OFF.42 2026 与 OpenClaw

年前的这期文章,原本是想写一写过去 2025 年的一些思考。就在我整理的时候,OpenClaw 突然火了。
其实一直都想买一台 Mac mini,但一直没给自己找到一个合适的理由,否则买回来也吃灰。这次终于有了,于是赶在涨价之前火速抢了一台国补。
接下来的五天,基本上什么都没干,全耗在 OpenClaw 上了。不断地调试、重新部署,踩了各种坑,填了各种坑。好在最终还是把它跑了起来,也开始慢慢让它云钻起来,干一些活了。
也正是在这个过程中,我突然意识到之前准备的那篇 2025 总结,有很多内容变得没什么意义了。或者说,OpenClaw 的出现,让我重新审视了一些原本觉得还挺重要的问题,发现它们在 OpenClaw 开启的这个新的阶段下需要被重新思考了。
所以,我删掉了那些内容,准备重新来过。这期的文章,我想就聊聊在在使用了 OpenClaw 一周后的一些思考吧。
OpenClaw 的出现意味着什么
在我看来,OpenClaw 的出现至少代表了三件事。
第一,AI Agent 从概念走向了具象。
在此之前,Agent 这个词更多还是停留在技术圈的讨论里,大家知道有这么个东西,但它到底长什么样、能干什么,说实话还是模糊的。
而 OpenClaw 的出圈,则是让普通人第一次真正看到了一个 AI 开始能够操作自己的电脑上浏览信息、读写文件、改配置、写程序。这种可见的执行,才是让大家对 Agent 产生真实认知的转折点。也真正感受到了 AI 的“可怕”。
第二,AI 从「能说」到「能做」的跨越。
如今的大模型,无论是 ChatGPT、Gemini 还是 Claude,本质上都是在告诉你怎么做。它们可以给你一份详尽的方案,但方案写完,活还是得你自己干。
而 OpenClaw 则不一样,它不光能和你聊,还可以直接替你去做。去操作 API、执行命令行、读取本地文档,真正具备了改变现实世界的能力。
第三,一种新的人机协作结构的雏形开始出现。这一点,可能是最值得我们关注的,后面会展开来聊。
01. 拥有了手和脚
OpenClaw 之所以能让 agent 这个概念变成一种真实的体感,最直接的原因就是它终于有了手和脚。
ChatGPT、Gemini 这些大模型,再聪明也只是在对话框里和你聊天。你问它怎么修改一个配置文件,它会一步步告诉你,但最终还是你自己打开终端去敲命令。它能分析推理,也能给你给建议,但它不能去修改你电脑上的任何东西。
而 OpenClaw (本地部署)则是真正拥有了一台电脑的完整控制权。操作 API、执行命令行、读取你各类账号里的信息和本地文档。它不仅能说,而且能做。
02. 自主感知能力
OpenClaw 它让 agent 具备了自主感知的能力。无论是大模型还是 copilot,它们都是被动触发的。你不和它说话,它就不工作。
而 OpenClaw 它的行为可以是主动的。当它监听到 API 的变化、本地文件的更新、甚至是时间条件的触发,它可以主动发起行动。交给它一个任务,它会真正像人一样去执行、检查结果、发现问题、反思调整、再继续推进下一个。
这才是 AI 协作这件事真正成立的前提。不是你时刻盯着它、喂给它指令,而是你交代一件事,它自己能判断什么时候该动、怎么动、动完之后该做什么。
03. 结构化认知
注:以下内容中出现的 .md 代表的是 markdown 文档,不是网站链接
前面的两点,说的都是能力层面的突破,不仅是能动手了,而且是能主动了。但这次真正有意思的是它在认知层面的底层结构。
Soul.md :Agent 的自我认知。
与大模型的对话,很多时候需要我们用 prompt 来让它进入某个角色,提升对话的质量和效率。
而 OpenClaw 则是通过 soul.md 构建了一个固定的自我价值观和行为准则。无论是否跨 session,无论何时唤起,它都会保持同样的、稳定的认知。它知道自己是谁,该怎么与用户沟通。
User.md :Agent 对用户的理解。
如今的大模型产品虽然也提供了一些初始设定的能力,但它们大多局限在某个项目或某段对话中。换一个场景,它可能又不认识你了。
而 user.md 是跨任务、跨session持续生效的。无论你让它做什么,它对你的理解是一致且连续的。它知道你是谁,也知道你的风格和喜好,能够让我们的沟通更加聚焦和有效。
Skill.md :Agent 的能力边界。
大模型如今也在通过 MCP 协议来不断扩展自己的能力,但本质上它还是得依赖的是外部服务的支持。只有对方开放了,大模型接入了,我们才能才大模型里用到,所以这块的生态还是比较分裂和缓慢的。
而 OpenClaw 的 skill 则是基于本地系统自主构建的。你可以根据自己的需求,来让它用命令行完成某件事、用浏览器操作某个页面、用脚本处理某类文件。
它不需要等外部产品来适配,能力边界不取决于生态,而取决于对方提供的 API 以及你自己的需求。只要把要求告诉它,它就能帮你实现。
Memory.md :Agent 连续的记忆。
大模型最让人头疼的问题就是上下文超载后的”失忆”,跨对话更是很多信息都丢失。
而 memory.md 可以让 Agent 记住所有的上下文中的重要信息。知道昨天有个脚本报错了是怎么修复的,也知道某个任务还在等待继续推进。它知道自己做过什么,也知道用户要它不要干什么。
所以,OpenClaw 通过我是谁(soul.md)、你是谁(user.md)、skill.md(能做什么、怎么做)以及做过什么(memory.md)四个markdown 文件很好的支撑了一个具备独立自主能力的 AI Agent。
它也不再是一个用完就关掉的工具,而是一个可以跟你长期持续协作的伙伴了。
新的协作关系的出现
理解了 OpenClaw,我们就不得不再进一步思考一个问题。
Agent 的出现,会如何改变我们和 AI 之间的关系?
