“默认主入口”退居为“降级兜底方案”;而 AI 交互模式正从“极客实验性功能”晋升为“核心主路径”。作为一名产品设计师,你当下最核心的职责就是去审视并拍板:你产品中的每一个页面,在当下的光谱中究竟处于什么位置?而六个月后,它又应该演进到什么位置?
最终能够存活下来的界面,一定是那些能够让人类的决策判断变得更强大的界面,而不是那些依然要求人类去模拟计算机运转逻辑的界面。
从“执行导向型 UI(Execution UI)” 迈向 “决策裁判型 UI(Judgment UI)”
“执行”与“决策”之间的这道分水岭,是我们在做产品矩阵复盘时,用来决定哪些页面该倾注资源砸体验、哪些该精简瘦身,而哪些又该直接无情淘汰时,最立竿见影的设计启发式原则(Heuristic)。
🛠️ 执行导向型 UI(Execution UI)
专为协助人类完成确定性工作(Deterministic work)而设计的界面。例如:手动录入数据、配置繁琐的规则、按部就班地走完流程、以及执行各种高重复性的日常操作。
🟠 正在萎缩:随着 AI 逐渐接管并自动化所有的执行流,这类界面正在彻底失去其存在的生态位与底层支撑。
⚖️ 决策裁判型 UI(Judgment UI)
专为协助人类去评估、引导并纠正机器产出结果而设计的界面。例如:审查 AI 提取的输出成果、确认批量数据的变更、理解大模型的推理逻辑(Reasoning),以及在出现系统异动时进行人工介入干预。
🟢 正在爆发:随着 AI 接管越来越多高自主性的工作,人类迫切需要更优雅、更强大的界面来充当“机器的超级监护人”。
本文最初发表于我的 Substack 专栏《Syntax Stream》,在这本刊物中,我长期致力于探讨人机交互(Human-AI Interaction)的核心本质与设计原则。
原文链接:
10 UI patterns that won’t survive the AI shift
https://uxdesign.cc/10-ui-patterns-that-wont-survive-the-ai-shift-002cb9b853ae
既然来了,说些什么?