过去两三年,关于如何与 AI 协作(共处)的讨论其实一直没断过。但那时候的讨论没有那么多的紧迫感。原因其实也很简单,大模型再强,它也被困在浏览器的对话框里。它能帮你想,但不能替你干。威胁是理论上的,冲击似乎还没那么快、那么强。
但 OpenClaw 不一样。当你亲眼看到一个 AI 在你的电脑上独立完成了一整套工作流程的时候,这个问题就不再是一个被简单讨论的话题了,而是一个我们必须正面面对的现实。
在我看来,讨论这个问题我们首先需要确定核心的主体是谁。如果从一个最小的独立个体角度来看,我会认为有三个,分别是 AI 大模型、AI Agent 以及我们自己。
在 Agent 真正出现之前,从思考认知,到信息获取,到任务执行,再到最终的决策,所有环节都是由我们自己来完成的。而 Agent 真正出现之后,我们不得不把其中的一部分”权力”让渡出去。
但让渡不是全部交出去,而是一种重新分工。
思考和认知这件事,是由我们和大模型共同来完成。我们提出问题、给出方向,然后由大模型来帮我们拓展视角、推演可能性、以及填补知识盲区。而这,是一种双向的、共生的过程。
而信息的获取和任务的执行,则完全可以交给 Agent 来接手。它们不需要理解我们为什么要做这件事,只需要知道做什么、怎么做,然后高效地完成,就可以了。
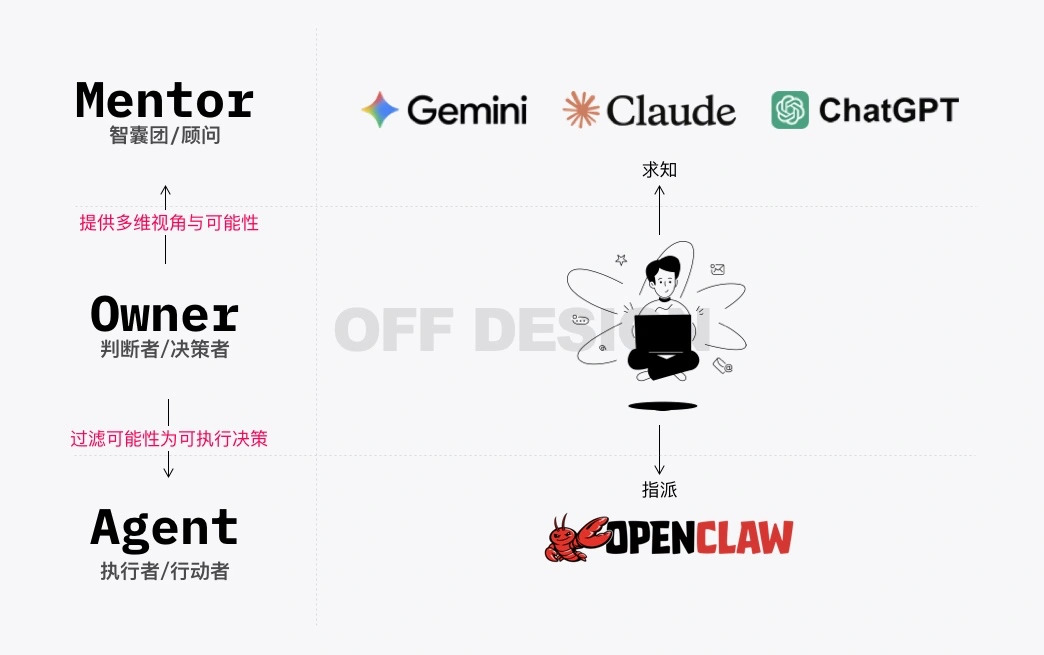
01. 顶层是 Mentor
Gemini、ChatGPT、Claude 这些大模型扮演的角色,更像是我们的顾问或智囊。它们的任务是提供多维度的视角、推演可能的结果、帮我们来看到自己看不到的东西。你可以把它理解为一个随时在线、知识面极广的参谋团。
02. 中层是 Owner
也就是我们自己。我们的核心职责是判断和收敛。大模型可能会给我们一百种可能性,但最终拍板做哪一个、不做哪一个,这个决定只能由我们来做。
把更多的可能性砍成一到两个可执行的决策,这是我们在这个系统中最核心的价值。
03. 底层是 Agent
OpenClaw 这一类的角色,就是高执行力、高质量、零情绪的执行者。只要指令足够清晰,它们可以 24 小时不间断地工作。你想好了要做什么,它们帮你把想法变成具体的文档、代码或功能。
大家可能注意到了,在这个结构里,我认为我们依然保留着决策的权力,也必须保留这个权力。当日,者这并不是因为我们比 AI 更聪明。
事实上,在知识密度和速度上,AI 已经远远超过了我们。但有一件事它做不到。那就是它没有对物理世界的真实感知,它不知道我们的痛点是什么,不理解我们此刻的情绪,所以无法体会一个决定对你的生活意味着什么。
新协作关系中的系统瓶颈
如果搭建已经尝试过 OpenClaw,应该就会感受到,在这套新的协作关系里,跑得最慢的那个环节,其实是我们自己。
Agent 执行任务所需要的时间相较于我们人类夸张一点来说可以算是忽略不计了。
给它一个明确的指令,它可以很快的完成部署、生成文档、跑完一整套流程。大模型的响应同样很快,你抛出一个问题,几秒钟内就能拿到多个维度的分析和建议。
而我们,则需要更多的时间去消化这些信息。权衡利弊,做出判断。在整个系统中,人类的思考速度显然就是最明显的瓶颈,拖累了整体的运转效率。
这个会很糟糕吗?我觉得不一定。至少在我目前的认知中,这反而是一件好事。
在一个算力杠杆几乎无限的时代,想清楚要比做得快更为重要。一个没想清楚就执行的决定,Agent 跑得越快,错得也越远。
如果这么来看,这个「瓶颈」本质上就不是一个效率问题,而是一个战略上的过滤器。
在这个新的生产关系里,三个角色各自承担着不同的职能。大模型作为 Mentor,它的天然就是发散的。问它一个问题,它可能会给你一百种可能性、十个方向、五套方案。它在不断地为整个系统提供熵增。
而我们作为 Owner,站在这个系统的中间,最核心的工作就是收敛。结合我们自己对业务的理解、对现实约束的判断,把这一百种可能性砍成一到两个最终的决定。这个过程会看上去有点慢,但它决定了后面所有事情的方向。
Agent 的角色则是快速放大。一旦我们找到方向、做出决定,它可以用最短的时间帮我们把这个想法和判断实现,交付出具体的文档、代码或者功能。
发散、收敛、放大。这就是当前这套协作关系的基本运转逻辑。而我们,恰好站在最关键的那个位置上。虽然看上去是慢,但却是非常有必要的。
所以,如今很多人因为那些整理好的600个、700个 skill 而焦虑,这个想法是很有问题的。好像今天不全装上自己就跟不上发展的节奏了。
但事实上,skill 会爆发式的极速增长,OpenClaw 自己也能写,无论花多少时间我们也跟不上速度。更重要的是,这些 skills 只是在解决它能干什么,但是解决不了要干什么、怎么干。
写在最后
这段时间 OpenClaw 的信息密度极高。即使你什么都不干,全天只关注它,你也会发现根本看不完。不断更新的保姆级教程、层出不穷的 skill、各种搭配大模型的选择,再叠加上配置过程中踩的各种坑,整件事变得极其复杂。
但越是这个时候,我们越需要跳出现象去看本质。去想清楚 Agent 和我们之间到底是什么关系。
前面聊的是我自己协作关系的一些思考。它一定带有主观性,但我认为是一个值得参考的视角。大家可以结合自己的情况,顺着这个方向想想。
最后,要不要尝试 OpenClaw?
我的回答是,值得尝试。但前提是你有时间,并且懂一点点技术逻辑。不一定是要会写代码,但至少对操作系统、命令行这些东西有一定的概念。
如果你决定试一试,有几点建议:
如果你对技术不太熟悉但又很想体验,建议先买一个云端服务做一键部署。能省掉大量配置环节的折腾,先把东西跑起来,感受一下它能做什么,再决定要不要深入。
如果你想体验完整的 OpenClaw,还是需要本地部署。但我强烈建议用一台独立的设备来安装,不要直接装在你的主力机上。
另外,无论是云端还是本地,都建议给它配置独立的账号。Apple ID、Google 账号,全部单独注册。做到风险的绝对隔离。这一点非常重要,千万别偷懒。
最后,提前祝大家新年快乐,我们明年再见!
🧨
来都来了,说些什么?